Właśnie skończyłem kolejne szkolenie (nie byle jakie, bo to było 2-miesięczne, kompleksowe – serio, hardcore). Uświadomiło mi ono jedną bardzo konkretną rzecz w kontekście naszego zrozumienia systemów Big Data. Chciałem się nią podzielić. Artykuł przede wszystkim do technicznych, ale… nie tylko. Zdecydowanie nie tylko.
Złożoność – nasz główny wróg
Podchodząc do systemu przetwarzania bardzo dużych ilości danych, mamy jednego podstawowego wroga. Staje przed nami niczym behemot już na poziomie koncepcji. Jest to… stopień złożoności problemu. Przyznajmy szczerze – nie lubimy złożonych problemów. Ani w życiu prywatnym, ani zawodowym. Aby rozwiązać taki problem, należy wytężyć mózgownicę do takich granic, które u niektórych powodują niemały ból.
Szczególnie daje się to we znaki, gdy ktoś przeszedł do Big Data z “tradycyjnej IT”. Jeśli robiłeś wcześniej aplikacje webowe, możesz doznać szoku. I nie mówię nawet o tym, że dotychczas wszystkie Twoje problemy zawarte były w jednym pliku z logami, podczas gdy tutaj nawet pojedyncza technologia ma kilka serwisów, a każdy z nich swoje własne logi.
Po prostu złożoność jest inna. Robiąc aplikację webową (zostańmy przy tym), mam jasne wytyczne, standardy i zwykle prostą ścieżkę, którą uruchamia (najczęściej) użytkownik. Wejdziemy pod odpowiedni adres? W takim razie musimy wysłać zapytanie do bazy danych, dokonać kilku obliczeń i wyrenderować stronę końcową.
Gorzej, jeśli trzeba zbudować cały skomplikowany system, a wejście (rozumiane jako input)… cóż, wejścia czasami nie ma. Albo jest ich bardzo, bardzo wiele. Albo – co gorsza – jest wejście, wyglądające bardzo “tradycyjnie”(np. request użytkownika).
Jak zaprojektować system – problem złudnego “wejścia” (inputu)
Przypuśćmy taką prostą sytuację. Robimy aplikację-wyszukiwarkę filmów związanych z danymi miastami. W efekcie wpiszemy nazwę miasta, a otrzymujemy listę miast, które w ten czy inny sposób dotyczą go (czy to w kontekście tematyki czy lokalizacji).
Bardzo łatwo w takiej sytuacji zacząć całe projektowanie wychodząc od użytkownika i mając przeświadczenie, że to on musi uruchamiać całą machinę. No świetnie, zatem wcielmy się w taką rolę. Użytkownik wpisuje nazwę miasta i… i co? Czy mam teraz starać się wyszukiwać po internecie wszystkich możliwych informacji? Byłoby to całkiem, całkiem długotrwałym procesem.
No dobrze, więc może zacząć zbierać oraz przetwarzać dane, osobno? Pomysł dobry. Jednak i tutaj można łatwo wpaść w pułapkę wąskiego myślenia. Ciągle mamy z tyłu głowy użytkownika, więc zaczynają powstawać dziwne pomysły, na uruchamianie przetwarzania po wykonanym requeście, w trakcie itd. Ciągle mamy tą manierę, że staramy się wychodzić od jednego punktu i przejść przez wszystkie elementy systemu. To trochę tak, jakbyśmy starali się złapać bardzo dużo drewnianych klocków na raz. Nie ma szans – wypadnie. Kto próbował ekspresowo posprzątać po zabawach swoich dzieci u Dziadków, wie o co chodzi.
Słowo klucz: decentralizacja
Prowadząc szkolenie, gdzieś w połowie zorientowałem się, że coś jest nie tak. Zbadałem temat i zauważyłem, że kursanci bardzo dziwnie podeszli do budowy modułów. Chodziło konkretnie o te podstawowe rzeczy, jakimi jest wejście i wyjście aplikacji (input i output) oraz zarządzanie całością. Zasadniczo cały projekt opierał się oczywiście o bardzo wiele mniejszych modułów. Niektóre pobierały dane z internetu, inne te dane czyściły i przetwarzały. Jeszcze inny moduł – streamingowy – służył do kontaktu użytkownika z systemem.
