Jak wyglądają szkolenia Big Data? Jakie są rodzaje szkoleń Big Data? Co sprawia, że szkolenia w Riotech Data Factory są skuteczne? Na co stawiamy akcent?
O tym wszystkim w najnowszym wideo;-). Zachęcam nie tylko do obejrzenia, ale także subskrypcji kanały RDF na YouTube!
Szkolenia Big Data – jak to wygląda?
Przypominam jeszcze, jeśli nie jesteś członkiem newslettera, po zaciągnięciu się na nasz okręt dostajesz na wejściu prawie 140 stron ebooka o Big Data! Nie zwlekaj;-)
Po miesiącach materiałów (wideo i artykułów) technicznych, chciałbym uchylić rąbka “tajemnicy” dotyczącej szkoleń RDF. Konkretnie, na wideo opowiadam (i pokazuję) dość szczegółowo jaka jest infrastruktura technologiczna na której szkolą się kursanci RDF.
Klaster RDF do szkoleń – czyli na czym pracują kursanci?
Poniżej wklejam wideo i zapraszam do subskrybowania kanału RDF na YouTube;-)
Za mną już znacznie ponad 20 mięsistych, wyczerpujących wpisów. Wciąż jednak brakuje fundamentalnego “Co to jest Big Data?”. Na to pytanie można odpowiadać godzinami. Dziś chciałbym jednak spojrzeć z biznesowej perspektywy. Nie będzie zbyt wielu technikaliów. Nie będziemy rozważać ile executorów powinno się ustawiać w spark-submit, ani czym różni się HBase od Accumulo. Ten artykuł przeznaczony jest dla osób zarządzających. Dla tych, którzy chcą pchnąć firmę na wyższy poziom i zastanawiają się, co to jest ta Big Data. Kubek z kawą na biurko… i ruszamy!
Jak to się zaczęło?
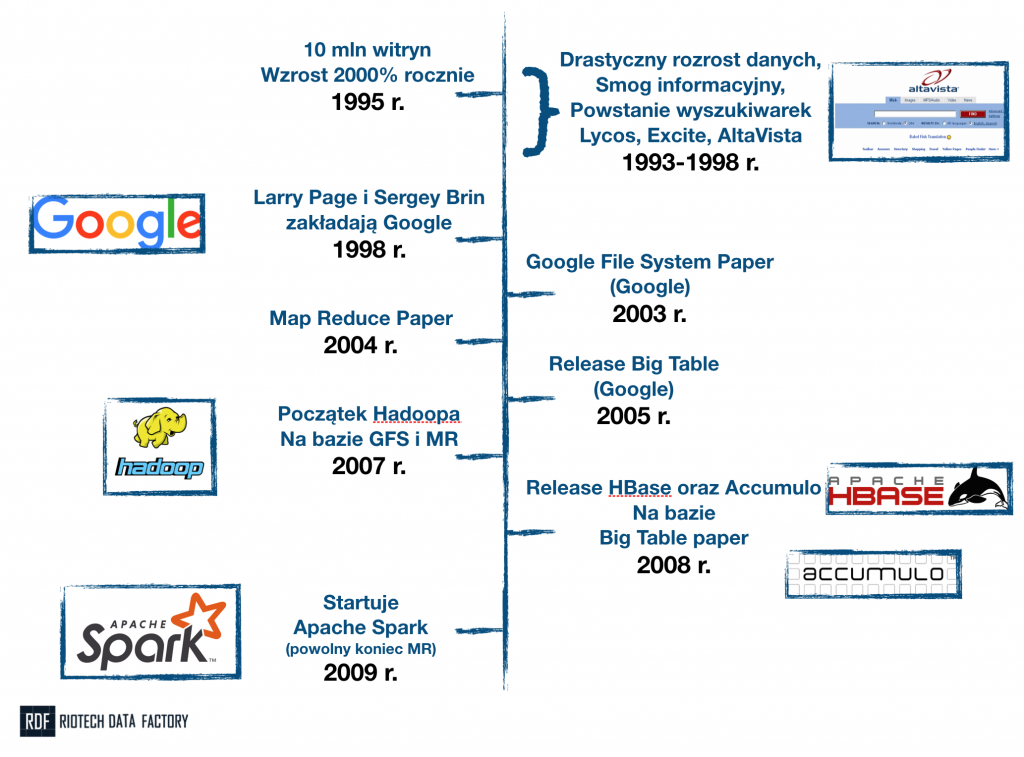
Zanim przejdziemy do samego sedna, bardzo istotna jest jedna rzecz: Big Data to naprawdę duża, złożona działka. Ciężko opisać ją w kilku punktach. Żeby ją zrozumieć, trzeba podejść z w kilku różnych kontekstach. Zacznijmy od krótkiej historii początków. Dzięki temu prawdopodobnie nie tylko zrozumiemy kontekst, ale i kilka cech charakterystycznych tej branży – co przyda się w podejmowanych decyzjach biznesowych.
Jak to często bywa z historią, początki są niejasne i każdy może mieć troszkę swoją własną teorię. Moim zdaniem jednak, definitywny początek Big Data ma… w Google. Tak – znana nam wszystkim korporacja (i wyszukiwarka) jest absolutnie najbardziej zasłużoną organizacją dla tej branży. Niezależnie od rozmaitych swoich grzeszków;-). Ale spójrzmy jeszcze wcześniej – do roku 1995. To wtedy Internet przybiera na sile. Jego rozmiary są nie do końca znana, natomiast sięga już przynajmniej 10 mln witryn. Co “gorsza”… rozwija się w tempie 2000% rocznie.
AltaVista była pierwszą, przełomową wyszukiwarką
Chaos Internetowy lat 90′
Kluczową dla funkcjonowania Internetu rzeczą, są wyszukiwarki. Dziś to dla nas rzecz oczywista, ale w 95′ wcale tak nie było. Jeśli jednak nie będzie wyszukiwarek, nie znajdziemy znakomitej większości rzeczy, których potrzebujemy. Problem polega na tym, że wyszukiwarki nie przeszukują całego internetu za każdym razem. One zapisują strony (w odpowiedniej strukturze, niekoniecznie całe strony) w swoich bazach danych. Następnie przeszukują te bazy, kiedy użytkownik przekaże zapytanie.
Wniosek jest oczywisty: wyszukiwarki to nie nudne “lupki”, a bardzo zaawansowana technologicznie maszyneria. Maszyneria, która potrzebuje dożo miejsca na dysku, dużo pamięci podręcznej oraz mocy obliczeniowej. Jak bardzo, przekonali się o tym Larry Page i Sergey Brin, którzy w 1998 roku zakładają Google. Z czasem bardzo szybko orientują się, że przyrost danych jest zbyt ogromny na jakikolwiek komputer.
