



Jeśli jesteś już po lekturze pierwszego artykułu o Second Brain, wiesz, co oznacza to pojęcie i jak budować swój własny system. Ale pewnie zastanawiasz się, co dalej? Znam teorię, ale jak przejść do praktyki? Wszystkiego dowiesz się z dzisiejszego tekstu. Pomysł to tylko początek, teraz potrzebujesz narzędzi, które pomogą Ci wdrożyć go w życie.
Dopasuj narzędzie do swoich potrzeb.
Osoby ceniące sobie prostotę, szybkość i brak zbędnych konfiguracji robią notatki w Notatniku, bo to przecież oczywisty program do notatek. Bardziej zaawansowani używają Worda lub Google Docs. Następny poziom to OneNote, który dla mnie jest strasznie nieintuicyjny i toporny. Po drodze jest mnóstwo innych programów: Apple Notes, Google Keep, Simplenote, Standard Notes, Evernote, Bear, Roam, mem.ai i wiele, wiele innych. Na podstawie researchu, który przeprowadziłem, aby wybrać program dla siebie, wyłoniłem trzy, moim subiektywnym zdaniem, najlepsze aplikacje: Notion, Logseq i Obsidian. Szybko przejrzyjmy ich wady i zalety – może to pomoże Ci podjąć decyzję:
Notion
Zalety:
- Wszechstronność: Możliwość tworzenia baz danych, tablic Kanban, kalendarzy i innych.
- Szablony: Duża liczba dostępnych szablonów do różnych zastosowań.
- Współpraca: Możliwość współdzielenia notatek i pracy zespołowej.
Wady:
- Krzywa nauki: Może być przytłaczający dla nowych użytkowników.
- Brak pełnej kontroli nad danymi: Wszystkie notatki są przechowywane w chmurze Notion.
Logseq
Zalety:
- Open Source: Aplikacja jest open source, co daje pełną kontrolę nad danymi.
- Zaawansowane linkowanie: Możliwość tworzenia wzajemnych linków między notatkami.
- Interfejs oparty na Markdown: Prosty i intuicyjny interfejs oparty na Markdown.
Wady:
- Krzywa nauki: Może być trudny do opanowania dla nowych użytkowników.
- Brak aplikacji mobilnej: Ograniczone wsparcie dla urządzeń mobilnych.
Obsidian
Zalety:
- Lokalne przechowywanie danych: Notatki przechowywane są lokalnie na dysku użytkownika.
- Zaawansowane funkcje linkowania notatek: Możliwość tworzenia wzajemnych powiązań między notatkami.
- Bogata biblioteka wtyczek: Możliwość dostosowania aplikacji do własnych potrzeb za pomocą licznych wtyczek.
- Interfejs oparty na Markdown: Również posiada prosty i intuicyjny interfejs oparty na Markdown
Wady:
- Krzywa nauki: Dla nowych użytkowników interfejs może być przytłaczający.
- Słaba aplikacja mobilna: Aplikacja jest słabo dostosowana do pracy na tak małych ekranach jakie posiadają smartphone’y.
Ja wybrałem Obsidian, choć długo wahałem się między nim a Logseq. Zdecydowałem się na Obsidian, ponieważ chciałem mieć wszystko u siebie na dysku, a w 99% przypadków buduję i używam mojej bazy wiedzy w domowym zaciszu. Koniec oklepanych folderów, przyszedł czas na uporządkowany chaos!
Nie wpadnij w pułapkę…
Wybrałeś aplikację, zaczynasz działać i przechodzisz z papieru na komputer. Jakie są ryzyka? Pierwsza sprawa – teraz masz wszystko w jednym miejscu, wszystko wydaje się prostsze, więc zaczynasz zbierać. Zamiast uporządkować ciekawe informacje, zaczynasz pochłaniać ich dużo więcej, przez co Twój drugi mózg nie będzie działać tak, jak powinien. Ockniesz się za miesiąc lub dwa z masą nieuporządkowanych artykułów i nie będziesz pamiętać, po co je zapisałeś i co chciałeś z tego wyciągnąć. Na to nie ma złotego środka – musisz sam nad sobą panować.