W pewnym momencie, po raz kolejny dostałem pytanie, które brzmiało mniej więcej tak: “No, skoro mamy mnóstwo małych modułów, to chyba musimy też gdzieś zbudować skrypt, który to wszystko uruchamia prawda?“. Uznałem, że czas na radykalną zmianę myślenia, przerwanie “starego” paradygmatu i zrozumienia o co chodzi w systemach do przetwarzania i obsługi dużych danych.
Myśl po nowemu – czyli jak poprawnie patrzeć na systemy Big Data?
Oczywiście nie ma jednej złotej zasady, dzięki której zrozumiemy “filozofię Big Data”. Jest jednak coś, czego zrozumienie może być przełomem. Pozwoli wygrać ze złożonością, pozwoli zrozumieć duży, skomplikowany system. Pomoże – wreszcie – przestać siwieć (albo, jak w moim przypadku jest – łysieć) z frustracji.
Otóż, chodzi o magiczne słowo: decentralizacja. Nie, mowa nie o technologii blockchain;-). Chodzi o umiejętność spojrzenie na cały system metodą “od ogółu do szczegółu” i zrozumienie poszczególnych elementów (modułów lub powiązań między nimi). Spójrzmy na kilka kwestii, które to tłumaczą.
Każdy wielki system zbudowany jest z wielu mniejszych (co nie znaczy małych) modułów. Na etapie rozumienia całości, nie musimy wgłębiać się w technikalia czy implementację. Wystarczy nam ogólna wiedza o tym co dany moduł przyjmuje, a co zwraca (jakie jest jego zadanie). Dodatkowo jeśli wiemy z jakimi modułami łączy się (bezpośrednio, lub na poziomie logicznym) to już w ogóle bardzo dużo.
Każdy moduł ma swoje zadanie. Niekoniecznie musi być zależne od innych modułów! Przykładowo, jeśli potrzeba nam w systemie pogody, to potrzeba nam pogody. Nie musimy wiązać tego z modułem, który pobiera filmy, albo składuje requesty od użytkownika. W momencie rozumienia modułu od pogody, musimy zbudować mechanizmy pobierające pogodę. Jak to zrobimy? Z wykorzystanie pythona, javy? A może Nifi?
Każdy moduł może być uruchamiany niezależnie od użytkownika. I tutaj musimy znać miejsce takiego podsystemu w systemie.
Jeśli jest niezależny od czegokolwiek – wystarczy prosty skrypt oraz jakiś scheduler, typu Airflow czy Oozie. Pogodę możemy pobierać co godzinę niezależnie od wszystkiego.
Jeśli jest zależny, musimy wiedzieć w jaki sposób jest zależny. Znów najprawdopodobniej użyjemy schedulera, ale pewnie uzależnimy go od wyników innych modułów (jeśli dane nie zostały pobrane, nie ma sensu uruchamiać czyszczenia).
Może się okazać, że moduł naprawdę jest w ścisłym kontakcie z użytkownikiem. W takiej sytuacji, po prostu musimy to dobrze umieścić.
Gdy pracujemy z danym modułem, możemy się zagłębić w szczegóły, a jednocześnie “zapomnieć” o reszcie systemu. Gdy – znów – zaciągamy dane pogodowe, nie musimy myśleć o tym jak one potem zostaną wykorzystane. Dzięki temu usuwamy element, który nas przytłacza. Aby to zrobić – to istotne – powinniśmy wcześniej dobrze zaprojektować całość, łącznie z szczegółowo opisanym wyjściem (output’em). Jakie dokładnie dane pogodowe muszę zwrócić? Gdzie je zapisać? Do jakiej tabeli? Z jaką strukturą? To wszystko powinno być spisane na etapie projektowania, przed implementacją.
Podsumowanie
Tak więc, wracając do problemu ze szkolenia – nie, nie musimy mieć żadnego skryptu, który uruchamia moduły jeden po drugim. Wręcz byłoby to zabiciem idei. Moduły za to powinniśmy uruchamiać w którymś z wyspecjalizowanych schedulerów (polecam Airflow). Dzięki nim możemy przeznaczyć do regularnego startu konkretny moduł, albo połączyć go z innymi. Do tego możemy obsłużyć różne wyniki (np. wysłać email, jeśli coś pójdzie nie tak), przejrzeć logi itd.
