Za mną już znacznie ponad 20 mięsistych, wyczerpujących wpisów. Wciąż jednak brakuje fundamentalnego “Co to jest Big Data?”. Na to pytanie można odpowiadać godzinami. Dziś chciałbym jednak spojrzeć z biznesowej perspektywy. Nie będzie zbyt wielu technikaliów. Nie będziemy rozważać ile executorów powinno się ustawiać w spark-submit, ani czym różni się HBase od Accumulo. Ten artykuł przeznaczony jest dla osób zarządzających. Dla tych, którzy chcą pchnąć firmę na wyższy poziom i zastanawiają się, co to jest ta Big Data. Kubek z kawą na biurko… i ruszamy!
Jak to się zaczęło?
Zanim przejdziemy do samego sedna, bardzo istotna jest jedna rzecz: Big Data to naprawdę duża, złożona działka. Ciężko opisać ją w kilku punktach. Żeby ją zrozumieć, trzeba podejść z w kilku różnych kontekstach. Zacznijmy od krótkiej historii początków. Dzięki temu prawdopodobnie nie tylko zrozumiemy kontekst, ale i kilka cech charakterystycznych tej branży – co przyda się w podejmowanych decyzjach biznesowych.
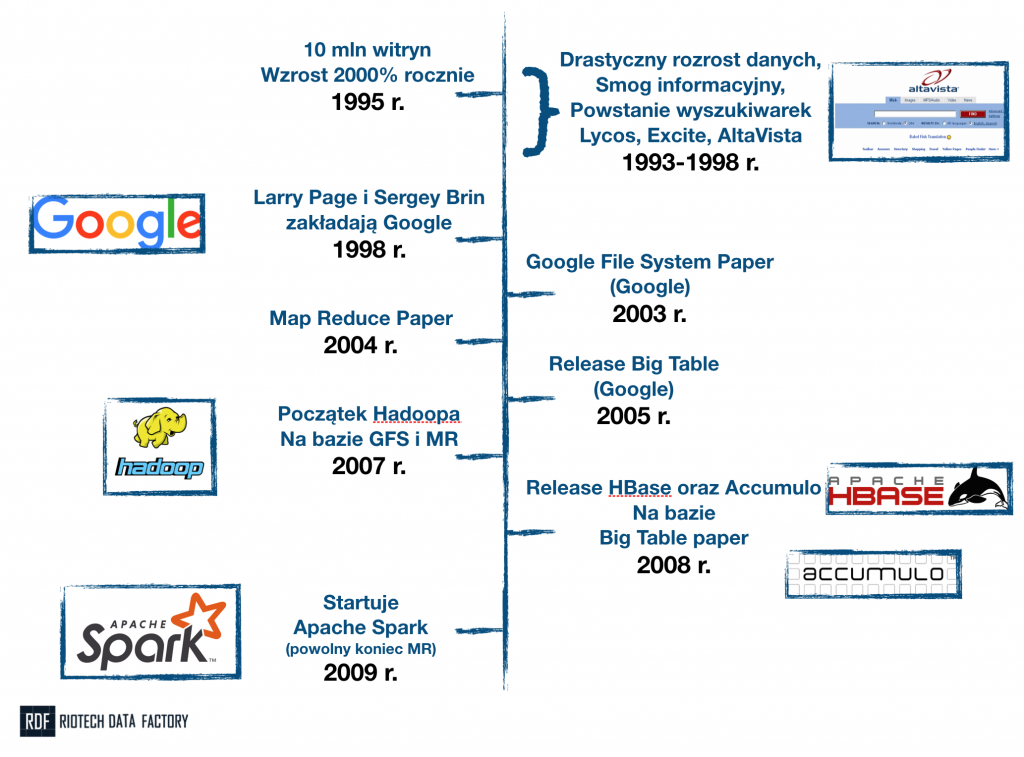
Jak to często bywa z historią, początki są niejasne i każdy może mieć troszkę swoją własną teorię. Moim zdaniem jednak, definitywny początek Big Data ma… w Google. Tak – znana nam wszystkim korporacja (i wyszukiwarka) jest absolutnie najbardziej zasłużoną organizacją dla tej branży. Niezależnie od rozmaitych swoich grzeszków;-). Ale spójrzmy jeszcze wcześniej – do roku 1995. To wtedy Internet przybiera na sile. Jego rozmiary są nie do końca znana, natomiast sięga już przynajmniej 10 mln witryn. Co “gorsza”… rozwija się w tempie 2000% rocznie.