I tutaj pojawia nam się pierwsza, najważniejsza (moim zdaniem) zasada, charakterystyka Big Data. Inżynierowie sporej już wtedy firmy, rozpoczęli prace nad technologią, która pozwoli przechowywać oraz przetwarzać bardzo duże dane (których jest więcej i więcej i więcej…). Ci jednak, zamiast skonstruować olbrzymi super-komputer, którym zaimponują światu, poszli w zupełnie inną stronę. Uznali, że i tak prędzej czy później (a raczej prędzej) skończy im się miejsce i moc obliczeniowa. Co wtedy, nowy super-komputer? No właśnie nie.
Podejście rozproszone (distributed)
Znacznie lepszym pomysłem będzie zbudowanie takiego oprogramowania, które pozwoli połączyć bardzo wiele komputerów. I korzystać z nich tak, jakbyśmy mieli jeden wielki komputer. Co kiedy skończą się możliwości? Cóż – po prostu dorzucimy kolejne mniejsze komputery do naszego ekosystemu. Takie podejście nazywa się podejściem “rozproszonym” (ang. distributed). Tak właśnie powstaje Google File System (GFS) oraz opublikowany zostaje Google File System Paper, na którym opisana jest architektura wynalazku. Rok i dwa lata później publikowane są kolejne przełomowe dokumenty: Map Reduce (MR) Paper (który opisuje technologię do przetwarzania danych) i Big Table Paper.
Czemu Google to fundament Big Data? Bo na wyżej wymienionych dokumentach powstają najbardziej fundamentalne technologie open-source. Fundacja Apache ogłasa w 2007 roku, że na bazie GFS oraz MR powstaje Hadoop – prawdopodobnie najbardziej znana technologia Big Data. Rok później, znów na bazie dokumentu Google (Big Table Paper) powstają dwie bazy danych: HBase oraz Accumulo.
Historia Big Data. Od chaosu w Internecie na początku lat 90′ do zaawansowanych technologii Big Data XXI wieku.
Co to jest Big Data? Zasada 3V
Skoro wiemy już jak to się wszystko zaczęło, przejdźmy do podstawowego pytania: Co to tak naprawdę jest Big Data? Skonkretyzujmy to sobie nieco. Jesteśmy w IT, więc postarajmy się zdefiniować tą materię. Dawno temu wyznaczona została zasada, która określa czym jest Big Data. Zasada ta była później rozwijana, natomiast my przyjrzymy się pierwotnej wersji. Dodajmy – wersji, która moim zdaniem jest najlepsza, każda kolejna to już troszeczkę budowa sztuki dla sztuki;-).
Chodzi mianowicie o wytłuszczoną w nagłówku zasadę 3V. Określa ona cechy danych, które najmocniej charakteryzują Big Data.
Volume (objętość) – najbardziej intuicyjna cecha. Wszyscy dobrze rozumiemy, że jak data mają być big, to muszą mieć “dużą masę”. Ile dokładnie, ciężko stwierdzić. Niektórzy mówią o dziesiątkach GB, inni dopiero o terabajtach danych.
Velocity (prędkość) – to już nieco mniej oczywista rzecz. Moim zdaniem jednak bardzo istotna dla zrozumienia naszej materii. Wyobraź sobie, że śledzisz wypowiedzi potencjalnych klientów w mediach społecznościowych. W tym celu analizujesz wszystkie posty z określonymi tagami. Można się domyślić jak szybko przybywa tych danych (i jak bardzo często są one nie do użycia, ale to już inna sprawa). Tutaj właśnie objawia się drugie “V”. Wielokrotnie mamy do czynienia nie tylko z dużymi danymi, ale także z danymi które napływają lub zmieniają się niezwykle szybko. To ogromne wyzwanie. Znacząco różni się od stanu, w którym po prostu musimy przetworzyć paczkę statycznych, zawsze takich samych danych.
Variety (różnorodność) – I ta cecha prawdopodobnie jest już zupełnie nieintuicyjna (w pierwszym odruchu). Dane które dostajemy bardzo często nie są pięknie ustrukturyzowane, ułożone, wraz z dostarczonymi schematami. Wręcz przeciwnie! To dane, które często są nieustrukturyzowane, w których panuje chaos. Dane, które nawet w ramach jednego zbioru są różne (np. wiadomości email). Są to wyzwania z którymi trzeba się mierzyć i do których zostały powołane odpowiednie technologie – technologie Big Data.
Big Data w biznesie – kiedy zdecydować się na budowanie kompetencji zespołu?
Skoro już wiemy jak to się zaczęło i czym to “dokładnie” jest, czas postawić to kluczowe pytanie. Przynajmniej kluczowe z Twojej perspektywy;-). Kiedy warto zdecydować się na budowanie kompetencji Big Data w zespole? Nie będę zgrywał jedynego słusznego mędrca. Ta branża jest skomplikowana niemal tak jak życie. Nie ma jednego zestawu wytycznych. Podzielę się jednak swoimi spostrzeżeniami.
Poniżej wymieniam 5 sytuacji, które mogą Ci się przydać. Bądźmy jednak szczerzy – to pewna generalizacja. Być może jednak całkiem przydatna;-).
Na horyzoncie pojawia się projekt, który nosi znamiona Big Data
Niezależnie od tego jaki jest charakter Twojej firmy, prace poukładane są w coś co nazwiemy “projektami”. Ten punkt sprawdzi się szczególnie wtedy, gdy outsourceujecie zasoby ludzkie lub robicie zlecaną przez innych robotę. W takiej sytuacji może na horyzoncie pojawić się projekt “legacy”, który ma kilka cech charakterystycznych:
Wykorzystywane są technologie Big Data. Dokładniej na temat tego jakie technologie za co odpowiadają, znajdziesz tutaj. Miej jednak radar nastawiony przynajmniej na kilka z nich:
Hadoop (w tym HDFS, Yarn, MapReduce (tych projektów nie bierz;-)).
Hive, Impala, Pig
Spark, Flink
HBase, MongoDB, Cassandra
Kafka,
“Przerzucane” są duże ilości danych (powyżej kilkudziesięciu gigabajtów)
Projekt bazuje na bardzo wielu różnych źródłach danych
Projekt pracuje na średnich ilościach danych (dziesiątki gb), ale pracuje bardzo niewydajnie, działa wolno i sprawia przez to problemy.
I inne;-). Jeśli widzisz projekt, który na odległość pachnie zapychającymi się systemami, technologiami Big Data i różnorodnością danych – wiedz, że czas najwyższy na budowę zespołu z odpowiednimi możliwościami.
Projekt nad którym pracujecie, przerósł wasze oczekiwania
Wielokrotnie bywa tak, że mechanizmy zbudowane w ramach jakiegoś projektu są dobre. Szczególnie na początkowym etapie, kiedy danych nie ma jeszcze zbyt wielu. Potem jednak danych przybywa, źródeł przybywa i… funkcjonalności przybywa. Tylko technologie i zasoby pozostają te same. W takim momencie proste przetwarzanie danych w celu uzyskania raportów dziennych trwa na przykład 6 godzin. I wiele wskazuje na to, że będzie coraz gorzej.