Zdaję sobie sprawę, że to co przedstawiłem powyżej, dla wielu jest banałem. Jest jednak taki etap (na początku), gdy trzeba “przeskoczyć” na inne myślenie. I warto zacząć właśnie od kwestii decentralizacji.
Między innymi takich rzeczy, poza stricte technicznymi, uczę na naszych RDFowych szkoleniach. Przejrzyj te, które możemy dla Was zrobić, a potem przekonaj szefa, że solidnie wykwalifikowany zespół, to lepsze wyniki firmy;-).
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Razem możemy więcej!
O tym, że Apache Ozone jest mniej podobny do HDFSa niż można przypuszczać, pisałem w artykule o budowie. Ponieważ postanowiłem stworzyć system do gromadzenia i analizy danych giełdowych, musiałem też zbudować nowy eksperymentalny klaster (czy może lepiej: klasterek;-)). Uznałem, że to znakomita okazja, żeby przetestować dość nowy, dojrzewający niczym włoska szynka system do gromadzenia danych: Apache Ozone.
W tym artykule znajdziesz kilka moich obserwacji oraz – co ważniejsze – lekcji. Będą z pewnością przydatne, jeśli także chcesz spróbować swoich sił i zbadać ten teren. Będą przydatne, ponieważ dokumentacja jest wybrakowana i nie odpowiada na wiele pytań, a społeczność… cóż, jeszcze właściwie nie istnieje. Bierz kubek mocnej jak wiedźmiński eliksir kawy – i zanurzmy się w przygodę!
Apache Ozone: obserwacje i informacje
Zacznijmy od mniej istotnej części, czyli moich subiektywnych przemyśleń na temat Apache Ozone. Poniżej 3 najistotniejsze z nich.
Ozone to nie HDFS. To nawet nie system plików (FS). Opisywałem to już w artykule na temat tego jak Ozone jest zbudowany (o architekturze). Podchodząc do “kontynuacji HDFSa” oczekiwałem podobnego systemu plików, jednak zapewne z nieco inną architekturą. Przeliczyłem się mocno. Ozone bowiem to nie File System, a Object Store. Skutkuje to przede wszystkim bardzo płaską strukturą. Nie zrobimy więc rozbudowanych, hierarchicznych struktur, jak miało to miejsce w HDFSie.
Ozone ma bardzo, bardzo niewielką społeczność. Co rodzi mocne komplikacje. No właśnie. To jest naprawdę problematyczna część. Warto wziąć poprawkę na termin w jakim to piszę. Apache Ozone jest dostępny w repozytorium głównym Mavena od listopada ubiegłego roku. Wersja GA została (jeśli się nie mylę) udostępniona dopiero w zeszłym roku. To wszystko sprawia, że technologia jest jeszcze mało dojrzała – przynajmniej w obszarze społeczności. Jest to bardzo ciekawy moment dla osób z pionierskim zacięciem;-). Praktycznie żaden błąd na który się natknąłem, nie był nigdzie w Internecie opisany. Rzecz bardzo rzadko spotykana. Chociaż ciekawa!
Warto od samego początku poznać architekturę. Ja przyznam, że miałem dwa podejścia do Ozona. Za pierwszym razem poległem. Było to spowodowane moją gorącą krwią i chęcią jak najszybszego przetestowania w boju nowej technologii. To błąd! Naprawdę warto przeznaczyć trochę czasu, żeby wgryźć się najpierw w to jak zbudowany jest Apache Ozone. Jeśli tego nie zrobimy, bardzo ciężko będzie rozwiązywać problemy, których trochę po drodze na pewno będzie. Jak już napisałem punkt wyżej – Ozone nie ma właściwie społeczności, więc najpewniej większość opisanych błędów spotkasz… w tym artykule. Aby je rozwiązać po prostu warto wiedzieć jak to wszystko działa:-).
Apache Ozone: problemy, które rozwiązałem
Instalując Apache Ozone napotkałem kilka problemów, które rozwiązałem, a którymi chcę się podzielić. Liczę, że ustrzeże Cię to przed wyrywaniem sobie włosów z głowy z powodu frustracji.
