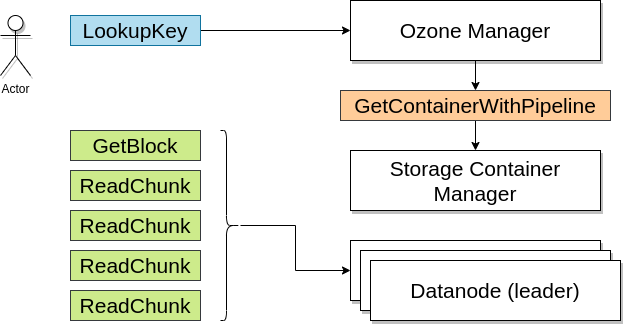
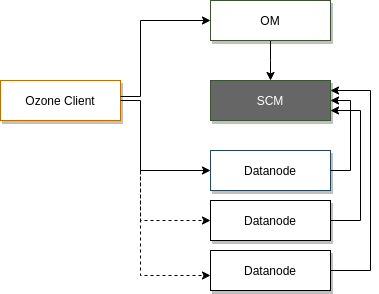
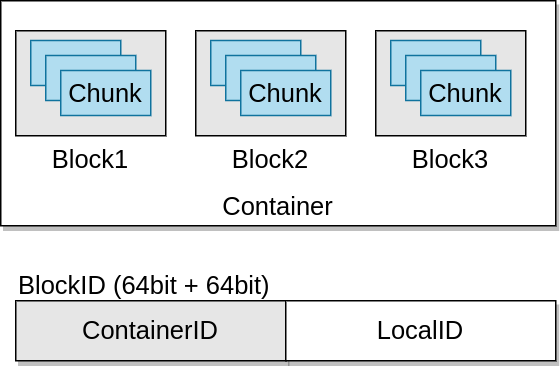
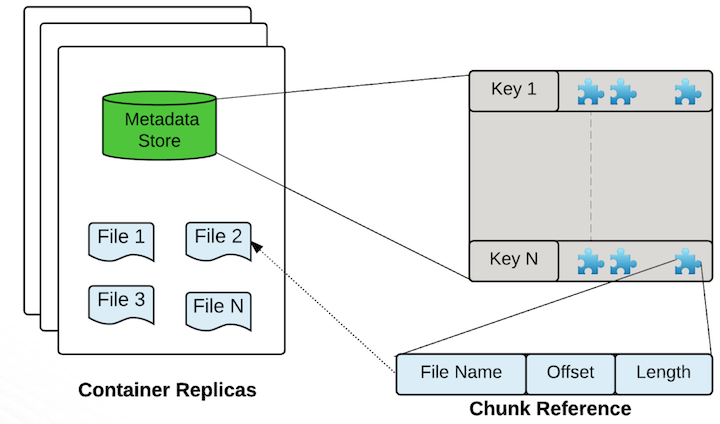
O tym, że Apache Ozone jest mniej podobny do HDFSa niż można przypuszczać, pisałem w artykule o budowie. Ponieważ postanowiłem stworzyć system do gromadzenia i analizy danych giełdowych, musiałem też zbudować nowy eksperymentalny klaster (czy może lepiej: klasterek;-)). Uznałem, że to znakomita okazja, żeby przetestować dość nowy, dojrzewający niczym włoska szynka system do gromadzenia danych: Apache Ozone.
W tym artykule znajdziesz kilka moich obserwacji oraz – co ważniejsze – lekcji. Będą z pewnością przydatne, jeśli także chcesz spróbować swoich sił i zbadać ten teren. Będą przydatne, ponieważ dokumentacja jest wybrakowana i nie odpowiada na wiele pytań, a społeczność… cóż, jeszcze właściwie nie istnieje. Bierz kubek mocnej jak wiedźmiński eliksir kawy – i zanurzmy się w przygodę!
Apache Ozone: obserwacje i informacje
Zacznijmy od mniej istotnej części, czyli moich subiektywnych przemyśleń na temat Apache Ozone. Poniżej 3 najistotniejsze z nich.
- Ozone to nie HDFS. To nawet nie system plików (FS). Opisywałem to już w artykule na temat tego jak Ozone jest zbudowany (o architekturze). Podchodząc do “kontynuacji HDFSa” oczekiwałem podobnego systemu plików, jednak zapewne z nieco inną architekturą. Przeliczyłem się mocno. Ozone bowiem to nie File System, a Object Store. Skutkuje to przede wszystkim bardzo płaską strukturą. Nie zrobimy więc rozbudowanych, hierarchicznych struktur, jak miało to miejsce w HDFSie.
- Ozone ma bardzo, bardzo niewielką społeczność. Co rodzi mocne komplikacje. No właśnie. To jest naprawdę problematyczna część. Warto wziąć poprawkę na termin w jakim to piszę. Apache Ozone jest dostępny w repozytorium głównym Mavena od listopada ubiegłego roku. Wersja GA została (jeśli się nie mylę) udostępniona dopiero w zeszłym roku. To wszystko sprawia, że technologia jest jeszcze mało dojrzała – przynajmniej w obszarze społeczności. Jest to bardzo ciekawy moment dla osób z pionierskim zacięciem;-). Praktycznie żaden błąd na który się natknąłem, nie był nigdzie w Internecie opisany. Rzecz bardzo rzadko spotykana. Chociaż ciekawa!