Ważne, żeby podkreślić, że nie musi to być wina projektantów systemu. Czasami jednak trzeba dokonać pivotu i przepisać całość (albo część!) na nowy sposób pracy. Nie jest to idealny moment na rozpoczęcie wyposażania zespołu w kompetencję Big Data. Może to być jednak konieczne.
Zapada decyzja o poszerzeniu portfolio usługowego
Tu sprawa jest oczywista. Świadczycie usługi IT. Robicie już znakomite aplikacje webowe, mobilne, pracujecie w Javie, Angularze i Androidzie. Podejmujecie decyzję żeby poszerzyć portfolio o usługi w ramach Big Data. To nie będzie łatwe! Należy zbudować całą strukturę, która pozwoli odpowiednio wyceniać projekty, przejmować dziedziczony (legacy) kod czy projektować systemy. Trzeba się do tego przygotować.
Czy trzeba budować cały nowy dział od 0? Absolutnie nie – można bazować na już istniejących pracownikach, choć z całą pewnością przydałby się senior oraz architekt. Warto jednak pamiętać, że cały proces powinien rozpocząć się na wiele miesięcy przed planowanym startem publicznego oferowania usług Big Data.
Organizacja znacząco się rozrasta wewnętrznie
Bardzo często myślimy o przetwarzaniu dużych danych na potrzeby konkretnych projektów, produktów itd. Jednym słowem, zastanawiamy się nad dość “zewnętrznym” efektem końcowym. Musimy jednak pamiętać, że równie cennymi (a czasami najcenniejszymi) danymi i procesami, są te wewnętrzne. Big Data nie musi jedynie pomagać nam w wytworzeniu wartości końcowej. Równie dobrze możemy dzięki obsłudze dużych danych… zmniejszyć chaos w firmie. Nie trzeba chyba nikomu tłumaczyć jak zabójczy potrafi być chaos w organizacji. I jak łatwo powstaje.
Do danych wewnętrznych zaliczymy wszystko co jest “produktem ubocznym” funkcjonowania firmy. Na przykład dane dotyczące pracowników, projektów, ewaluacji itd. Także klientów, zamówień, stanów magazynowych. Jeśli uda nam się na to wszystko nałożyć dane geolokalizacyjne i garść informacji ze źródeł ogólnodostępnych, możemy zacząć budować sobie całkiem konkretne raporty dotyczące profili klientów. Gdy pozyskamy kilka wiader bajtów z serwisów promocyjnych i inteligentnie połączyć z resztą – możemy dowiedzieć się o racy firmy, klientach oraz nadchodzących okazjach znacznie więcej, niż wcześniej. I więcej, niż konkurencja;-).
Chmura czy własna infrastruktura? (Cloud vs On-Premise)
Gdy jesteśmy już świadomi branży Big Data oraz okoliczności, w jakich warto w nią wejść – zastanówmy się nad najbardziej fundamentalną rzeczą. Mowa o infrastrukturze komputerowej, którą będziemy wykorzystywać. Mówiąc bardzo prosto: nasze technologie muszą być gdzieś zainstalowane, a dane gdzieś przechowywane. Pytanie zwykle dotyczy wyboru między dwoma ścieżkami: albo będziemy mieli swoją własną infrastrukturę, albo wykorzystamy gotowych dostawców chmurowych.
Które podejście jest lepsze? Odpowiedź jest oczywista: to zależy. Nie ma jednego najlepszego podejścia. To przed czym chcę Cię w tym miejscu przestrzec, to przed owczym pędem w kierunku chmur. Zwykło się myśleć, że aplikacja działająca w chmurze, to aplikacja innowacyjna, nowoczesna, lepsza. To oczywiście nie jest prawda.
Czym jest Cloud a czym On-premise
Żeby w ogóle wiedzieć o czym mówimy, zacznijmy od uproszczonego wyjaśnienia, które jakoś nas ukierunkuje.
Własna infrastruktura (On-Premise, często skrótowo po prostu „on-prem”) – komputery, które fizycznie do nas należą, są przechowywane gdzieś „na naszym terytorium”. Samodzielnie łączymy je siecią, instalujemy tam odpowiednie oprogramowanie, synchronizujemy itd. Specjalnie do tego typu infrastruktury stworzona została m.in. popularna platforma Big Data Apache Hadoop. Stawiając on-premise musimy zadbać o samodzielną obsługę całości, natomiast koszt związany z zasobami jest „jednorazowy” w momencie zakupu sprzętu (potem oczywiście jeśli chcemy ją rozbudować).
Chmura (Cloud) – czyli instalacja odpowiedniego oprogramowania na komputerach (serwerach) udostępnionych przez zewnętrzną firmę. Taka firma (np. Microsoft ze swoją chmurą Azure) ma centra danych (data center) w różnych miejscach na świecie. Komputery te są ze sobą powiązane odpowiednimi sieciami i zabezpieczeniami. Szczegóły technologiczne na ten moment sobie darujmy (prawda jest taka, że to na tyle złożone tematy, że… z poszczególnych chmur (np. Azure czy AWS) robi się powszechnie uznawane certyfikaty – sam zresztą nawet jednym dysponuję;-)). Za chwilę odrobinę dokładniej opowiemy sobie jakie mamy dostępne możliwości wykorzystując chmurę. Teraz jednak to co trzeba zrozumieć, to że rezygnujemy z ręcznej obsługi zasobów. Oddajemy całość administracyjną fachowcom z konkretnej firmy. Gdy korzystamy z takich usług, nie wiemy na jakim dokładnie komputerze (komputerach, bardzo wielu) lądują nasze dane. Tak więc sporo „zabawy” nam odchodzi. Oczywiście coś za coś, natomiast o plusach i minusach porozmawiamy za chwilę.
Teraz wypadałoby podpowiedzieć jakie dokładnie są różnice. A jest ich dużo. Od przewidywalności, przez koszty (kilka ich rodzajów), kwestie prywatności danych, łatwość skalowalności aż po terytorialność danych. W tym miejscu chciałbym odnieść do moich dwóch artykułów:
W tym artykule daję takie proste zestawienie różnych aspektów. Zajmie Ci to chwilkę, a będzie bardzo dobrym punktem startowym.
Drugi artykuł jest dla ambitnych. Poruszam tam kwestie, które zazwyczaj nie są poruszane. Jest to pogłębiona analiza zagadnienia “Cloud vs On-prem”.
Jak zacząć budowę zespołu z kompetencjami Big Data?
Oto najważniejsze być może pytanie. Napiszę na ten temat osobny artykuł. Tutaj zerknijmy jednak skrótowo na temat, który jest niezwykle istotny, a wręcz powiedzmy sobie – kluczowy. Moment zainwestowania w kompetencje może być wybrany lepiej lub gorzej, ale źle zbudowany zespół będzie się mścić przez lata. Oznacza źle zaprojektowane systemy, źle napisany kod, a to – w efekcie – projekty, które po latach trzeba będzie wyrzucić do śmieci lub napisać od początku. A można uniknąć tego wszystkiego robiąc cały proces tak, aby miał ręce i nogi;-).