Chaos Internetowy lat 90′
Kluczową dla funkcjonowania Internetu rzeczą, są wyszukiwarki. Dziś to dla nas rzecz oczywista, ale w 95′ wcale tak nie było. Jeśli jednak nie będzie wyszukiwarek, nie znajdziemy znakomitej większości rzeczy, których potrzebujemy. Problem polega na tym, że wyszukiwarki nie przeszukują całego internetu za każdym razem. One zapisują strony (w odpowiedniej strukturze, niekoniecznie całe strony) w swoich bazach danych. Następnie przeszukują te bazy, kiedy użytkownik przekaże zapytanie.
Wniosek jest oczywisty: wyszukiwarki to nie nudne “lupki”, a bardzo zaawansowana technologicznie maszyneria. Maszyneria, która potrzebuje dożo miejsca na dysku, dużo pamięci podręcznej oraz mocy obliczeniowej. Jak bardzo, przekonali się o tym Larry Page i Sergey Brin, którzy w 1998 roku zakładają Google. Z czasem bardzo szybko orientują się, że przyrost danych jest zbyt ogromny na jakikolwiek komputer.
I tutaj pojawia nam się pierwsza, najważniejsza (moim zdaniem) zasada, charakterystyka Big Data. Inżynierowie sporej już wtedy firmy, rozpoczęli prace nad technologią, która pozwoli przechowywać oraz przetwarzać bardzo duże dane (których jest więcej i więcej i więcej…). Ci jednak, zamiast skonstruować olbrzymi super-komputer, którym zaimponują światu, poszli w zupełnie inną stronę. Uznali, że i tak prędzej czy później (a raczej prędzej) skończy im się miejsce i moc obliczeniowa. Co wtedy, nowy super-komputer? No właśnie nie.
Podejście rozproszone (distributed)
Znacznie lepszym pomysłem będzie zbudowanie takiego oprogramowania, które pozwoli połączyć bardzo wiele komputerów. I korzystać z nich tak, jakbyśmy mieli jeden wielki komputer. Co kiedy skończą się możliwości? Cóż – po prostu dorzucimy kolejne mniejsze komputery do naszego ekosystemu. Takie podejście nazywa się podejściem “rozproszonym” (ang. distributed). Tak właśnie powstaje Google File System (GFS) oraz opublikowany zostaje Google File System Paper, na którym opisana jest architektura wynalazku. Rok i dwa lata później publikowane są kolejne przełomowe dokumenty: Map Reduce (MR) Paper (który opisuje technologię do przetwarzania danych) i Big Table Paper.
Czemu Google to fundament Big Data? Bo na wyżej wymienionych dokumentach powstają najbardziej fundamentalne technologie open-source. Fundacja Apache ogłasa w 2007 roku, że na bazie GFS oraz MR powstaje Hadoop – prawdopodobnie najbardziej znana technologia Big Data. Rok później, znów na bazie dokumentu Google (Big Table Paper) powstają dwie bazy danych: HBase oraz Accumulo.
Od tego momentu “każdy” może połączyć ze sobą kilka PCtów i zbudować swój klaster Big Data – czyli zestaw serwerów, które współpracują jak jeden duży komputer. Poniżej slajd z mojego wykładu “Big Data. Opowieść o gromadzeniu przeszłości i zarządzaniu przyszłością” który często jest wstępem do szkoleń. Więcej o Google i historii wyszukiwania pisałem w recenzji książki “Szukaj. Czyli jak Google i konkurencja wywołali biznesową i kulturową rewolucję?”.
Co to jest Big Data? Zasada 3V
Skoro wiemy już jak to się wszystko zaczęło, przejdźmy do podstawowego pytania: Co to tak naprawdę jest Big Data? Skonkretyzujmy to sobie nieco. Jesteśmy w IT, więc postarajmy się zdefiniować tą materię. Dawno temu wyznaczona została zasada, która określa czym jest Big Data. Zasada ta była później rozwijana, natomiast my przyjrzymy się pierwotnej wersji. Dodajmy – wersji, która moim zdaniem jest najlepsza, każda kolejna to już troszeczkę budowa sztuki dla sztuki;-).
