Zgłębiając kwestie wydajnościowe zauważyłem, że dzieje się coś dziwnego: jedna akcja generuje wiele jobów. Postanowiłem to sprawdzić i opisać tutaj:-). Śmiało, częstuj się. A jeśli artykuł okaże się przydatny – podziel się nim na LinkedIn… czy gdziekolwiek chcesz.
Kawka w dłoń i ruszamy!
Podstawy – jak działa aplikacja sparkowa?
Bardzo często mówiąc o tym, że piszemy w sparku, mówimy “muszę napisać joba sparkowego”, “mój job szedł 30 godzin!” i inne.
Cóż… według nomenklatury sparkowej, nie jest to poprawne. Co gorsza – może być nieco mylące. Okazuje się bowiem, że to co nazywamy “jobem sparkowym” (czyli cały kod który ma coś zrobić i jest uruchamiany przy użyciu sparka) to tak naprawdę “aplikacja” (application). Aplikacja natomiast składa się z… jobów.
Nie mówię, że masz dokonywać rewolucji w swoim słowniku. Sam zresztą też chwalę się ile to nie trwał “mój job”;-). Pamiętaj jednak, że prawdziwe joby siedzą pod spodem aplikacji.
No dobrze – ale czym dokładnie są te joby? I jak jest zbudowana aplikacja sparkowa? Oczywiście to nie miejsce na szkolenie (na listę oczekujących kursu online “Fundament Apache Spark” możesz zapisać się tutaj). Spróbujmy jednak bardzo pokrótce zrozumieć jak zbudowana jest taka aplikacja.
Zróbmy to w kilku krokach:
- Podczas pisania kodu posługujemy się dwoma rodzajami: akcjami i transformacjami:
- transformacje pozwalają nam przetworzyć RDD/Dataset na inny RDD/Dataset. Nie są jednak wykonywane od razu (lazy evaluation)
- akcje z kolei wykonują wspomniane wcześniej transformacje i tym samym kończą pewną robotę do zrobienia – czyli joba;-).
- Job, czyli praca do wykonania. No właśnie – mamy kilka transformacji, które składają się w jeden ciąg operacji dokonywanych na danych. Na końcu są np. zapisane na HDFS albo wyświetlone na ekranie. I to jest właśnie 1 job. Tak więc powiedzmy to sobie wreszcie – 1 akcja = 1 job, yeeeaahh!
- Czyli w aplikacji może być kilka jobów. To teraz kolejne zagłębienie. Job składa się ze… stage’y. Czyli z etapów. Jak to się dzieje? Wróćmy do transformacji – bo na tym etapie mamy tylko z transformacjami do czynienia (w końcu akcja kończy joba).
- Transformacje też możemy podzielić!
- Narrow Transformations – gdy transformacje z jednej partycji wyprowadzają dokładnie jedną partycję. Narrow Transformations (np. filtry) są dokonywane w pamięci.
- przykłady: filter, map, union, sample, intersection
- Wide Transformations – gd transformacje wyprowadzają z jednej partycji wejściowej kilka partycji wyjściowych. Tutaj, ponieważ wide transformations powodują shuffling, dane muszą zostać zapisane na dysk.
- przykłady: groupBy, join, repartition (te trzy, szczególnie dwa pierwsze, to klasyki – postrachy inżynierów sparkowych)
- No i właśnie dlatego, że wide transformations powodują shuffling (przemieszanie danych między partycjami/executorami/nodami), musi zakończyć się jakiś etap joba. Czyli stage;-).
I można by kilka rzeczy dodać, ale tyle wystarczy, a nawet może zbyt wiele.
Nie mogłem jednak się powstrzymać. Uff… liczę, że jeszcze ze mną jesteś!

Ale dlaczego jedna akcja tworzy wiele jobów?!
Wspomniałem wyżej, że jednej akcji odpowiada jeden job w aplikacji. Jakie było moje zdziwienie, gdy zobaczyłem co następuje.
Oto mój kod. Przykładowy, ćwiczeniowy, prosty do zrozumienia (zmienna spark to instancja SparkSession):
val behaviorDF: Dataset[Row] = spark.read
.option("header", "true")
.csv(pathToBehaviorFile)
behaviorDF.show()
val brandCountDF: Dataset[Row] = behaviorDF.groupBy("brand")
.count()
.as("brandCount")
val userIdCount: Dataset[Row] = behaviorDF.groupBy("user_id")
.count()
.as("userCount")
val behaviorsWithCounts: Dataset[Row] = behaviorDF.join(brandCountDF, "brand")
.join(userIdCount, "user_id")
behaviorsWithCounts.show(20)
Jak widać mamy dwie akcje:
- behaviorDF.show() – linijka 23 (w rzeczywistości)
- behaviorsWithCounts.show(20) – linijka 35 (w rzeczywistości).
Czyli z grubsza powinny być 2, może 3 joby (jeśli liczyć także wczytywanie danych).
Co zastałem w Spark UI?