Znów – nie chcę rościć sobie praw do wyznaczania jedynie słusznej ścieżki rozwoju. Zaproponuję jednak kilka punktów, które mogą nakierować myślenie na metodyczne podejście, które w perspektywie się opłaci.
Po pierwsze – przygotujmy się
Nie róbmy wszystkiego na łapu capu. Trzeba mieś pewną wiedzę, która zaczyna się w kadrze menedżerskiej. Bez tego będziemy przepalać pieniądze. Niech menedżerowie nie oddzielają się grubym murem od technicznych. Zdobycie podstawowych informacji nie będzie techniką rakietową, a pozwoli podejmować lepsze decyzje.
W jaką wiedzę się uzbroić? (przykład)
Zbudowanie zespołu kosztuje. To podstawa, z którą warto się oswoić. Inżynierowie Big Data są drogimi specjalistami, szkolenie i doradztwo jest drogie. Prawdopodobnie cały proces nie zamknie się w kilkudziesięciu tysiącach złotych, choć kosztorys to zawsze bardzo indywidualna sprawa.
Jakie są dokładnie powody budowy zespołu z kompetencjami Big Data? To bardzo istotne, bo będzie wymuszało różny start, datę, technologie itd. Omawialiśmy to trochę wyżej.
Kiedy Chcemy wystartować?
Na jakim zespole bazujemy? Czy na jakimkolwiek?
Jakie są generalne technologie Big Data? Nie chodzi o szczegóły, ale o ogólne rozeznanie się w tym co istnieje na rynku.
Jaki jest nasz dokładny plan działania? Taka road-mapa powinna być przedyskutowana z początkowym zespołem, aby ludzie Ci mieli świadomość w którym kierunku idą.
Czy potrzebujemy infrastruktury? Być może nie, ale prawdopodobnie jednak na czymś trzeba będzie bazować.
Po drugie – wyznaczmy zespół
Zespół może być tworzony od zera, może być zrekrutowany. Bardzo prawdopodobne, że uda się zrobić opcję hybrydową, czyli wyszkolić kilku specjalistów do początkowego etapu, a zrekrutować seniora, który tym pokieruje.
Jeśli bazujemy na ludziach którzy już pracują w firmie, warto patrzeć na ludzi z doświadczeniem w Javie oraz bazach danych. Oczywiście podstawą jest doświadczenie z systemami Linuxowymi, oraza z gitem.
Po trzecie – przeszkólmy zespół
Jeśli mamy już zespół, warto go przeszkolić. Szczególnie tą część, która jest “świeża”. Należy dokładnie zastanowić się nad technologiami z jakimi chcemy ruszyć, jakie bedą potrzebne na początku. W ustaleniu dokładnego planu działania pomoże specjalna firma – tu polecam nas, RDF;-). Zapraszam pod ten link, gdzie można zapoznać się z ofertą szkoleń.
W tym miejscu dodam jeszcze jedno. Szkolenia można przeprowadzać doraźne i intensywne. Na przykład kilka dni bardzo mocnego treningu z Apache Spark. Jest jednak dostępna także inna możliwość, która tutaj sprawdzi się znacznie bardziej. To bardzo obszerne, długie szkolenia, które wyposażają kursantów w umiejętności z podstaw Big Data. Takie szkolenie może trwać nawet 2, 3 miesiące. Warto rozważyć;-).
Po czwarte – niech zespół zdobędzie pierwsze rany w walce
Kiedy mamy już cały zespół, warto zrobić pierwszy projekt. Jeszcze nie dla klienta. Najlepiej, żeby projekt ten miał swój konkretny cel, który przysłuży się firmie, będzie projektem Open Source lub choćby “wizytówką”. Niestety, nie wszystko wyjdzie w czasie szkoleń – nawet naszych;-) (mimo, że w ramach tego długiego szkolenia sporo czasu zajmuje mini-projekt właśnie). Wiele rzeczy musi zostać wypalonych w projektowym ogniu. Od stricte technicznych, przez organizacyjne, po kontakcie wewnątrz zespołu.
Po takim projekcie… cóż, sami najlepiej będziecie wiedzieć, czy zespół jest gotowy do działania. Być może potrzebne będą kolejne kroki, a być może wstępne doświadczenie będzie już wystarczająco solidne:-)
Podsumowanie
Uff, to był naprawdę długi artykuł. Cieszę się, że docieramy do końca razem! Jestem przekonany, że masz teraz już podstawową wiedzę na temat Big Data, w kontekście biznesowym. Oczywiście tak naprawdę zaledwie musnęliśmy temat. Jest to jednak już dobry start do dalszej pracy.
Jeśli potrzebujesz naszych usług, polecam z czystym sumieniem. Nasze szkolenia są tworzone z myślą, że mają być możliwie podobne do prawdziwego życia. My sami jesteśmy żywymi pasjonatami naszej branży. Bardzo chętnie Ci pomożemy – czy to w temacie nauki czy konsultacji. Nie bój się napisać!
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Będzie nam bardzo miło Cię gościć;-).
WAŻNA INFORMACJA! Jestem w trakcie pisania ebooka. Będzie w tematyce takiej jak ten artykuł, jednak bardziej “na spokojnie” oraz dogłębniej. Co więcej – będzie za darmo dostępeny! Dla każdego? NIE. Jedynie dla zapisanych na newsletter. Zapisz się już dzisiaj i zyskaj wpływ na proces twórczy;-)
Nie ma znaczenia czy dopiero zaczynasz swoją przygodę z Big Data, czy masz już doświadczenie, czy jesteś inżynierem, czy patrzysz na branżę stricte biznesowo. W każdym przypadku przyjdzie taki moment, w którym poczujesz się zagubiony mnogością technologii oraz tym jak bardzo są “niedookreślone”. W tym materiale postaram się wprowadzić względny porządek i przeprowadzić Cię suchą stopą przez bagno technologii obsługujących duże dane. Bierz zatem kubek mocnej jak otchłań Data Lake’a kawy – i zaczynamy!
Metodologia
Małe zastrzeżenie…
Zacznijmy od bardzo podstawowego zastrzeżenia: to co tu zaproponuję, może być bardzo łatwo podważone. Co więcej – to co tu pokażę, będzie z całą pewnością niepełne. BA! Niepełne? Dobre sobie… to będzie zaledwie muśnięcie Big Datowej rzeczywistości. Wszystko to wynika z faktu, że branża przyjęła już naprawdę pokaźne rozmiary i wprowadzenie poważnej metodologii porządkującej pojęcia oraz technologie, wymagałoby pracy dyplomowej. Być może nawet doktoratu. Czemu? Cóż – tego jest po prostu najzwyczajniej w świecie tak dużo i odpowiadają na tak wiele potrzeb, że łączenie technologii staje się prawdziwą sztuką.