Wszystkie serwisy działają, ale plik nie chce się przekopiować z lokalnego systemu plików na Ozone. Podczas kopiowania (polecenie “ozone sh key put /vol1/bucket1/ikeikze2.pdf ikeikze2.pdf”) pojawia się następujący błąd:
Co to oznacza? Nie wiadomo. Wiadomo jedynie, że – mówiąc z angielska – “something is no yes”. W tym celu udajemy się do logów. Tu nie chcę zgrywać ozonowego mędrca, więc powiem po prostu: popróbuj. Problem może być w paru logach, ale z całą pewnością ja bym zaczął od logów datanode. Logi znajdują się w folderze “logs”, w folderze z zainstalowanym Ozonem (tam gdzie jest też folder bin, etc i inne).
Zacznijmy od komunikatu błędu, który można dostać po przejrzeniu logów ze Storage Container Manager (SCM).
ERROR org.apache.hadoop.hdds.scm.SCMCommonPlacementPolicy: Unable to find enough nodes that meet the space requirement of 1073741824 bytes for metada
ta and 5368709120 bytes for data in healthy node set. Required 3. Found 1.
Rozwiązanie: Należy zmienić liczbę replik, ponieważ nie mamy wystarczająco dużo datanodów w klastrze, aby je przechowywać (nie mogą być trzymane na tej samej maszynie). Aby to zrobić należy wyłączyć wszystkie procesy Ozone, a następnie zmienić plik ozone-site.xml. Konkretnie zmieniamy liczbę replik. Poniżej rozwiązanie, które na pewno zadziała, ale niekoniecznie jest bezpieczne – zmieniamy liczbę replik na 1, w związku z czym nie wymaga on wielu nodów do przechowywania replik.
W tym miejscu pokazane jest jak należy stawiać Apache Ozone. Jak widać są dwie ścieżki i tylko jedna z nich nadaje się do czegokolwiek.
W pierwszej stawiamy każdy serwis osobno: Storage Container Manager, Ozone Manager oraz Datanody. Jest to chociazby o tyle problematyczne, że jeśli mamy tych datanodów dużo, to trzeba by wchodzić na każdy z nich osobno.
Na szczęście istnieje też opcja uruchamiania wszystkiego jednym skryptem. W tym celu należy uruchomić plik start-ozone.sh znajdujący się w folderze sbin.
Jednak aby to zrobić, należy najpierw uzupełnić konfigurację. Zmiany są dwie:
Należy dodać kilka zmiennych do pliku ozone-env.sh w folderze “[folder_domowy_ozone]/etc/hadoop“.
Nalezy utworzyć plik workers wewnątrz tego samego folderu co [1].
Zmienne: tu należy dodać kilka zmiennych wskazujących na użytkowników ozona. Sprawa jest niejasna, bo Ozone przeplata trochę nomenklaturę z HDFS. Ja dodałem obie opcje i jest ok.
Po tym wszystkim możemy uruchomić skrypt start-ozone.sh
OM wyłącza się po uruchomieniu klastra
Po uruchomieniu klastra (sbin/start-ozone.sh) Ozone Manager zwyczajnie pada. Kiedy zajrzymy w logi, znajdziemy taki oto zapis:
Ratis group Dir on disk 14dd99c6-de01-483f-ac90-873d71fb5a44 does not match with RaftGroupIDbf265839-605b-3f16-9796-c5ba1605619e generated from service id omServiceIdDefault. Looks like there is a change to ozone.om.service.ids value after the cluster is setup
Były także inne logi, natomiast wiele wskazywało na Ratisa oraz omServiceIdDefault a także ozone.om.service.ids. Jeśli mamy następujący problem, oznacza to, że nasz klaster próbuje automatycznie włączyć tryb HA na Ozon Manager. Ponieważ mi na takim trybie nie zależy (mój klaster jest naprawdę mały i nie miałoby to większego sensu), wprost wyłączyłem HA. Aby to zrobić, należy zmodyfikować ustawienia.
Plik ozone-site.xml (znajdujący się w [katalog ozona]/etc/hadoop/ozone-site.xml)
Oczywiście po zaktualizowaniu ozone-site.xml plik powinien być rozesłany na wszystkie nody, a następnie klaster powinien zostać uruchomiony ponownie. Jeśli chcesz skorzystać z trybu HA, wszystkie (chyba;-)) informacje znajdziesz tutaj.
