Apache Ozone to następca HDFS – przynajmniej w marketingowym przekazie. W rzeczywistości sprawa jest nieco bardziej złożona i proste analogie mogą być złudne. Jako, że jestem w trakcie budowy systemu do analizy spółek giełdowych, buduję także nowy, eksperymentalny klaster (czy może – klasterek;-)). Uznałem to za idealny moment, żeby przetestować, bądź co bądź nową technologię, jaką jest Apache Ozone. W kolejnym artykule podzielę się swoimi obserwacjami oraz problemami które rozwiązałem. Zacznijmy jednak najpierw od poznania podstaw, czyli architektury Apache Ozone. Zapraszam!
Czym (nie) jest Apache Ozone?
Jeśli Ozone to następca HDFSa, a HDFS to system plików, to Apache Ozone jest systemem plików prawda? Nie. I to jest pierwsza różnica, którą należy dostrzec. HDFS był bliźniaczo podobny (w interfejsie i ogólnej budowie użytkowej, nie architekturze) do standardowego systemu plików dostępnego na linuxie. Mieliśmy użytkowników, foldery, a w nich pliki, ewentualnie foldery, w których mogły być pliki. Albo foldery. I tak w kółko.
Apache Ozone to rozproszony, skalowalny object store (/storage). Na temat podejścia object storage można przeczytać tutaj. Podstawową jednak różnicą jest to, że Ozone ma strukturę płaską, a nie hierarchiczną. Również, podobnie jak HDFS, dzieli pliki na bloki, także posiada swoje repliki, jednak nie możemy zawierać zagnieżdżonych folderów.
Podstawowa budowa Apache Ozone
Ozone oczywiście jest systemem rozproszonym – działa na wielu nodach (serwerach/komputerach).
Oto podstawowy opis struktury:
- Volumes – podobne do kont użytkowników lub katalogów domowych. Tylko admin może je utworzyć.
- Buckets – podobne do folderów. Bucket może posiadać dowolną liczbę keys, ale nie może posiadać innych bucketów.
- Keys – podobne do plików.
Ozone zbudowany jest z kilku podstawowych komponentów/serwisów:
- Ozone Manager (OM) – odpowiedzialny za namespacy. Odpowiedzialny za wszystkie operacje na volumes, buckets i keys. Każdy volume to osobny root dla niezależnego namespace’u pod OM (to różni go od HDFSa).
- Storage Container Manager (SCM) – Działa jako block manager. Ozone Manage requestuje blocki do SCM, do których klientów można zapisać dane.
- Data Nodes – działa w ramach Data Nodes HDFSowych lub w uruchamia samodzielnie własne deamony (jeśli działa bez HDFSa)
Ozone oddziela zarządzanie przestrzenią nazw (namespace management) oraz zarządzanie przestrzenią bloków (block space management). To pomaga bardzo mocno skalować się Ozonowi. Ozone Manager odpowiada za zarządzanie namespacem, natomiast SCM za zarządzanie block spacem.
Ozone Manager
Volumes i buckets są częścią namespace i są zarządzane przez OM. Każdy volume to osobny root dla niezależnego namespace’a pod OM. To jedna z podstawowych różnic między Apache Ozone i HDFS. Ten drugi ma jeden root od którego wszystko wychodzi.
Jak wygląda zapis do Ozone?

- Aby zapisać key do Ozone, client przekazuje do OM, że chce zapisać konkretny key w konkretnym bucket, w konkretnym volume. Jak tylko OM ustali, że możesz zapisać plik w tym buckecie,OM zaalokuje block dla zapisu danych.
- Aby zaalokować blok, OM wysyła request do SCM. To on tak naprawdę zarządza Data Nodami. SCM wybiera 3 data nody (najprawdopodobniej na repliki) gdzie klient może zapisać dane. SCM alokuje blok i zwraca block ID do Ozone Managera.
- Ozone Manager zapisuje informacje na temat tego bloku w swoich metadanych i zwraca blok oraz token bloku (uprawnienie bezpieczeństwa do zapisu danych na bloku) do klienta.
- Klient używa tokena by udowodnić, że może zapisać dane na bloku oraz zapisuje dane na data node.
- Gdy tylko zapis jest ukończony na data node, klient aktualizuje informacje o bloku w OM.
Jak wygląda odczyt danych (kluczy/keys) z Ozone?
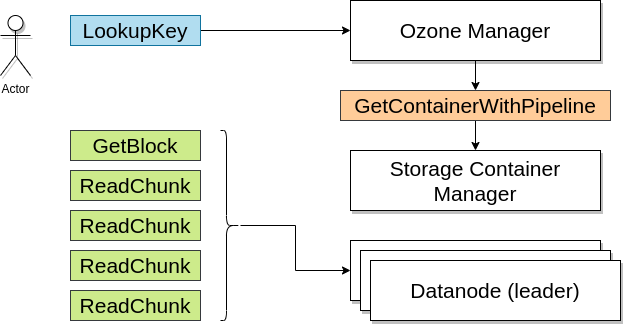
- Klient wysyła request listy bloków do Ozone Manager.
- OM zwraca listę bloków i tokenów bloków, dzięki czemu klient może odczytać dane z data nodes.
- Klient łączy się z data node i przedstawia tokeny, po czym odczytuje dane z data nodów.
Storage Container Manager
SCM jest głównym nodem, który zarządza przestrzenią bloków (block space). Podstawowe zadanie to tworzenie i zarządzanie kontenerami. O kontenerach za chwilkę, niemniej pokrótce, są to podstawowe jednostki replikacji.