Zatem powiedzmy sobie: ten artykuł jest dla Ciebie, jeśli wiesz coś niecoś o Big Data, ale wszystko zaczęło się mieszać. Zastanawiasz się nad tym które z topowych technologii służą do czego i jak można je połączyć. Z takim podejściem – zaczynamy!
Podział ze względu na przeznaczenie
Dzielić technologie można ze względu na wiele rzeczy – możemy podzielić patrząc na języki programowania, możemy podzielić patrząc czy jest to technologia chmurowa, a można poszukać pod kątem popularności. Można też – i tak zrobimy – podzielić ze względu na przeznaczenie, cel jakiemu służą.
Mój podział będzie następujący:
Storages
Bazy danych (nierelacyjne)
Full-text search
Przetwarzanie danych
Komunikacja z danymi
Schedulers
Messaging
Technologie analityczne
Jeszcze raz zaznaczę: jest to z całą pewnością obraz niepełny. Jest jeszcze trochę obszarów, które nie zostały tu wzięte pod uwagę. Ten pozwoli jednak złapać pewien punkt zaczepienia – i o to chodzi;-).
Storages
Czemu służą?: Storages (nie mam pojęcia jak przetłumaczyć to poprawnie, poza dość prostackimi “magazynami danych”) służą przechowywaniu ogromnych ilości danych w sposób możliwie prosty.
Krótki komentarz: Temat storages nie jest dobrze zdefiniowany. Niekiedy jako storage traktuje się wszystko, co przechowuje dane, a więc także bazy danych. Ja wyodrębniłem tu jednak “data storage” jako “prosty” system, który pozwala przechowywać dane w sposób mniej złożony, niż bazy. Należą więc do tego wszelkiego rodzaju rozproszone systemy plików, Data Lakes itd.
Przedstawiciele:
HDFS (Hadoop Distributed File System)
ADLS gen 2 (Azure Data Lake Storage gen 2)
Amazon S3 (na AWS)
Google Cloud Storage (na GCP)
Delta Lake
Kudu (wymienione także w Bazach Danych)
Ozone (wymienione także w Bazach Danych)
Bazy danych (noSql)
Czemu służą?: Bazy danych służą przechowywaniu ogromnych ilości danych. Różnią się jednak nieco od Storages. Ich przeznaczenie zawiera bardziej ustrukturyzowaną formę przechowywania danych, a także możliwości bardziej zaawansowanej manipulacji danymi (przeglądania, usuwania pojedynczych rekordów itd).
Krótki komentarz: W temacie baz danych mamy bardzo dużo i coraz więcej technologii, które mogą nas interesować. Niektóre z nich nieco mieszają się ze Storages. To są właśnie te płynne granice o których już wspominałem. UWAGA! Wspominam tu jedynie o stricte big datowych, nierelacyjnych bazach danych. Nie znajdziemy tu więc popularnego mysql czy postgresql. Mamy wiele rodzajów baz danych – przede wszystkim key-value store, graph db, document store.
Przedstawiciele:
HBase
Accumulo
MongoDB
Cassandra
CosmosDB (Azure)
Dynamo DB (AWS)
Google Cloud Datastore (GCP)
Kudu (wymienione także w Storages)
Ozone (wymienione także w Storages)
Neo4j
Druid
Full Text Searches
Czemu służą? Technologie full-text search (przeszukiwania pełno-tekstowego) także (znów!) odpowiadają za przechowywanie danych. Tym razem jednak przechowywanie zaprojektowane jest tak, aby dało się to potem bardzo dobrze przeszukiwać. Szczególnie mocny akcent położony jest na przeszukiwanie tekstu wraz z różnymi funkcjami wbudowanymi, tak aby nie było szczególnie trudne zbudowane wyszukiwarki zawierającej wyszukiwanie podobnych wyrazów czy uwzględnianie literówek.
Krótki komentarz: W przeciwieństwie do pozostałych obszarów, full-text searche zdają się być zdominowane przez dwie technologie. Co więcej – obie zbudowane są na tym samym silniku. Nie oznacza to jednak, że jest to jedyna oferta na rynku! Co ciekawe, full-text searche mogą stanowić także znakomity mix przydatny do analizy danych. Ciekawym przykładem jest zastosowanie Elasticsearcha w NASA (konkretniej JPL) m.in. do analizy danych przysyłanych przez łaziki.
Przedstawiciele:
Lucene – nie jest samodzielną osobną technologią, a raczej silnikiem, na którym powstały inne.
Elasticsearch
Solr
Sphinx
Przetwarzanie danych (processing)
Czemu służą? Technologie do przetwarzania danych oczywiście… przetwarzają dane;-). Oczywiście mowa tu o bardzo dużych danych. W związku z tym technologie te zwykorzystują mechanizmy zrównoleglania obliczeń. Można te technologie wykorzystywać do ogromnej ilości celów. Od strandardowego czyszczenia, przez harmonizację (sprowadzenie datasetów do wspólnej postaci pod kątem schematu), opracowywanie raportów statystycznych, aż po wykorzystywanie algorytmów sztucznej inteligencji.
Krótki komentarz: Technologie do przetwarzania danych podzielimy z grubsza na dwa rodzaje: batchowe i streamingowe. Batchowe to te, których zadaniem jest pobrać dużą paczkę danych, “przemielić je” i zwrócić wynik. Streamingowe natomiast działają w trybie ciągłym. W przeciwieństwie do pierwszego rodzaju – “nie kończą się”.
Przedstawiciele:
Spark
Spark Structured Streaming – choć zawiera się w pierwszym punkcie, zasługuje na osobne wyróżnienie.
Kafka Strams – świetnie wspólgra z Kafką. Dodatkowo cechuje się daleko posuniętą prostotą.
Flink
Storm
Map Reduce – choć obecnie nie jest już raczej implementowany w nowych systemach, to znajduje się w galerii sław i nie można o nim nie wspomnieć!
Klasyka gatunku. Witamy w Sparku!;-)
Komunikacja z danymi (interfejsy SQL-like)
Czemu służą? Technologie które mam na myśli powodują, że w prostszy sposób możemy dostać się do danych, które normalnie przechowywane są w postaci plików (lub w innej postaci, natomiast wciąż kiepskiej w kontekście pracy z danymi). Przykładem jest, gdy chcemy składować pliki na HDFS, ale zależy nam na zachowaniu możliwości pracy z tymi danymi (prostych operacji przeszukiwania, dodawania itd). Technologie te dostarczają często interfejs obsługi danych składowanych w różnych miejscach, podobny do SQL.
Przedstawiciele:
Hive
Impala
Shark
BigSQL
Schedulery
Czemu służą? Kiedy tworzymy joby, bardzo często mamy potrzebe ustawienia ich aby były uruchamiane o tej samej porze. Temu właśnie służą między innymi schedulery.
Krótki komentarz: Poza prostymi funkcjami określania kiedy jakie joby powinny zostać uruchomione, schedulery pozwalają także ustawić całą ścieżkę zależności w uruchamianiu jobów. Np. “jeśli zaciąganie danych zostanie ukończone, rozpcoznij czyszczenie, a potem harmonizację. Jeśli na którymś etapie coś pójdzie nie tak, wyślij maila z alertem”. Do tego dochodzą jeszcze możliwości (lepszego lub gorszego) monitoringu tych jobów oraz całych workflowów.