Drugim ryzykiem jest słynny przerost formy nad treścią. Obsidian ma ogromną głębię i możliwości personalizacji. Przyjdzie moment, w którym usiądziesz i zaczniesz się zastanawiać, czy na pewno porządkujesz wszystko idealnie. Czy wszystko jest tak, jak być powinno? Linia odgradzająca efektywność od efektowności jest cienka i bardzo łatwo ją przekroczyć. W rezultacie możesz skończyć z pięknym programem, pełnym kolorów, szablonów i różnych wymyślnych funkcji, ale bez merytorycznej treści w środku.
Pamiętaj, dążysz do ideału, ale nie licz, że go osiągniesz. Lepiej mieć gorszy system, ale działający długi czas, niż co miesiąc wywracać wszystko do góry nogami, bo u kogoś widziałeś coś ciekawego i chcesz to mieć u siebie. Nie chodzi o to, żeby nie zmieniać i nie ulepszać, ale jeśli chcesz wprowadzić coś nowego, nie poświęcaj godzin lub dni, żeby wdrożyć to we wszystkich notatkach. Zacznij wprowadzać nowości dla swoich nowych notatek, a z czasem, jeśli będziesz używać tego, co już znajduje się w Twoim skarbcu, będziesz mógł odświeżyć każdą starą notatkę, do której zajrzysz prędzej czy później.
Są też bardziej przyziemne i oczywiste ryzyka. Nie trzymaj w takim miejscu haseł, numerów kont itp., szczególnie jeśli wybierzesz program działający w chmurze.
3, 2, 1, Start!
Wybór za Tobą, więc zaczynamy. Niezależnie od tego, czy wybrałeś Obsidian, czy inny program, pierwszy krok jest zawsze ten sam – zainstaluj aplikację lub utwórz konto. Dalsza część będzie dotyczyć wyłącznie Obsidiana. Jeśli wybrałeś inny program, musisz poszukać odpowiednich informacji gdzie indziej, ale zachęcam do dalszej lektury. Może znajdziesz coś ciekawego, a jeśli nie, to przynajmniej zobaczysz, jak działa Obsidian.
Pobraliśmy i zainstalowaliśmy nasz program. Teraz uruchamiamy go i wybieramy miejsce, gdzie znajdzie się nasz vault (czyli nasza baza). Najlepiej utworzyć nowy folder, ponieważ znajdzie się tam kilka różnych elementów. W wybranej lokalizacji pojawi się folder z ustawieniami programu, gdzie będą zapisane wszystkie wtyczki, motywy itd. Ponadto, jeśli w naszej bazie pojawią się foldery, to również będą one w tej lokalizacji (jakie foldery proponuję utworzyć, dowiesz się za chwilę). Jeśli nie, w tym miejscu będą zapisane nasze notatki w formacie .md.
Następnie możesz zacząć tworzyć. Edytor tekstu wygląda nieco inaczej niż Word – działamy w formacie Markdown. Jeśli to Twój debiut z Markdownem, polecam poświęcić 5 minut na przeczytanie jakiegoś poradnika. Najważniejsze rzeczy wymienię poniżej:
- Hashtagi: W zależności od liczby znaków “#” tworzymy różne poziomy nagłówków. Jeden hash to największa czcionka, a każdy kolejny hash zmniejsza rozmiar nagłówka. Hash musi być oddzielony od tekstu spacją, inaczej tworzymy tag, a nie nagłówek. Wszystkie nagłówki pojawiają się również w oknie nawigacji notatki.
- Gwiazdki: Używane do pochylania i pogrubiania tekstu. Jedna gwiazdka pochyla, dwie pogrubiają, a trzy robią obie te rzeczy jednocześnie.
- Nawias kwadratowy: Podwójny nawias kwadratowy to absolutny gamechanger. Dzięki niemu linkujemy się do innej notatki, istniejącej lub nie.