Chodzi mianowicie o wytłuszczoną w nagłówku zasadę 3V. Określa ona cechy danych, które najmocniej charakteryzują Big Data.
- Volume (objętość) – najbardziej intuicyjna cecha. Wszyscy dobrze rozumiemy, że jak data mają być big, to muszą mieć “dużą masę”. Ile dokładnie, ciężko stwierdzić. Niektórzy mówią o dziesiątkach GB, inni dopiero o terabajtach danych.
- Velocity (prędkość) – to już nieco mniej oczywista rzecz. Moim zdaniem jednak bardzo istotna dla zrozumienia naszej materii. Wyobraź sobie, że śledzisz wypowiedzi potencjalnych klientów w mediach społecznościowych. W tym celu analizujesz wszystkie posty z określonymi tagami. Można się domyślić jak szybko przybywa tych danych (i jak bardzo często są one nie do użycia, ale to już inna sprawa). Tutaj właśnie objawia się drugie “V”. Wielokrotnie mamy do czynienia nie tylko z dużymi danymi, ale także z danymi które napływają lub zmieniają się niezwykle szybko. To ogromne wyzwanie. Znacząco różni się od stanu, w którym po prostu musimy przetworzyć paczkę statycznych, zawsze takich samych danych.
- Variety (różnorodność) – I ta cecha prawdopodobnie jest już zupełnie nieintuicyjna (w pierwszym odruchu). Dane które dostajemy bardzo często nie są pięknie ustrukturyzowane, ułożone, wraz z dostarczonymi schematami. Wręcz przeciwnie! To dane, które często są nieustrukturyzowane, w których panuje chaos. Dane, które nawet w ramach jednego zbioru są różne (np. wiadomości email). Są to wyzwania z którymi trzeba się mierzyć i do których zostały powołane odpowiednie technologie – technologie Big Data.
Big Data w biznesie – kiedy zdecydować się na budowanie kompetencji zespołu?
Skoro już wiemy jak to się zaczęło i czym to “dokładnie” jest, czas postawić to kluczowe pytanie. Przynajmniej kluczowe z Twojej perspektywy;-). Kiedy warto zdecydować się na budowanie kompetencji Big Data w zespole? Nie będę zgrywał jedynego słusznego mędrca. Ta branża jest skomplikowana niemal tak jak życie. Nie ma jednego zestawu wytycznych. Podzielę się jednak swoimi spostrzeżeniami.
Poniżej wymieniam 5 sytuacji, które mogą Ci się przydać. Bądźmy jednak szczerzy – to pewna generalizacja. Być może jednak całkiem przydatna;-).
Na horyzoncie pojawia się projekt, który nosi znamiona Big Data
Niezależnie od tego jaki jest charakter Twojej firmy, prace poukładane są w coś co nazwiemy “projektami”. Ten punkt sprawdzi się szczególnie wtedy, gdy outsourceujecie zasoby ludzkie lub robicie zlecaną przez innych robotę. W takiej sytuacji może na horyzoncie pojawić się projekt “legacy”, który ma kilka cech charakterystycznych:
- Wykorzystywane są technologie Big Data. Dokładniej na temat tego jakie technologie za co odpowiadają, znajdziesz tutaj. Miej jednak radar nastawiony przynajmniej na kilka z nich:
- Hadoop (w tym HDFS, Yarn, MapReduce (tych projektów nie bierz;-)).
- Hive, Impala, Pig
- Spark, Flink
- HBase, MongoDB, Cassandra
- Kafka,
- “Przerzucane” są duże ilości danych (powyżej kilkudziesięciu gigabajtów)
- Projekt bazuje na bardzo wielu różnych źródłach danych
- Projekt pracuje na średnich ilościach danych (dziesiątki gb), ale pracuje bardzo niewydajnie, działa wolno i sprawia przez to problemy.
I inne;-). Jeśli widzisz projekt, który na odległość pachnie zapychającymi się systemami, technologiami Big Data i różnorodnością danych – wiedz, że czas najwyższy na budowę zespołu z odpowiednimi możliwościami.