Przedstawiciele:
Oozie
Airflow
Luigi
Jenkins (częściowo)
Pinball (stworzony przez Pinterest, natomiast nie jest obecnie aktywnie przez pinterest rozwijany)
Step Functions (AWS)
Workflows (GCP)
Logic Apps (Azure)
Messaging
Czemu służą? Technologie do messagingu czy też kolejkowania, to technologie, które – nieco banalizując – są “punktem przesyłu” wielu danych. Wykorzystuje się je szczególnie często w kontekście przetwarzania streamingowego danych. Kiedy produkujemy jakieś dane, nie musimy się zastanawiać gdzie mają być dalej przetworzone. Wystarczy wykorzystać technologię kolejkowania i już. To jakie inne procesy podepną się pod ten “punkt przesyłu” to już zupełnie inna sprawa.
Krótki komentarz: Bardzo często technologie te zestawiane są z frameworkami do przetwarzania streamingowego. Wymienione zostały m.in. parę punktów wyżej (np. Spark Structured Streaming, Flink czy Kafka Streams). Warto tu dodać, że technologie tego typu są także często wykorzystywane w procesie IoT (internetu rzeczy – Internet of Things), gdy poszczególne urządzenia mogą raportować o swojej aktywności.
Przedstawiciele:
Kafka
RabbitMQ
Event Hub (Azure)
Kinesis (AWS)
Pub/Sub (GCP)
IBM MQ (IBM)
Technologie analityczne (BI – Business Intelligence)
Czemu służą? Za pomocą narzędzi analitycznych możemy tworzyć dashboardy, które pomogą nam analizować wcześniej zebrane dane.
Krótki komentarz: Warto pamiętać właśnie o takim aspekcie jak “wcześniej zebrane dane”. Nie wystarczy, że będziemy mieli aplikację analityczną. Aby w pełni wykorzystać jej potencjał, należy zawczasu pomyśleć o tym jak powinien wyglądać nasz pipeline, aby odpowiednie dane (nie za duże, nie za małe, odpowiednio ustrukturyzowane itd.) mogły zostać przez narzędzie BI zaciągnięte.
Przedstawiciele:
Apache Superset
Power BI (Azure)
Amazon QuickSite (AWS)
Google Data Studio (GCP)
Holistics
Looker
Tableau
I jak się w tym wszystkim nie zagubić?
Mam nadzieję, że tym artykułem chociaż odrobinę pomogłem w uporządkowaniu spojrzenia na świat Big Data. Mnóstwo technologii nie zostało tutaj ujętych. Jest to jednak dobry punkt startowy;-). Jeśli widzisz potrzebę, aby coś tutaj dodać lub zmienić – daj sobie swobodę napisania o tym w komentarzu:-).
Inflacja po raz pierwszy (od dawna) weszła “pod strzechy” – nie jest już jedynie tematem dyskusji eksperckich. Wręcz przeciwnie – od kilku miesięcy jest bohaterką pierwszych stron gazet w całym kraju – z brukowcami włącznie. Powodem jest znaczne przyspieszenie utraty wartości waluty, co w przypadku naszej historii wzbudza szczególnie nieprzyjemne skojarzenia. Dodatkowo niektórzy zarzucają stronie rządowej, że oficjalna inflacja jest zaburzona.
Chciałbym dzisiaj zaproponować pewne rozwiązanie, które pomogłoby nam w analizie inflacji, a co za tym idzie – w odpowiedniej kontroli nad nią. Wszystko co poniżej to pewna ogólna wizja, która może posłużyć jako inspiracja. Jeśli jest chęć i zapotrzebowanie, bardzo chętnie się w tą wizję zagłębię architektonicznie i inżyniersko. Zachęcam także do kontaktu, jeśli TY jesteś osobą zainteresowaną tematem;-).
Krótka lekcja: jak liczona jest inflacja?
Czym jest inflacja?
Zanim przejdziemy do rozwiązania, zacznijmy od problemu. Czym jest inflacja i jak liczy ją GUS? Przede wszystkim najważniejsze to zrozumieć, że inflacja to spadek wartości pieniądza w czasie. Dzieje się tak w sposób praktyczny poprzez wzrost cen. Za ten sam chleb, wodę – musimy zapłacić więcej. I teraz to najważniejsze: inflacja jest inna dla każdego z nas. Każdy z nas ma bowiem inny portfel.
Jeśli zestawimy samotnego programistę oraz rodzinę wielodzietną, gdzie Tata zarabia jako architekt a Mama jako tłumaczka, ich budżety bedą zupełnie inne. Nawet jeśli zarabiają podobne kwoty, w rodzinie większy udział prawdopodobnie będzie na pieluchy, przedmioty szkolne i parę innych rzeczy. W przypadku młodego singla z solidną pensją, do tego z rozrywkowym podejściem do życia, znacznie większy procent budżetu zajmie alkohol, hotele, imprezy itd. Jeśli ceny alkoholi pójdą w górę o 40%, dla niektórych inflacja będzie nie do zniesienia, dla innych z kolei może nie zostać nawet zauważona.
Jak liczone jest CPI (inflacja konsumencka)?
Aby zaradzić tego typu problemom, GUS wylicza coś takiego jak CPI (Consumer Price Index) – indeks zmiany cen towarów i usług konsumpcyjnych. W skrócie mówimy inflacja CPI, czyli inflacja konsumencka. Warto zaznaczyć tutaj jeszcze, że zupełnie inna może być inflacja odczuwana na poziomie budżetów firm (a właściwie dla różnych firm jest także oczywiście różna).
Nie będziemy się tutaj wgryzać zbyt mocno w to jak dokładnie wylicza się inflację CPI. Skupimy się jedynie na paru najważniejszych rzeczach, które przydadzą nam się do późniejszej odpowiedzi na nasz inflacyjny problem;-). Dla zainteresowanych polecam solidniejsze omówienia:
Na nasze potrzeby powiedzmy sobie bardzo prosto, w jaki sposób GUS liczy CPI. Potrzeba do tego podstawowej rzeczy, czyli koszyka inflacyjnego. Taki koszyk to grupy towarów, które podlegają badaniu. GUS oblicza to na podstawie ankiet wysyłanych przez 30 000 osób. Już tutaj powstaje pewien problem – ankiety te mogą być wypełniane nierzetelnie.
Następnie, jeśli mamy już grupy produktów, musimy wiedzieć jak ich ceny zmieniają się w skali całego kraju. Aby to zrobić, wyposażeni w tablety ankieterzy, od 5 do 22 dnia każdego miesiąca, ruszają do akcji – a konkretnie do wytypowanych wcześniej punktów (np. sklepów spożywczych) w konkretnych rejonach. W 2019 roku badanie prowadzono w 207 rejonach w całej Polsce.