- Myślnik i spacja: Tworzą listę punktów.
- Cyfra z kropką: Tworzą listę numerowaną.
Jest jeszcze mnóstwo innych opcji, o których można poczytać w dokumentacji Obsidiana, do czego gorąco zachęcam. Te wymienione powyżej w zupełności wystarczą na start.

Funkcje, które musisz znać!
Najważniejsza podstawa, która wyróżnia ten program to wspomniane wcześniej linkowanie notatek. Dzięki tej funkcjonalności nie potrzeba nam grupowania notatek w foldery i zastanawiania się czy jakaś notatka bardziej pasuje do kategorii A czy do kategorii B. Po prostu tworzysz daw linki do MOC’a A i MOC’a B i sprawa załatwiona. Niby to takie proste i intuicyjne, ale jak widać nie jest to standardem.
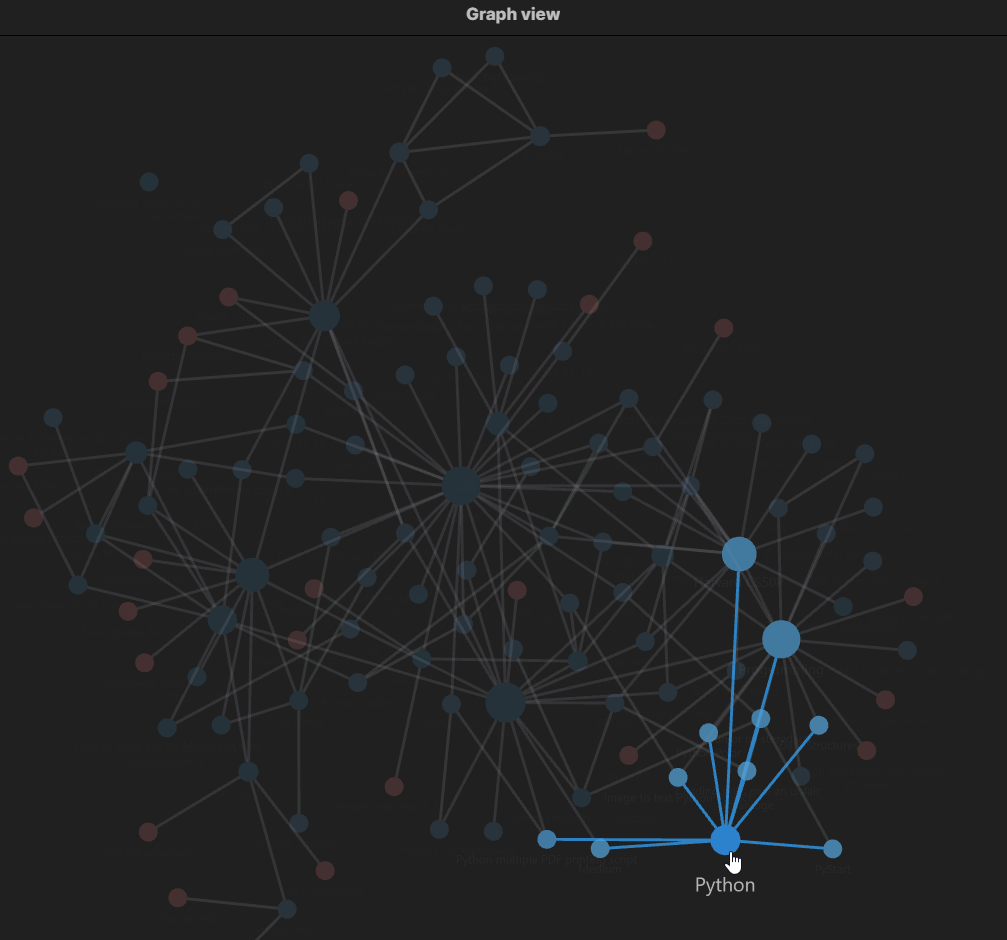
Ale co dalej z tymi linkami? Tutaj właśnie pojawia się widok grafu, dzięki któremu możemy przejrzeć nasze materiały niczym neurony połączone w mózgu. W tym miejscu tkwi największy benefit linków – oczywiście, możesz przechodzić wewnątrz notatek między nimi, ale wtedy nie widzisz całości. Natomiast na grafie, po utworzonych połączeniach, możesz praktycznie natychmiast przejść z notatki A do notatki B, C, D, czy nawet Y. Jednym zdaniem, widzisz wszystkie możliwe powiązania.