Przy requestach zwykłego użytkownika (nie-roota) wyskakuje błąd o brak dostępów do logów
A więc wszystko już poszło do przodu, spróbowaliśmy z roota (lub innego użytkownika, którym instalowaliśmy Ozone na klastrze) i wszystko było ok. Przynajmniej do czasu, aż zechcemy spróbować podziałać na innym użytkowniku. Wtedy dostajemy taki oto błąd:
java.io.FileNotFoundException: /ozone/ozone-1.2.1/logs/ozone-shell.log (Permission denied)
at java.io.FileOutputStream.open0(Native Method)
at java.io.FileOutputStream.open(FileOutputStream.java:270)
at java.io.FileOutputStream.<init>(FileOutputStream.java:213)
at java.io.FileOutputStream.<init>(FileOutputStream.java:133)
at org.apache.log4j.FileAppender.setFile(FileAppender.java:294)
at org.apache.log4j.FileAppender.activateOptions(FileAppender.java:165)
at org.apache.log4j.DailyRollingFileAppender.activateOptions(DailyRollingFileAppender.java:223)
(...)
log4j:ERROR Either File or DatePattern options are not set for appender [FILE].
Pocieszające jest to, że błąd ten nie oznacza, że polecenie do Ozone nie zostało wykonane. Oznacza jedynie, że nie mamy uprawnień do pliku z logami Ozone Shell. Żeby powiedzieć dokładniej, nie mamy dostępu do zapisu na tym pliku.
Nie jest to więc błąd stricte “Ozonowy”. Jest za to stricte linuxowy – należy nadać użytkownikowi odpowiednie uprawnienia. Można to zrobić na kilka różnych sposobów. Jeśli Twój klaster, podobnie jak mój, jest jedynie klastrem eksperymentalnym, możesz śmiało nadać uprawnienia zapisu “innym użytkownikom” pliku. Wchodzimy do folderu z logami i wpisujemy następującą komendę:
chmod a+rw ozone-shell.log
Podsumowanie
Apache Ozone to naprawdę ciekawa i – mam nadzieję – przyszłościowa technologia. Musi jednak jeszcze trochę wody w Wiśle upłynąć, aby zyskała popularność oraz dojrzałość HDFSa. Zachęcam jednak do eksperymentowania i dzielenia się tutaj wrażeniami;-)
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Razem możemy więcej!
Apache Ozone to następca HDFS – przynajmniej w marketingowym przekazie. W rzeczywistości sprawa jest nieco bardziej złożona i proste analogie mogą być złudne. Jako, że jestem w trakcie budowy systemu do analizy spółek giełdowych, buduję także nowy, eksperymentalny klaster (czy może – klasterek;-)). Uznałem to za idealny moment, żeby przetestować, bądź co bądź nową technologię, jaką jest Apache Ozone. W kolejnym artykule podzielę się swoimi obserwacjami oraz problemami które rozwiązałem. Zacznijmy jednak najpierw od poznania podstaw, czyli architektury Apache Ozone. Zapraszam!
Czym (nie) jest Apache Ozone?
Jeśli Ozone to następca HDFSa, a HDFS to system plików, to Apache Ozone jest systemem plików prawda? Nie. I to jest pierwsza różnica, którą należy dostrzec. HDFS był bliźniaczo podobny (w interfejsie i ogólnej budowie użytkowej, nie architekturze) do standardowego systemu plików dostępnego na linuxie. Mieliśmy użytkowników, foldery, a w nich pliki, ewentualnie foldery, w których mogły być pliki. Albo foldery. I tak w kółko.
Apache Ozone to rozproszony, skalowalny object store (/storage). Na temat podejścia object storage można przeczytać tutaj. Podstawową jednak różnicą jest to, że Ozone ma strukturę płaską, a nie hierarchiczną. Również, podobnie jak HDFS, dzieli pliki na bloki, także posiada swoje repliki, jednak nie możemy zawierać zagnieżdżonych folderów.
Podstawowa budowa Apache Ozone
Ozone oczywiście jest systemem rozproszonym – działa na wielu nodach (serwerach/komputerach).
Oto podstawowy opis struktury:
Volumes – podobne do kont użytkowników lub katalogów domowych. Tylko admin może je utworzyć.
Buckets – podobne do folderów. Bucket może posiadać dowolną liczbę keys, ale nie może posiadać innych bucketów.
Keys – podobne do plików.