Big Data w służbie jej królew… to znaczy w służbie Rządu RP
Taka metodologia prowadzi do bardzo wielu wątpliwości. Badanie GUSu zakrojone jest na bardzo szeroką skalę. Mimo to jednak wciąż są to jedynie wybrane gospodarstwa oraz wybrane punkty sprzedaży. Chcę tutaj podkreślić, że nie podejrzewam naszych statystyków o manipulacje. Może jednak dałoby się zrobić tą samą pracę lepiej, bardziej precyzyjnie i znacznie mniejszym kosztem?
Cyfryzacja paragonowa – czyli jak Rząd przenosi nasze zakupy do baz danych?
Zanim przejdziemy dalej, powiedzmy najpierw coś, z czego być może większość z nas sobie nie zdaje sprawy. Ostatnie lata to stopniowe przechodzenie z tradycyjnych kas fiskalnych na kasy wirtualne oraz online. Na potrzeby artykułu nie będę wyjaśniał różnic. To co nas interesuje to fakt, że oba typy kas, zakupy raportują bezpośrednio do Rządu. Na ten moment objęta jest tym stanem rzeczy gastronomia, ale docelowo ma to objąć (wedle mojej wiedzy) także inne sektory posługujące się paragonami.
Jak zbudować system liczący inflację?
Przenieśmy się mentalnie do momentu, w którym każda, lub niemal każda sprzedaż jest odnotowywana przez państwo i zapisywana w tamtejszej bazie danych (najprawdopodobniej nierelacyjnej). Można to wykorzystać, aby zbudować system, który pozwoli nam liczyć inflację pozbawioną potrzeby wysyłania armii ankieterów. Co więcej – pozwoli to zrobić dokładniej oraz da nam potężne narzędzie analityczne!
Bazy danych / Storage
Przede wszystkim – zakładam, że wszystkie dane trzymane są w jakiejś nierelacyjnej bazie danych – na przykład w Apache HBase. Może to być jednak także rozproszony system plików, jsk HDFS. W takiej bazie powinny być trzymane wszystkie dane dotyczące transakcji – paragony, faktury, JPK itd. Osobną sprawą pozostają informacje dotyczące firm i inne dane, które są bardziej “ogólne” – dotykają mniejszej liczby podmiotów i nie są tak detaliczne.
W nowoczesnym systemie do liczenia inflacji Spark odegrałby kluczową rolę
Te dane, ze względu na niewielką liczbę i bardzo klarowną strukturę, można trzymać w bazie relacyjnej (np. PostgreSQL). Można jednak także jako osobną tabelę HBase, choć z przyczyn analitycznych (o których potem) znacznie lepiej będzie zrobić to w bazie relacyjnej. Można także zastosować rozwiązanie hybrydowe – wszystkie dane dotyczące firm trzymać w bazie nierelacyjnej, jako swoistym “magazynie”, natomiast pewną wyspecyfikowaną, odchudzoną esencję – w bazie relacyjnej.
Dodatkowo zakładam, że koszyk inflacyjny jest już wcześniej przygotowany. Da się ten proces uprościć poprzez informatyzację ankiet – jest to już zresztą robione (według wiedzy jaką mam). Taki koszyk można trzymać w bazie relacyjnej, ze względu na relatywnie niewielką liczbę danych (W 2021 roku zawierał on 12 grup produktów. Nawet jeśli w każdej z nich byłoby parę tysięcy produktów, liczby będą sięgać maksymalnie kilkudziesięciu tysięcy, niezbyt rozbudowanych rekordów).
W dalszej części dodam jeszcze możliwość tworzenia kolejnych koszyków i w takiej sytuacji prawdopodobnie należałoby już je wydzielić do osobnej bazy nierelacyjnej. W dalszym ciągu jednak ogólne adnotacje mogłyby pozostać w bazie relacyjnej (tak, żeby można było np. sprawnie wyciągnąć dane z HBase po rowkey, czyli id).
Jeśli zdecydujemy się na zastosowanie bazy row-key, jak HBase, uważam że i tak zaistnieje potrzeba wykorzystania HDFS (może być tak, że w HBase będzie wygodniej pierwotnie umieszczać pliki paragonowe). Będziemy tu umieszczać kolejne etapy przetworzonych danych z konkretnych okresów.
Jeszcze inną opcją jest zastosowanie Apache Kudu, który mógłby nieco zrównoważyć problemy HBase i HDFS i zastąpić oba byty w naszym systemie. Jak widać, opcji jest dużo;-)
Przygotowanie danych
Kiedy mamy już dane zebrane w przynajmniej dwóch miejscach, powinniśmy je przygotować. Same z siebie stanowią jedynie zbiór danych, głównie tekstowych. W drugim etapie należy te dane przetworzyć, oczyścić i doprowadzić do postaci, w jakiej ponownie będziemy mogli dokonać już finalnej analizy inflacji.
Finałem tego etapu powinny być dane, które będą pogrupowane tak, żebyśmy mogli je później wykorzystać. Wstępna, proponowana struktura wyglądać może następująco:
Okres badania
Grupa produktów
Punkt sprzedaży
towar
Musimy więc wyciągnąć surowe dane (z HBase), przetworzyć je, a następnie zapisać jako osobny zestaw – proponuję tu HDFS. Jak to uczynić? Możemy do tego celu wykorzystać Apache Spark oraz connector HBase Spark przygotowany przez Clouderę. Następnie dane muszą być poddane serii transformacji, dzięki którym dane:
Zostaną wydzielone jako osobne paragony
Zostaną podzielone na produkty
Poddane będą oczyszczeniu z wszelkich “śmieci” uniemożliwiających dalszą analizę
Wykryta zostanie grupa produktów dla każdego z nich
Pogrupowane zostaną po grupie produktów oraz okresie
Na końcu dane zapisujemy do HDFS. Wstępna struktura katalogów:
Dane przygotowane
Dane całościowe
okres
Tutaj umieszczamy plik *.parquet lub *.orc
Liczenie inflacji
Skoro mamy już przygotowane dane, czas policzyć inflację. Do tego celu także wykorzystamy Apache Spark, dzięki któremu możemy w zrównoleglony sposób przetwarzać dane. W najbardziej ogólnym kształcie sprawa wygląda dość prosto:
Łączymy się z bazą danych (relacyjną), w której trzymamy konkretny koszyk
Wybieramy okres za jaki chcemy policzyć inflację
Pobieramy dane z HDFS/Kudu, które okresem odpowiadają [2].
Wybieramy grupy produktów zgodne z koszykiem [1]
Przeliczamy inflację za pomocą danych, które są już solidnie przygotowane.
I teraz ważne: efekt zapisujemy do relacyjnej bazy danych.
Analiza
Czemu akurat do relacyjnej bazy danych? Odpowiedź wydaje się oczywista:
Dane będą niewielkie – choć od raz umożna powiedzieć, że z naszego procesu można wycisnąć więcej niż tylko wynik 6.8% 😉 – jest też sporo rzeczy przy okazji, takie jak jakie produkty wzrosły najmocniej, w jakich regionach, co ma największą zmiennośći itd.