Projekt nad którym pracujecie, przerósł wasze oczekiwania
Wielokrotnie bywa tak, że mechanizmy zbudowane w ramach jakiegoś projektu są dobre. Szczególnie na początkowym etapie, kiedy danych nie ma jeszcze zbyt wielu. Potem jednak danych przybywa, źródeł przybywa i… funkcjonalności przybywa. Tylko technologie i zasoby pozostają te same. W takim momencie proste przetwarzanie danych w celu uzyskania raportów dziennych trwa na przykład 6 godzin. I wiele wskazuje na to, że będzie coraz gorzej.
Ważne, żeby podkreślić, że nie musi to być wina projektantów systemu. Czasami jednak trzeba dokonać pivotu i przepisać całość (albo część!) na nowy sposób pracy. Nie jest to idealny moment na rozpoczęcie wyposażania zespołu w kompetencję Big Data. Może to być jednak konieczne.

Zapada decyzja o poszerzeniu portfolio usługowego
Tu sprawa jest oczywista. Świadczycie usługi IT. Robicie już znakomite aplikacje webowe, mobilne, pracujecie w Javie, Angularze i Androidzie. Podejmujecie decyzję żeby poszerzyć portfolio o usługi w ramach Big Data. To nie będzie łatwe! Należy zbudować całą strukturę, która pozwoli odpowiednio wyceniać projekty, przejmować dziedziczony (legacy) kod czy projektować systemy. Trzeba się do tego przygotować.
Czy trzeba budować cały nowy dział od 0? Absolutnie nie – można bazować na już istniejących pracownikach, choć z całą pewnością przydałby się senior oraz architekt. Warto jednak pamiętać, że cały proces powinien rozpocząć się na wiele miesięcy przed planowanym startem publicznego oferowania usług Big Data.
Organizacja znacząco się rozrasta wewnętrznie
Bardzo często myślimy o przetwarzaniu dużych danych na potrzeby konkretnych projektów, produktów itd. Jednym słowem, zastanawiamy się nad dość “zewnętrznym” efektem końcowym. Musimy jednak pamiętać, że równie cennymi (a czasami najcenniejszymi) danymi i procesami, są te wewnętrzne. Big Data nie musi jedynie pomagać nam w wytworzeniu wartości końcowej. Równie dobrze możemy dzięki obsłudze dużych danych… zmniejszyć chaos w firmie. Nie trzeba chyba nikomu tłumaczyć jak zabójczy potrafi być chaos w organizacji. I jak łatwo powstaje.
Do danych wewnętrznych zaliczymy wszystko co jest “produktem ubocznym” funkcjonowania firmy. Na przykład dane dotyczące pracowników, projektów, ewaluacji itd. Także klientów, zamówień, stanów magazynowych. Jeśli uda nam się na to wszystko nałożyć dane geolokalizacyjne i garść informacji ze źródeł ogólnodostępnych, możemy zacząć budować sobie całkiem konkretne raporty dotyczące profili klientów. Gdy pozyskamy kilka wiader bajtów z serwisów promocyjnych i inteligentnie połączyć z resztą – możemy dowiedzieć się o racy firmy, klientach oraz nadchodzących okazjach znacznie więcej, niż wcześniej. I więcej, niż konkurencja;-).
Chmura czy własna infrastruktura? (Cloud vs On-Premise)
Gdy jesteśmy już świadomi branży Big Data oraz okoliczności, w jakich warto w nią wejść – zastanówmy się nad najbardziej fundamentalną rzeczą. Mowa o infrastrukturze komputerowej, którą będziemy wykorzystywać. Mówiąc bardzo prosto: nasze technologie muszą być gdzieś zainstalowane, a dane gdzieś przechowywane. Pytanie zwykle dotyczy wyboru między dwoma ścieżkami: albo będziemy mieli swoją własną infrastrukturę, albo wykorzystamy gotowych dostawców chmurowych.
Które podejście jest lepsze? Odpowiedź jest oczywista: to zależy. Nie ma jednego najlepszego podejścia. To przed czym chcę Cię w tym miejscu przestrzec, to przed owczym pędem w kierunku chmur. Zwykło się myśleć, że aplikacja działająca w chmurze, to aplikacja innowacyjna, nowoczesna, lepsza. To oczywiście nie jest prawda.

Czym jest Cloud a czym On-premise
Żeby w ogóle wiedzieć o czym mówimy, zacznijmy od uproszczonego wyjaśnienia, które jakoś nas ukierunkuje.