Dodatkowo możesz podświetlić notatkę i wszystkie jej powiązania, przeszukiwać graf lub włączać widok grafu tylko dla wybranej grupy. Możliwości jest wiele, ale przytoczmy jakiś przykład: Uczysz się Scali i jesteś w obszarze typowania. Masz już w swojej bazie wiedzy rozpisany temat typowania w Pythonie, który znasz bardzo dobrze. Możesz połączyć obie notatki i nie będziesz musiał przekopywać się przez cały stos treści. Utrwalając wiedzę, masz od razu odniesienie do przykładów z obu języków.
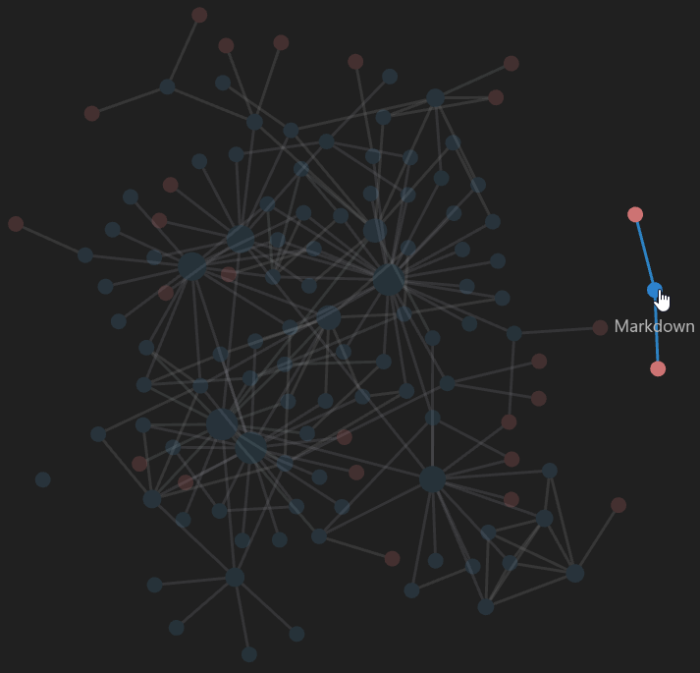
Innym przykładem może być notatka teoretyczna na temat przetwarzania strumieniowego. Taką notatkę możesz linkować do notatek na temat konkretnych narzędzi wykorzystujących przetwarzanie strumieniowe, które będą zawierać przykłady, fragmenty kodu itd.
Również ciekawym sposobem wykorzystania połączeń w nauce tak obszernego tematu jak Big Data może być rozpisanie case study i połączenie go z konkretnymi technologiami i koncepcjami. W tym przypadku jesteś o jedno kliknięcie od gotowego przykładu zastosowania konkretnego narzędzia..
Oczywiście, jeśli nie chcesz używać linkowania, zawsze możesz pozostać przy starych, sprawdzonych folderach. Foldery nie są aż tak złe, jak je przedstawiam w tej krótkiej serii artykułów. Moim sposobem wykorzystania folderów jest grupowanie konkretnych elementów bazy wiedzy. Posiadam folder na załączniki (zapisują się w nim wszystkie wklejane obrazy), folder na dziennik, kolejny, w którym mam wszystkie Maps of Content (MOC), folder na notatki i projekty. Ostatni, i w sumie najważniejszy, jest folder na szablony (templates). Oczywiście, wykorzystanie klasycznych folderów można łączyć w dowolny sposób z linkowaniem – możemy posiadać połączone notatki z wielu różnych folderów.