Dane będą solidnie ustrukturyzowane
Dane umieszczone w relacyjnych bazach pozwalają na znacznie lepszą i prostszą analizę.
I właśnie ten trzeci punkt powinien nas zainteresować najmocniej. Można bowiem na klastrze zainstalować jakieś narzędzie BI, spiąć z bazą i… udostępnić analitykom. Takim narzędziem może być (znów open sourcowy) Apache Superset. Przynajmniej na dobry początek. W drugim rzucie należałoby się pokusić o zbudowanie dedykowanej aplikacji analitycznej. To jednak można zostawić na później. Na etap, w którym analitycy będą już zaznajomieni z systemem i będą mogli włączyć się w czynny proces budowy nowego narzędzia.
Rozwój
Wyżej opisałem podstawowy kształt systemu do badania inflacji. Warto jednak nie zatrzymywać się na tym i pomyśleć jak można tą analizę wynieść na wyższy poziom. Podstawową prawdą na temat inflacji jest to, że każdy ma swoją, więc nie da się dokładnie obliczać jak pieniądz traci na wartości. Cóż… dlaczego nie możnaby tego zmienić? Wszak mając do dyspozycji WSZYSTKIE (oczywiście upraszczając) dane, można zrobić “nieskończenie wiele” koszyków inflacyjnych.
Czym mogłoby być te koszyki inflacyjne? Kilka propozycji.
Dlaczego nie wykorzystać rozwoju technologii Big Datowych do podnoszenia świadomości finansowej oraz obywatelskiej Polaków? Niech każdy będzie mógł na specjalnym portalu wyklikać swój własny koszyk i regularnie otrzymywać powiadomienia dotyczące swojej własnej inflacji. Takie podejście byłoby bardzo nowatorskie i z pewnością wybilibyśmy się na tle innych państw.
Koszyki mogą powstawać dla różnych grup społecznych. Dzięki temu można będzie dokładniej badać przyczyny rozwarstwienia społecznego, niż jedynie osławiony współczynnik Giniego, czy także inne, powiedzmy sobie szczerze – skromne narzędzia, na podstawie których wyciągane są bardzo mocne dane.
Koszyki dla firm – oczywistym jest, że firmy mają znacząco różny koszyk od ludzi. Jest oczywiście inflacja przemysłowa (PPI), natomiast dotyczy ona produkcji przemysłowej (i to w dośćwąskim zakresie). Dzięki wyborowi produktów w “naszym systemie” można będzie obliczyć także jak bardzo wartość pieniądza spada dla różnych rodzajów firm.
Potencjalne korzyści
Powyżej opisałem przykładowy system, który pozwoliłby nam wynieść analizę inflacji na zupełnie inny poziom. Poniżej chciałbym zebrać w jedno miejsce kilka najważniejszych korzyści, jakie niosłyby takie zmiany:
Mniejsze koszty – cykliczne uruchamianie jobów mających na celu sprawdzenie inflacji to koszt znacznie mniejszy, niż utrzymywanie armii ankieterów.
Dokładniejsza inflacja – precyzja liczenia inflacji weszłaby na zupełnie inny poziom. Oczywiście na początku należałoby przez kilka lat liczyć w obu systemach, aby sprawdzić jak bardzo duże są różnice.
Różne modele inflacji – a więc koszyki o których pisałem powyżej, które spowodują, że przestanie być prawdziwa teza o tym, że “liczenie prawdziwej inflacji nie jest możliwe”.
Regionalizacja inflacji – Inflacja inflacji nie jest równa. Zupełnie inaczej ceny mogą się kształtować w różnych województwach. Również i to mógłby liczyć “nasz system”.
Większe możliwości analityczne – stopy nie są jedynym narzędziem, który można użyć w walce z inflacją. Ekonomiści wskazują, że poza wysokością stóp procentowych także inne czynniki wpływają na inflację. Są to m.in. skala dodruku pieniądza, rozwój świadczeń socjalnych, regulacje gospodarcze czy wysokość podatków pośrednich. Dzięki Big Datowemu systemowi, Rząd zyskałby znacznie większe możliwości analityczne do śledzenia wpływu swoich zmian na gospodarkę.
Wyższe morale i poczucie, że państwo gra “w pierwszej lidze”– unowocześnia swoje działanie na poziom niespotykany w innych krajach.
Potencjalne zagrożenia
Rozwój zaawansowanych systemów to oczywiście także zagrożenia. O tych najważniejszych poniżej:
Możliwości analityczne muszą wiązać się z większą inwigilacją – i jest to chyba największy problem. Im większe możliwości analizy chcemy sobie zafundować, tym głębiej trzeba zinfiltrować życie obywateli. Oczywiście przed infiltracją współcześnie uciec się nie da, ale należy zawsze mieć na uwadze mądre wyważanie.
Koszt utrzymania systemu – To system zbierania bardzo dużych danych i analizy ich. Wymagać będzie zaawansowanych klastrów obliczeniowych oraz odpowiedniego zespołu administracyjnego. Na pensjach – dodajmy – zdecydowanie rynkowych, nie urzędniczych.
Kwestia bezpieczeństwa – czasami zapominamy, że informatyzacja państwa to problem w bezpieczeństwie danych. Jeśli jesnak dane dotyczące zakupów i tak miałyby być zbierane – czemu ich nie wykorzystać?
Big Data to nasza wielka szansa – także w sektorze rządowym
Jesteśmy Państwem, które w wielu miejscach wiecznie próbuje nadgonić resztę (choć w wielu także tą resztę przegoniło). Big Data może pozwolić na działać lepiej, szybciej, precyzyjniej i… taniej. Wykorzystajmy tą szansę. Za nami poglądowy pomysł na to jak zbudować jeden z takich systemów, które mogłyby pomóc nam budować nowoczesne państwo. Jeśli chcesz dowiadywać się o innych pomysłach, które ukazują Big Data w odpowiednim kontekście, zapraszam na nasz profil LinkedIn oraz do zapisania się na newsletter RDF. Do zobaczenia na szlaku BD!;-)
Transformując firmę w kierunku posiadania kompetencji Big Data stajemy przed podstawowym, bardzo popularnym problemem: jak zbudować naszą infrastrukturę? Zapraszam na skrótowe zestawienie różnic obu podejść.
![Jak wyglądają szkolenia Big Data w RDF? [Wideo]](http://blog.riotechdatafactory.com/wp-content/uploads/2022/09/na-czym-polegają-szkolenia-BD-YT.jpeg "Jak wyglądają szkolenia Big Data w RDF? [Wideo]")
![Jak wygląda klaster Big Data, na którym uczą się kursanci? [Wideo]](http://blog.riotechdatafactory.com/wp-content/uploads/2022/08/klaster-RDF-blog.png "Jak wygląda klaster Big Data, na którym uczą się kursanci? [Wideo]")