- Własna infrastruktura (On-Premise, często skrótowo po prostu „on-prem”) – komputery, które fizycznie do nas należą, są przechowywane gdzieś „na naszym terytorium”. Samodzielnie łączymy je siecią, instalujemy tam odpowiednie oprogramowanie, synchronizujemy itd. Specjalnie do tego typu infrastruktury stworzona została m.in. popularna platforma Big Data Apache Hadoop. Stawiając on-premise musimy zadbać o samodzielną obsługę całości, natomiast koszt związany z zasobami jest „jednorazowy” w momencie zakupu sprzętu (potem oczywiście jeśli chcemy ją rozbudować).
- Chmura (Cloud) – czyli instalacja odpowiedniego oprogramowania na komputerach (serwerach) udostępnionych przez zewnętrzną firmę. Taka firma (np. Microsoft ze swoją chmurą Azure) ma centra danych (data center) w różnych miejscach na świecie. Komputery te są ze sobą powiązane odpowiednimi sieciami i zabezpieczeniami. Szczegóły technologiczne na ten moment sobie darujmy (prawda jest taka, że to na tyle złożone tematy, że… z poszczególnych chmur (np. Azure czy AWS) robi się powszechnie uznawane certyfikaty – sam zresztą nawet jednym dysponuję;-)). Za chwilę odrobinę dokładniej opowiemy sobie jakie mamy dostępne możliwości wykorzystując chmurę. Teraz jednak to co trzeba zrozumieć, to że rezygnujemy z ręcznej obsługi zasobów. Oddajemy całość administracyjną fachowcom z konkretnej firmy. Gdy korzystamy z takich usług, nie wiemy na jakim dokładnie komputerze (komputerach, bardzo wielu) lądują nasze dane. Tak więc sporo „zabawy” nam odchodzi. Oczywiście coś za coś, natomiast o plusach i minusach porozmawiamy za chwilę.
Teraz wypadałoby podpowiedzieć jakie dokładnie są różnice. A jest ich dużo. Od przewidywalności, przez koszty (kilka ich rodzajów), kwestie prywatności danych, łatwość skalowalności aż po terytorialność danych. W tym miejscu chciałbym odnieść do moich dwóch artykułów:
- W tym artykule daję takie proste zestawienie różnych aspektów. Zajmie Ci to chwilkę, a będzie bardzo dobrym punktem startowym.
- Drugi artykuł jest dla ambitnych. Poruszam tam kwestie, które zazwyczaj nie są poruszane. Jest to pogłębiona analiza zagadnienia “Cloud vs On-prem”.
Jak zacząć budowę zespołu z kompetencjami Big Data?
Oto najważniejsze być może pytanie. Napiszę na ten temat osobny artykuł. Tutaj zerknijmy jednak skrótowo na temat, który jest niezwykle istotny, a wręcz powiedzmy sobie – kluczowy. Moment zainwestowania w kompetencje może być wybrany lepiej lub gorzej, ale źle zbudowany zespół będzie się mścić przez lata. Oznacza źle zaprojektowane systemy, źle napisany kod, a to – w efekcie – projekty, które po latach trzeba będzie wyrzucić do śmieci lub napisać od początku. A można uniknąć tego wszystkiego robiąc cały proces tak, aby miał ręce i nogi;-).
Znów – nie chcę rościć sobie praw do wyznaczania jedynie słusznej ścieżki rozwoju. Zaproponuję jednak kilka punktów, które mogą nakierować myślenie na metodyczne podejście, które w perspektywie się opłaci.
Po pierwsze – przygotujmy się
Nie róbmy wszystkiego na łapu capu. Trzeba mieś pewną wiedzę, która zaczyna się w kadrze menedżerskiej. Bez tego będziemy przepalać pieniądze. Niech menedżerowie nie oddzielają się grubym murem od technicznych. Zdobycie podstawowych informacji nie będzie techniką rakietową, a pozwoli podejmować lepsze decyzje.
W jaką wiedzę się uzbroić? (przykład)
- Zbudowanie zespołu kosztuje. To podstawa, z którą warto się oswoić. Inżynierowie Big Data są drogimi specjalistami, szkolenie i doradztwo jest drogie. Prawdopodobnie cały proces nie zamknie się w kilkudziesięciu tysiącach złotych, choć kosztorys to zawsze bardzo indywidualna sprawa.