- Warto od samego początku poznać architekturę. Ja przyznam, że miałem dwa podejścia do Ozona. Za pierwszym razem poległem. Było to spowodowane moją gorącą krwią i chęcią jak najszybszego przetestowania w boju nowej technologii. To błąd! Naprawdę warto przeznaczyć trochę czasu, żeby wgryźć się najpierw w to jak zbudowany jest Apache Ozone. Jeśli tego nie zrobimy, bardzo ciężko będzie rozwiązywać problemy, których trochę po drodze na pewno będzie. Jak już napisałem punkt wyżej – Ozone nie ma właściwie społeczności, więc najpewniej większość opisanych błędów spotkasz… w tym artykule. Aby je rozwiązać po prostu warto wiedzieć jak to wszystko działa:-).
Apache Ozone: problemy, które rozwiązałem
Instalując Apache Ozone napotkałem kilka problemów, które rozwiązałem, a którymi chcę się podzielić. Liczę, że ustrzeże Cię to przed wyrywaniem sobie włosów z głowy z powodu frustracji.
INTERNAL_ERROR Allocated 0 blocks. Requested 1 blocks
Wszystkie serwisy działają, ale plik nie chce się przekopiować z lokalnego systemu plików na Ozone. Podczas kopiowania (polecenie “ozone sh key put /vol1/bucket1/ikeikze2.pdf ikeikze2.pdf”) pojawia się następujący błąd:
INTERNAL_ERROR Allocated 0 blocks. Requested 1 blocks
Co to oznacza? Nie wiadomo. Wiadomo jedynie, że – mówiąc z angielska – “something is no yes”. W tym celu udajemy się do logów. Tu nie chcę zgrywać ozonowego mędrca, więc powiem po prostu: popróbuj. Problem może być w paru logach, ale z całą pewnością ja bym zaczął od logów datanode. Logi znajdują się w folderze “logs”, w folderze z zainstalowanym Ozonem (tam gdzie jest też folder bin, etc i inne).
Przykład ścieżki do logów datanoda:
[ścieżka_do_folderu_gdzie_jest_ozone]/logs/ozone-root-datanode-headnode.log
Problem z liczbą nodów
Zacznijmy od komunikatu błędu, który można dostać po przejrzeniu logów ze Storage Container Manager (SCM).
ERROR org.apache.hadoop.hdds.scm.SCMCommonPlacementPolicy: Unable to find enough nodes that meet the space requirement of 1073741824 bytes for metada
ta and 5368709120 bytes for data in healthy node set. Required 3. Found 1.
Rozwiązanie: Należy zmienić liczbę replik, ponieważ nie mamy wystarczająco dużo datanodów w klastrze, aby je przechowywać (nie mogą być trzymane na tej samej maszynie). Aby to zrobić należy wyłączyć wszystkie procesy Ozone, a następnie zmienić plik ozone-site.xml. Konkretnie zmieniamy liczbę replik. Poniżej rozwiązanie, które na pewno zadziała, ale niekoniecznie jest bezpieczne – zmieniamy liczbę replik na 1, w związku z czym nie wymaga on wielu nodów do przechowywania replik.
<property>
<name>ozone.replication</name>
<value>1</value>
</property>
Szybsze (automatyczne) uruchamianie Ozone
W tym miejscu pokazane jest jak należy stawiać Apache Ozone. Jak widać są dwie ścieżki i tylko jedna z nich nadaje się do czegokolwiek.
- W pierwszej stawiamy każdy serwis osobno: Storage Container Manager, Ozone Manager oraz Datanody. Jest to chociazby o tyle problematyczne, że jeśli mamy tych datanodów dużo, to trzeba by wchodzić na każdy z nich osobno.
- Na szczęście istnieje też opcja uruchamiania wszystkiego jednym skryptem. W tym celu należy uruchomić plik start-ozone.sh znajdujący się w folderze sbin.
Jednak aby to zrobić, należy najpierw uzupełnić konfigurację. Zmiany są dwie:
- Należy dodać kilka zmiennych do pliku ozone-env.sh w folderze “[folder_domowy_ozone]/etc/hadoop“.
- Nalezy utworzyć plik workers wewnątrz tego samego folderu co [1].