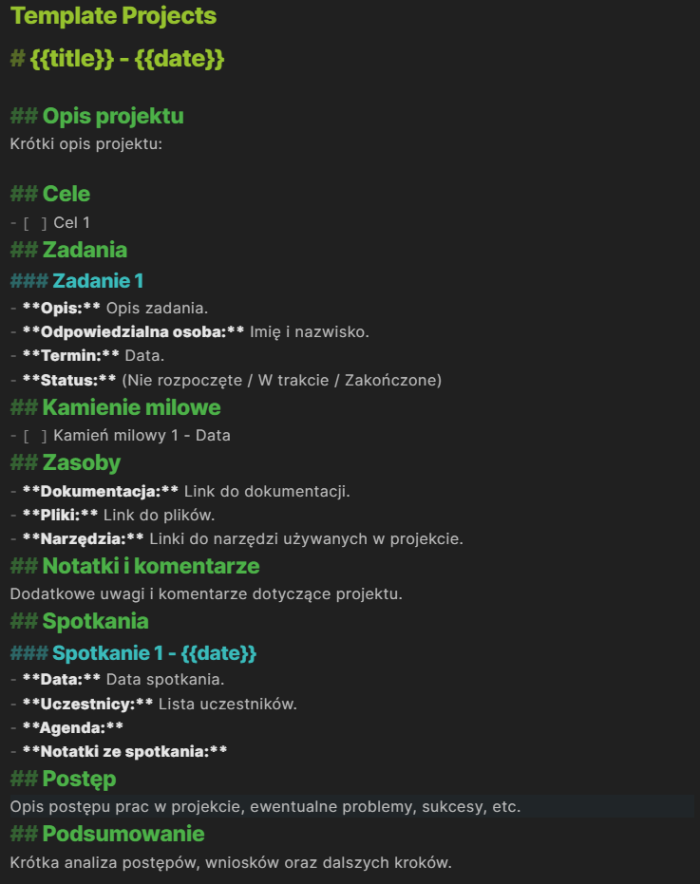
Kolejną funkcją, która bardzo usprawnia pracę, są szablony. W tym aspekcie nie ma nic odkrywczego – po prostu możesz tworzyć szablon na każdą okazję. Jak zwykle proponuję zachować umiar. Polecam szablon na notatki teoretyczne, case study, projekty, szablon MOC i szablon na notatki do dziennika. Podczas tworzenia nowej notatki możesz wywołać dany szablon, a wtedy pozostaje Ci tylko wypełnienie treścią wcześniej zaprojektowanego układu. Co według mnie jest totalnym minimum, które powinno znaleźć się w szablonie? Trzy rzeczy: tytuł, up (czyli notatka nad tą notatką – najczęściej MOC lub jakaś notatka zbierająca wszystkie z konkretnego obszaru, np. Scala) oraz pokrewne notatki, gdzie dodamy linki do wszystkich powiązanych notatek.
Co jeszcze oferuje nam Obsidian?
- Tagowanie: Można używać tagów do dodatkowego oznaczania swoich notatek, ale nie jest to konieczne.
- Wyszukiwanie i filtrowanie: Mamy do dyspozycji zaawansowaną wyszukiwarkę, która umożliwia wyszukiwanie po ścieżce, tagach, nazwach plików, słowach kluczowych itd.
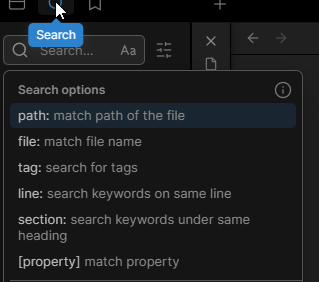
Wyszukiwarka notatek. - Synchronizacja i publikacja: Opcje płatne, które pozwalają na synchronizację notatek na wielu urządzeniach. Można to zastąpić darmowym dyskiem w chmurze typu Google Drive lub za pomocą Git’a. Publikacja pozwala na wrzucanie pojedynczych notatek lub całych grup na Obsidian Publish, gdzie każdy posiadający link może poruszać się po notatkach.