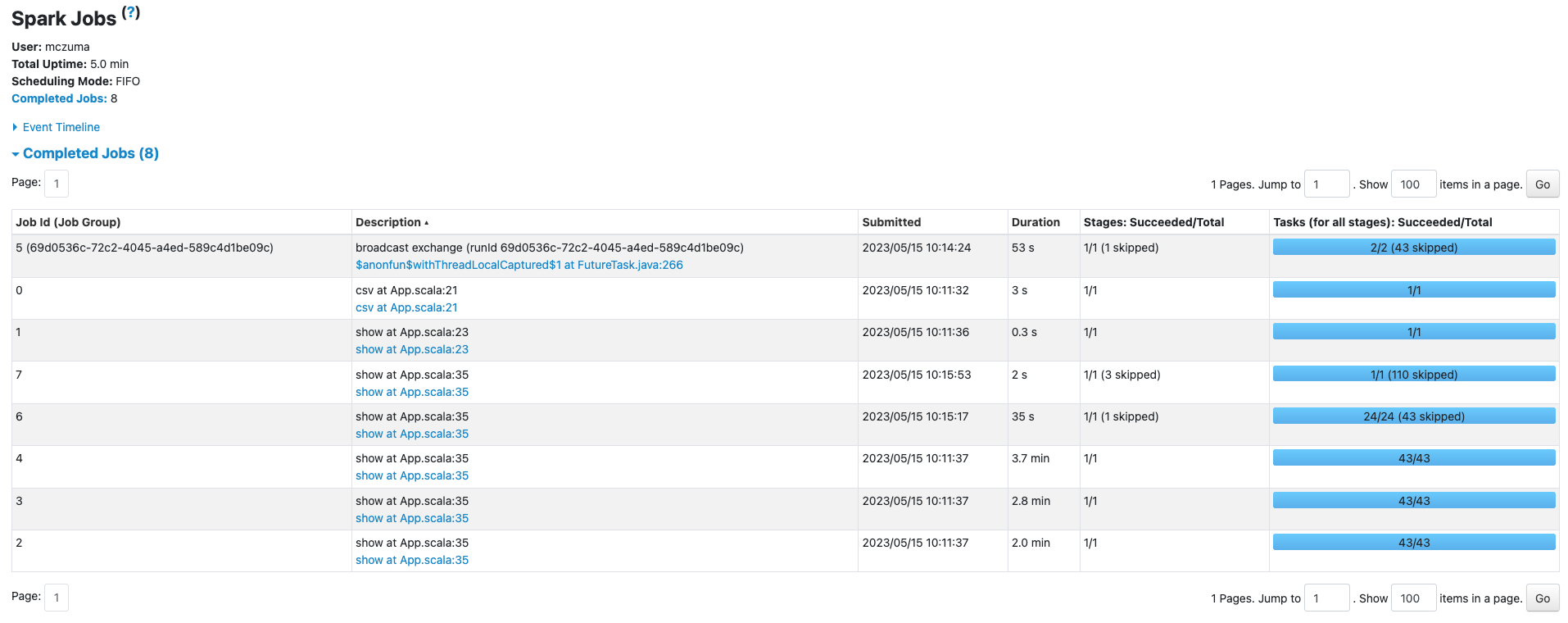
WHAAAT…
Jak to się stało?
Czemu mam… 5 różnych jobów do akcji z linijki 35?
Otóż – mogą być za to odpowiedzialne dwie rzeczy:
- DataFrame to abstrakcja zbudowana na RDD. 1 akcja odpowiada 1 jobowi, ale… na RDD. Dataframe czasami “pod spodem” może wykonywać jeszcze inne akcje. JEDNAK TO NIE TO BYŁO MOJE ROZWIĄZANIE. Dotarłem do takiego wyjaśnienia więc się nim dzielę. U mnie natomiast DUŻO WAŻNIEJSZY okazał się pkt 2.
- Włączone Adaptive Query Execution – czyli mechanizm optymalizacyjny Apache Spark. Może być włączony albo wyłączony. Od Sparka 3.2.0 AQE włączone jest domyślnie!
Po ustawieniu prostej konfiguracji “spark.sql.adaptive.enabled” na “false”, jak poniżej…
val spark: SparkSession = SparkSession.builder()
.appName("spark3-rdf-tests")
.config("spark.sql.adaptive.enabled", false)
// .master("local[*]")
.getOrCreate()
… i uruchomieniu aplikacji raz jeszcze, efekt w 100% pokrył się z moją wiedzą teoretyczną.