Zmienne: tu należy dodać kilka zmiennych wskazujących na użytkowników ozona. Sprawa jest niejasna, bo Ozone przeplata trochę nomenklaturę z HDFS. Ja dodałem obie opcje i jest ok.
export OZONE_OM_USER=root
export OZONE_SCM_USER=root
export OZONE_DATANODE_USER=root
export HDFS_OM_USER=root
export HDFS_SCM_USER=root
export HDFS_DATANODE_USER=root
workers: tutaj dodajemy adresy workerów. Może to oczywiście być także node na którym uruchamiamy inne serwisy.
workernode01.example.com
workernode02.example.com
workernode03.example.com
Po tym wszystkim możemy uruchomić skrypt start-ozone.sh
OM wyłącza się po uruchomieniu klastra
Po uruchomieniu klastra (sbin/start-ozone.sh) Ozone Manager zwyczajnie pada. Kiedy zajrzymy w logi, znajdziemy taki oto zapis:
Ratis group Dir on disk 14dd99c6-de01-483f-ac90-873d71fb5a44 does not match with RaftGroupIDbf265839-605b-3f16-9796-c5ba1605619e generated from service id omServiceIdDefault. Looks like there is a change to ozone.om.service.ids value after the cluster is setup
Były także inne logi, natomiast wiele wskazywało na Ratisa oraz omServiceIdDefault a także ozone.om.service.ids. Jeśli mamy następujący problem, oznacza to, że nasz klaster próbuje automatycznie włączyć tryb HA na Ozon Manager. Ponieważ mi na takim trybie nie zależy (mój klaster jest naprawdę mały i nie miałoby to większego sensu), wprost wyłączyłem HA. Aby to zrobić, należy zmodyfikować ustawienia.
Plik ozone-site.xml (znajdujący się w [katalog ozona]/etc/hadoop/ozone-site.xml)
<property>
<name>ozone.om.ratis.enable</name>
<value>false</value>
</property>
Oczywiście po zaktualizowaniu ozone-site.xml plik powinien być rozesłany na wszystkie nody, a następnie klaster powinien zostać uruchomiony ponownie. Jeśli chcesz skorzystać z trybu HA, wszystkie (chyba;-)) informacje znajdziesz tutaj.
Przy requestach zwykłego użytkownika (nie-roota) wyskakuje błąd o brak dostępów do logów
A więc wszystko już poszło do przodu, spróbowaliśmy z roota (lub innego użytkownika, którym instalowaliśmy Ozone na klastrze) i wszystko było ok. Przynajmniej do czasu, aż zechcemy spróbować podziałać na innym użytkowniku. Wtedy dostajemy taki oto błąd:
java.io.FileNotFoundException: /ozone/ozone-1.2.1/logs/ozone-shell.log (Permission denied)
at java.io.FileOutputStream.open0(Native Method)
at java.io.FileOutputStream.open(FileOutputStream.java:270)
at java.io.FileOutputStream.<init>(FileOutputStream.java:213)
at java.io.FileOutputStream.<init>(FileOutputStream.java:133)
at org.apache.log4j.FileAppender.setFile(FileAppender.java:294)
at org.apache.log4j.FileAppender.activateOptions(FileAppender.java:165)
at org.apache.log4j.DailyRollingFileAppender.activateOptions(DailyRollingFileAppender.java:223)
(...)
log4j:ERROR Either File or DatePattern options are not set for appender [FILE].
Pocieszające jest to, że błąd ten nie oznacza, że polecenie do Ozone nie zostało wykonane. Oznacza jedynie, że nie mamy uprawnień do pliku z logami Ozone Shell. Żeby powiedzieć dokładniej, nie mamy dostępu do zapisu na tym pliku.
Nie jest to więc błąd stricte “Ozonowy”. Jest za to stricte linuxowy – należy nadać użytkownikowi odpowiednie uprawnienia. Można to zrobić na kilka różnych sposobów. Jeśli Twój klaster, podobnie jak mój, jest jedynie klastrem eksperymentalnym, możesz śmiało nadać uprawnienia zapisu “innym użytkownikom” pliku. Wchodzimy do folderu z logami i wpisujemy następującą komendę:
chmod a+rw ozone-shell.log
Podsumowanie
Apache Ozone to naprawdę ciekawa i – mam nadzieję – przyszłościowa technologia. Musi jednak jeszcze trochę wody w Wiśle upłynąć, aby zyskała popularność oraz dojrzałość HDFSa. Zachęcam jednak do eksperymentowania i dzielenia się tutaj wrażeniami;-)
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Razem możemy więcej!
![Hadoop i kod (Java API). Krótki poradnik od 0 [wideo] [jesień]](http://blog.riotechdatafactory.com/wp-content/uploads/2022/11/youtube-miniatura.jpeg "Hadoop i kod (Java API). Krótki poradnik od 0 [wideo] [jesień]")
![HDFS w praktyce – poradnik DLA POCZĄTKUJĄCYCH (HDFS Shell i budowa) [wideo] [jesień]](http://blog.riotechdatafactory.com/wp-content/uploads/2022/10/HDFS-Youtube.jpeg "HDFS w praktyce – poradnik DLA POCZĄTKUJĄCYCH (HDFS Shell i budowa) [wideo] [jesień]")
![Co to jest (i jak działa) Hadoop? DLA KOMPLETNIE ZIELONYCH [Wideo] [jesień]](http://blog.riotechdatafactory.com/wp-content/uploads/2022/10/Youtube.jpeg "Co to jest (i jak działa) Hadoop? DLA KOMPLETNIE ZIELONYCH [Wideo] [jesień]")