Ozone zbudowany jest z kilku podstawowych komponentów/serwisów:
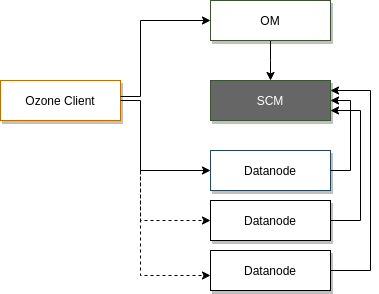
Ozone Manager (OM) – odpowiedzialny za namespacy. Odpowiedzialny za wszystkie operacje na volumes, buckets i keys. Każdy volume to osobny root dla niezależnego namespace’u pod OM (to różni go od HDFSa).
Storage Container Manager (SCM) – Działa jako block manager. Ozone Manage requestuje blocki do SCM, do których klientów można zapisać dane.
Data Nodes – działa w ramach Data Nodes HDFSowych lub w uruchamia samodzielnie własne deamony (jeśli działa bez HDFSa)
Ozone oddziela zarządzanie przestrzenią nazw (namespace management) oraz zarządzanie przestrzenią bloków (block space management). To pomaga bardzo mocno skalować się Ozonowi. Ozone Manager odpowiada za zarządzanie namespacem, natomiast SCM za zarządzanie block spacem.
Ozone Manager
Volumes i buckets są częścią namespace i są zarządzane przez OM. Każdy volume to osobny root dla niezależnego namespace’a pod OM. To jedna z podstawowych różnic między Apache Ozone i HDFS. Ten drugi ma jeden root od którego wszystko wychodzi.
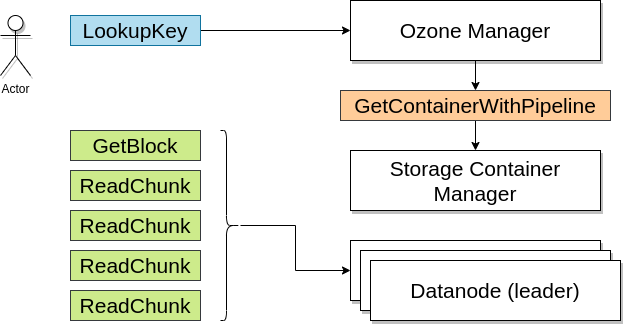
Jak wygląda zapis do Ozone?
Aby zapisać key do Ozone, client przekazuje do OM, że chce zapisać konkretny key w konkretnym bucket, w konkretnym volume. Jak tylko OM ustali, że możesz zapisać plik w tym buckecie,OM zaalokuje block dla zapisu danych.
Aby zaalokować blok, OM wysyła request do SCM. To on tak naprawdę zarządza Data Nodami. SCM wybiera 3 data nody (najprawdopodobniej na repliki) gdzie klient może zapisać dane. SCM alokuje blok i zwraca block ID do Ozone Managera.
Ozone Manager zapisuje informacje na temat tego bloku w swoich metadanych i zwraca blok oraz token bloku (uprawnienie bezpieczeństwa do zapisu danych na bloku) do klienta.
Klient używa tokena by udowodnić, że może zapisać dane na bloku oraz zapisuje dane na data node.
Gdy tylko zapis jest ukończony na data node, klient aktualizuje informacje o bloku w OM.
Jak wygląda odczyt danych (kluczy/keys) z Ozone?
Klient wysyła request listy bloków do Ozone Manager.
OM zwraca listę bloków i tokenów bloków, dzięki czemu klient może odczytać dane z data nodes.
Klient łączy się z data node i przedstawia tokeny, po czym odczytuje dane z data nodów.
Storage Container Manager
SCM jest głównym nodem, który zarządza przestrzenią bloków (block space). Podstawowe zadanie to tworzenie i zarządzanie kontenerami. O kontenerach za chwilkę, niemniej pokrótce, są to podstawowe jednostki replikacji.
Tak jak napisałem, Storage Container Manager odpowiada za zarządzanie danymi, a więc utrzymuje kontakt z Data Nodami, gra rolę Block Managera, Replica Managera, ale także Certificate Authority. Wbrew intuicji, to SCM (a nie OM) jest odpowiedzialny za tworzenie klastra Ozone. Gdy wywołujemy komendę init, SCM tworzy cluster identity oraz root certificates potrzebne do CA. SCM zarządza cyklem życia Data Node.