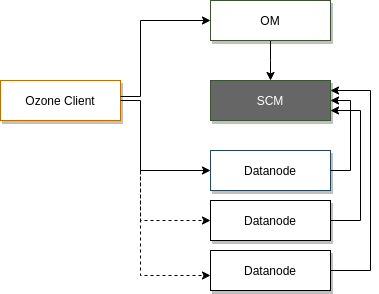
Tak jak napisałem, Storage Container Manager odpowiada za zarządzanie danymi, a więc utrzymuje kontakt z Data Nodami, gra rolę Block Managera, Replica Managera, ale także Certificate Authority. Wbrew intuicji, to SCM (a nie OM) jest odpowiedzialny za tworzenie klastra Ozone. Gdy wywołujemy komendę init, SCM tworzy cluster identity oraz root certificates potrzebne do CA. SCM zarządza cyklem życia Data Node.
- SCM do menedżer bloków (block manager). Alokuje bloki i przydziela je do Data Nodów. Warto zawuażyć, że klienci pracują z blokami bezpośrednio (co jest akurat trochę podobne do HDFSa).
- SCM utrzymuje kontakt z Data Nodami. Jeśli któryś z nich padnie, wie o tym. Jeśli tak się stanie, podejmuje działania aby naprawić liczbę replik, aby ciągle było ich tyle samo.
- SCM Certificate Authority jest odpowiedzialne za wydawanie certyfikatów tożsamości (identity certificates) dla każdej usługi w klastrze.
SCM nawiązuje regularny kontakt z kontenerami poprzez raporty, które te składają. Ponieważ są znacznie większymi jednostkami niż bloki, raportów jest wiele wiele mniej niż w HDFS. Warto natomiast pamiętać, że my, jako klienci, nie komunikujemy się bezpośrednio z SCM.
Kontenery i bloki w Ozone(Contrainers and blocks)
Kontenery (containers) to podstawowe jednostki w Apache Ozone. Zawierają kilka bloków i są całkiem spore (5gb domyślnie).
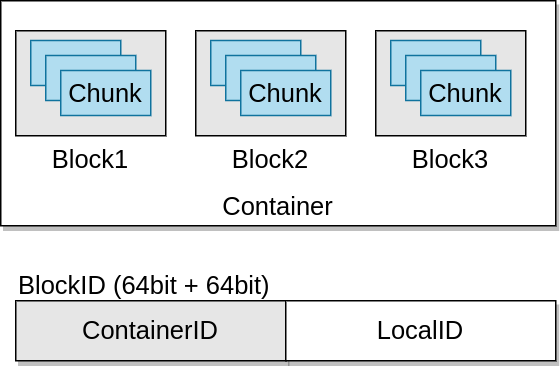
W konkretnym kontenerze znajdziemy ileś bloków, które są porcją danych. Jednak same bloki nie są replikowane. Informacje o blokch nie są też zarządzane przez SCM – są trzymane tylko informacje o kontenerach i to kontenery podlegają replikacji. Kiedy OM requestuje o zaalokowanie nowego bloku do SCM, ten “namierza” odpowiedni kontener i generuje block id, które zawiera w sobie ContainerIs + LocalId (widoczne na obrazku powyżej). Klient łączy się wtedy z Datanode, który przechowuje dany kontener i to datanode zarządza konkretnym blokiem na podstawie LocalId.
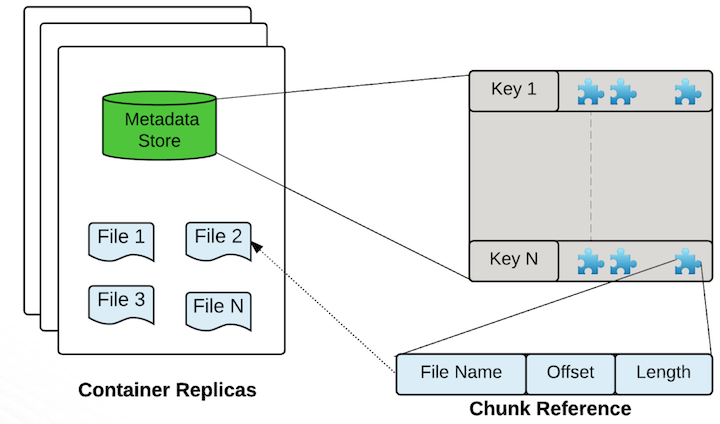
Data Nodes
Data Nody to serwery, na których dzieje się prawdziwa, docelowa magia Ozone. To tutaj składowane są wszystkie dane. Warto pamiętać, że to z nimi bezpośrednio łączy się klient. Zapisuje on dane w postaci bloków. Data node agreguje te dane i zbiera do kontenerów (storage containers). W kontenerach, poza danymi, znajdują się też metadane opisujące je.
Jak to wszystko działa? Kiedy chcemy odczytać plik, uderzamy do OM. Ten zwraca nad listę bloków, która składa się z pary ContainerId:LocalId. To dość chude informacje, ale wystarczą, aby można było udać się do konkretnych kontenerów i wyciągnąć konkretne bloki (LocalId to po prostu unikatowy numer ID w ramach kontenera, czyli w ramach dwóch różnych kontenerów moga być dwa bloki o LocalID=1, natomiast w ramach jednego kontenera nie).
Podsumowanie
Mam szczerą nadzieję, że tym artykułem pomogłem odrobinę zrozumieć architekturę Apache Ozone. Przyznam, że pełnymi garściami czerpałem z dokumentacji. Choć – jestem przekonany – jest to pierwszy polski materiał na temat tej technologii, to z pewnością nie jest ostatni. Jestem w trakcie instalowania Ozone na eksperymentalnym klasterku RDFowym i na bieżąco piszę artykuł o doświadczeniach i błędach, jakie napotkałem. Obserwuj RDF na LinkedIn i zapisz się na newsletter, to nie przegapisz!