- Canvas: Wizualne organizowanie notatek, przydatne do tworzenia map myśli.
- Code snippets: Bardzo przydatna funkcja do nauki programowania. Można pisać kod w przeznaczonym do tego formatowaniu, wspierane są różne języki, w tym Python, SQL, Java.

Code snipet. - Podgląd na żywo: Mamy tryb czytania i pisania, a także podgląd na żywo, gdzie tekst natychmiast się formatuje podczas pisania w Markdown.
- Zaawansowane formatowanie: Poza tekstem można tworzyć tabele, wzory matematyczne itd.
- Obsługa wielu paneli jednocześnie: Możliwość otwarcia wielu notatek oraz podglądu widoku grafu jednocześnie.
- Tryb skupienia: Możliwość włączenia trybu skupienia, który wyświetla tylko notatkę, ograniczając wszystkie inne okna typu graf, wyszukiwanie, struktura folderów itd.
I mnóstwo innych funkcji, o których możesz poczytać w dokumentacji lub obejrzeć na YouTube. Ponadto Obsidiana można rozbudowywać za pomocą wtyczek społeczności, których są tysiące. To jednak temat na inny raz.
Jeśli nie wszystko wydaje Ci się w 100% jasne, nic nie szkodzi. Działaj i wracaj do tego artykułu w trakcie, wtedy na pewno wyciągniesz z niego jak najwięcej.
Mam nadzieję, że po przeczytaniu obu artykułów o budowaniu bazy wiedzy posiadasz już wystarczającą ilość informacji, aby usiąść przed komputerem już dziś i zacząć działać. Wyposażyłem Cię w ogólny zarys bazy wiedzy, przedstawiłem najważniejsze koncepcje, funkcjonalności oraz plan, jak zacząć. Więc nie czekaj – zacznij już teraz, ale pamiętaj, żeby nie wpaść w żadną z pułapek!
Koniecznie daj znać, jak podobała Ci się ta mini seria artykułów i czy będziesz budować swoją bazę wiedzy! Znajdziesz mnie również na LinkedIn, więc jeżeli chcesz się podzielić spostrzeżeniami, o coś zapytać, a może masz jakieś uwagi, to pisz – chętnie zamienię z Tobą parę zdań.
Na koniec jeszcze dwa krótkie wyjaśnienia. Ten artykuł nie był sponsorowany przez twórców aplikacji Obsidian.md. Kolory pokazane na załączonych grafikach są efektem motywu “Blue Topaz”.
Zostań na dłużej z RDF!
Zostań na dłużej z Riotech Data Factory! Dołącz do newslettera “Na Szlaku Big Data”, żeby kompleksowo eksplorować świat wielkich danych. Jak widać, Big Data to nie tylko programowanie, ale także umiejętności “miękkie”, takie jak efektywna nauka, czy katologowanie swojej własnej wiedzy!



![Jak nauczyć się Apache Solr? Krok po kroku [Mapa drogowa]](https://blog.riotechdatafactory.com/wp-content/uploads/2023/10/laptop-z-kursem-mockuper-768x350.png "Jak nauczyć się Apache Solr? Krok po kroku [Mapa drogowa]")





![Jak oczyścić dane w sparku? Castowanie, funkcje, nulle, regexpy itd. [wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2023/01/YT-1.png "Jak oczyścić dane w sparku? Castowanie, funkcje, nulle, regexpy itd. [wideo]")
![Jak załadować dane do Apache Spark? [Wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2023/01/YT.png "Jak załadować dane do Apache Spark? [Wideo]")
![“Fundament Apache Spark” już dostępny! Jak wygląda pierwszy polski kurs o Sparku? [Wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2023/01/ikona.png "“Fundament Apache Spark” już dostępny! Jak wygląda pierwszy polski kurs o Sparku? [Wideo]")