- Jakie są dokładnie powody budowy zespołu z kompetencjami Big Data? To bardzo istotne, bo będzie wymuszało różny start, datę, technologie itd. Omawialiśmy to trochę wyżej.
- Kiedy Chcemy wystartować?
- Na jakim zespole bazujemy? Czy na jakimkolwiek?
- Jakie są generalne technologie Big Data? Nie chodzi o szczegóły, ale o ogólne rozeznanie się w tym co istnieje na rynku.
- Jaki jest nasz dokładny plan działania? Taka road-mapa powinna być przedyskutowana z początkowym zespołem, aby ludzie Ci mieli świadomość w którym kierunku idą.
- Czy potrzebujemy infrastruktury? Być może nie, ale prawdopodobnie jednak na czymś trzeba będzie bazować.
Po drugie – wyznaczmy zespół
Zespół może być tworzony od zera, może być zrekrutowany. Bardzo prawdopodobne, że uda się zrobić opcję hybrydową, czyli wyszkolić kilku specjalistów do początkowego etapu, a zrekrutować seniora, który tym pokieruje.
Jeśli bazujemy na ludziach którzy już pracują w firmie, warto patrzeć na ludzi z doświadczeniem w Javie oraz bazach danych. Oczywiście podstawą jest doświadczenie z systemami Linuxowymi, oraza z gitem.

Po trzecie – przeszkólmy zespół
Jeśli mamy już zespół, warto go przeszkolić. Szczególnie tą część, która jest “świeża”. Należy dokładnie zastanowić się nad technologiami z jakimi chcemy ruszyć, jakie bedą potrzebne na początku. W ustaleniu dokładnego planu działania pomoże specjalna firma – tu polecam nas, RDF;-). Zapraszam pod ten link, gdzie można zapoznać się z ofertą szkoleń.
W tym miejscu dodam jeszcze jedno. Szkolenia można przeprowadzać doraźne i intensywne. Na przykład kilka dni bardzo mocnego treningu z Apache Spark. Jest jednak dostępna także inna możliwość, która tutaj sprawdzi się znacznie bardziej. To bardzo obszerne, długie szkolenia, które wyposażają kursantów w umiejętności z podstaw Big Data. Takie szkolenie może trwać nawet 2, 3 miesiące. Warto rozważyć;-).
Po czwarte – niech zespół zdobędzie pierwsze rany w walce
Kiedy mamy już cały zespół, warto zrobić pierwszy projekt. Jeszcze nie dla klienta. Najlepiej, żeby projekt ten miał swój konkretny cel, który przysłuży się firmie, będzie projektem Open Source lub choćby “wizytówką”. Niestety, nie wszystko wyjdzie w czasie szkoleń – nawet naszych;-) (mimo, że w ramach tego długiego szkolenia sporo czasu zajmuje mini-projekt właśnie). Wiele rzeczy musi zostać wypalonych w projektowym ogniu. Od stricte technicznych, przez organizacyjne, po kontakcie wewnątrz zespołu.
Po takim projekcie… cóż, sami najlepiej będziecie wiedzieć, czy zespół jest gotowy do działania. Być może potrzebne będą kolejne kroki, a być może wstępne doświadczenie będzie już wystarczająco solidne:-)
Podsumowanie
Uff, to był naprawdę długi artykuł. Cieszę się, że docieramy do końca razem! Jestem przekonany, że masz teraz już podstawową wiedzę na temat Big Data, w kontekście biznesowym. Oczywiście tak naprawdę zaledwie musnęliśmy temat. Jest to jednak już dobry start do dalszej pracy.
Jeśli potrzebujesz naszych usług, polecam z czystym sumieniem. Nasze szkolenia są tworzone z myślą, że mają być możliwie podobne do prawdziwego życia. My sami jesteśmy żywymi pasjonatami naszej branży. Bardzo chętnie Ci pomożemy – czy to w temacie nauki czy konsultacji. Nie bój się napisać!
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Będzie nam bardzo miło Cię gościć;-).
WAŻNA INFORMACJA! Jestem w trakcie pisania ebooka. Będzie w tematyce takiej jak ten artykuł, jednak bardziej “na spokojnie” oraz dogłębniej. Co więcej – będzie za darmo dostępeny! Dla każdego? NIE. Jedynie dla zapisanych na newsletter. Zapisz się już dzisiaj i zyskaj wpływ na proces twórczy;-)