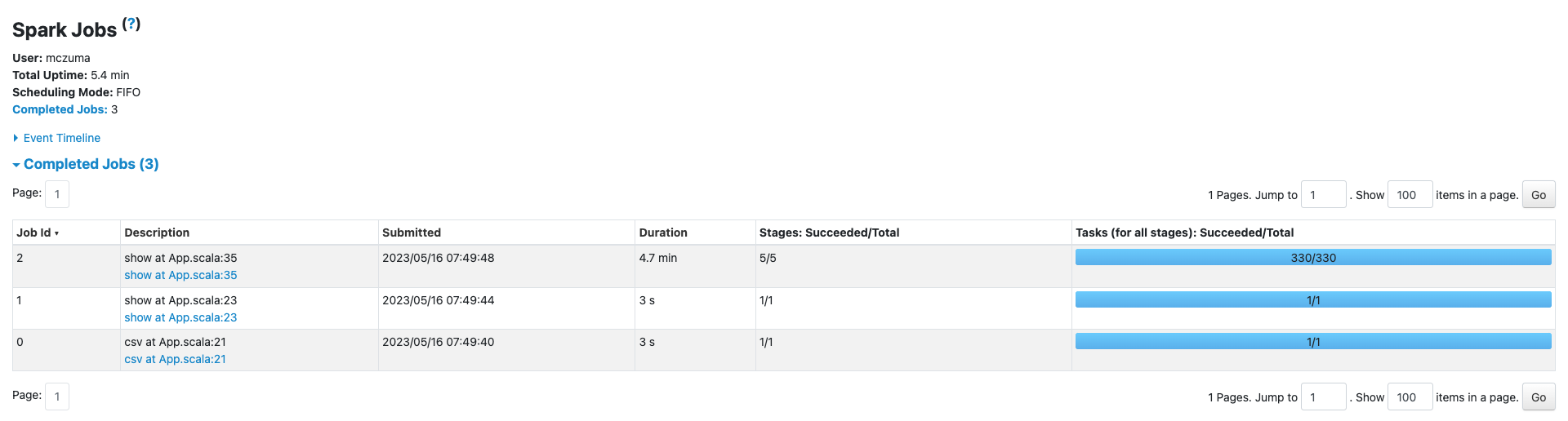
OMG CO ZA ULGA
UWAGA! Warto pamiętać, że AQE jest z zasady dobrym pomysłem. Nie wyłączaj tego, jeśli nie wiesz dokładnie po co to chcesz robić.
Ja na przykład wyłączam w celach edukacyjnych;-)
Szkolenie z Apache Spark – może tego właśnie potrzebujesz?
Jeśli reprezentujesz firmę i potrzebujecie solidnie przeczołgać się ze Sparka… jesteśmy tu dla Was!
Mamy solidnie sprawdzoną formułę.
I własny klaster, na którym poeksperymentujecie;-)
Więcej informacji na tej stronie.
Możesz też po prostu napisać na: kontakt@riotechdatafactory.com !
Co to jest Adaptive Query Execution?
No to teraz pokrótce: co to jest Adaptive Query Execution?
Przeczytasz o tym w dokumentacji Sparka, o tutaj.
Mówiąc jednak prosto i zwięźle: Adaptive Query Execution to mechanizm zawarty w Spark SQL, który pozwala zoptymalizować pracę aplikacji. AQE dokonuje optymalizacji bazując na “runtime statistics”. Temat samych statystyk będę poszerzał w przyszłości tutaj lub na kanale YouTube. Zapisz się na newsletter, żeby nie przegapić;-). I przy okazji zgarnij jedynego polskiego ebooka wprowadzającego w branżę Big Data (i to kompleksowo!).
AQE ma 3 podstawowe funkcjonalności:
- Łączenie partycji po shufflingu – dzięki temu mechanizmowi bardziej wydajnie dobierane są partycje. Widać to m.in. na powyższym przykładzie – gdy porównasz liczby partycji w obu przypadkach.
- Dzielenie partycji ze “skośnościami” po shufflingu (data skewness) – spark będzie optymalizował partycje, które podlegają “skośności” (są zbyt duże, co wychodzi dopiero po shufflingu).
- Zamiana “sort-merge join” na “broadcast join” – zamienia jeśli statystyki którakolwiek strona joina jest mniejsza niż poziom pozwalający na taką operację.
W praktyce AQE daje zauważalne rezultaty. Widać to dość symbolicznie na mojej małej aplikacji (ładuję tam jedynie 5 gb z hakiem), gdzie wynik z ~5.4 min zszedł do ~5 min.
Minusy? Przede wszystkim mniejsza czytelność podczas monitoringu joba. Co z jednej strony może wydać się śmieszne, ale w rzeczywistości, gdy musimy zoptymalizować jakąś bardzo złożoną aplikację – może zrobić się uciążliwe.
Podsumowanie
Podsumowując:
- Od Sparka 3.2.0 domyślnie włączony jest Adaptive Query Execution.
- To mechanizm, który pozwala na bardzo konkretną optymalizację. Powoduje niestety pewne “zaszumienie” monitoringu aplikacji.
- W efekcie zamiast zasady 1 akcja = 1 job, nasza aplikacja będzie bardziej porozbijana.
- Można to wyłączyć (aby nie zachęcać do pójścia “na łatwiznę” – jak to zrobić zostało zawarte w tekście;-)). Nie rób jednak tego bez solidnej argumentacji.
- Zapisz się na newsletter i przeczytaj ebooka, który pokaże Ci Big Data z kilku różnych storn. A jak Ci się spodoba, napisz o tym w sieci żeby i inni wiedzieli:-).
Jeśli natomiast szukasz czegoś, co pokaże Ci podstawy Sparka od A do Z…
Może sprawdzisz kurs “Fundament Apache Spark”?
“Podobno” niektórzy od tego kursu… zaczęli całą przygodę z branżą;-).