SCM do menedżer bloków (block manager). Alokuje bloki i przydziela je do Data Nodów. Warto zawuażyć, że klienci pracują z blokami bezpośrednio (co jest akurat trochę podobne do HDFSa).
SCM utrzymuje kontakt z Data Nodami. Jeśli któryś z nich padnie, wie o tym. Jeśli tak się stanie, podejmuje działania aby naprawić liczbę replik, aby ciągle było ich tyle samo.
SCM Certificate Authority jest odpowiedzialne za wydawanie certyfikatów tożsamości (identity certificates) dla każdej usługi w klastrze.
SCM nawiązuje regularny kontakt z kontenerami poprzez raporty, które te składają. Ponieważ są znacznie większymi jednostkami niż bloki, raportów jest wiele wiele mniej niż w HDFS. Warto natomiast pamiętać, że my, jako klienci, nie komunikujemy się bezpośrednio z SCM.
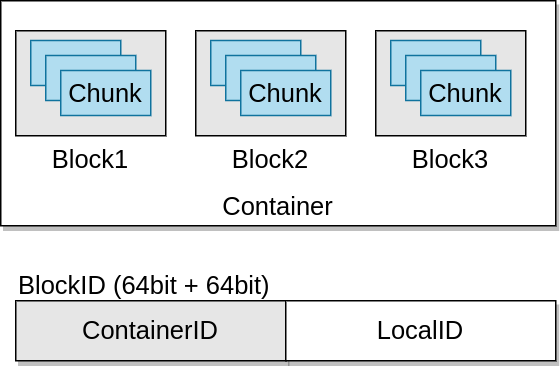
Kontenery i bloki w Ozone(Contrainers and blocks)
Kontenery (containers) to podstawowe jednostki w Apache Ozone. Zawierają kilka bloków i są całkiem spore (5gb domyślnie).
W konkretnym kontenerze znajdziemy ileś bloków, które są porcją danych. Jednak same bloki nie są replikowane. Informacje o blokch nie są też zarządzane przez SCM – są trzymane tylko informacje o kontenerach i to kontenery podlegają replikacji. Kiedy OM requestuje o zaalokowanie nowego bloku do SCM, ten “namierza” odpowiedni kontener i generuje block id, które zawiera w sobie ContainerIs + LocalId (widoczne na obrazku powyżej). Klient łączy się wtedy z Datanode, który przechowuje dany kontener i to datanode zarządza konkretnym blokiem na podstawie LocalId.
Data Nodes
Data Nody to serwery, na których dzieje się prawdziwa, docelowa magia Ozone. To tutaj składowane są wszystkie dane. Warto pamiętać, że to z nimi bezpośrednio łączy się klient. Zapisuje on dane w postaci bloków. Data node agreguje te dane i zbiera do kontenerów (storage containers). W kontenerach, poza danymi, znajdują się też metadane opisujące je.
Jak to wszystko działa? Kiedy chcemy odczytać plik, uderzamy do OM. Ten zwraca nad listę bloków, która składa się z pary ContainerId:LocalId. To dość chude informacje, ale wystarczą, aby można było udać się do konkretnych kontenerów i wyciągnąć konkretne bloki (LocalId to po prostu unikatowy numer ID w ramach kontenera, czyli w ramach dwóch różnych kontenerów moga być dwa bloki o LocalID=1, natomiast w ramach jednego kontenera nie).
Podsumowanie
Mam szczerą nadzieję, że tym artykułem pomogłem odrobinę zrozumieć architekturę Apache Ozone. Przyznam, że pełnymi garściami czerpałem z dokumentacji. Choć – jestem przekonany – jest to pierwszy polski materiał na temat tej technologii, to z pewnością nie jest ostatni. Jestem w trakcie instalowania Ozone na eksperymentalnym klasterku RDFowym i na bieżąco piszę artykuł o doświadczeniach i błędach, jakie napotkałem. Obserwuj RDF na LinkedIn i zapisz się na newsletter, to nie przegapisz!
Jeśli czegoś nie wiem – wchodzę w wyszukiwarkę i zdobywam wiedzę. Można powiedzieć, że wyszukiwarka to swoisty “rdzeń” internetu. Mogę tam znaleźć wszystko. Punkt wyjścia do wiedzy całej ludzkości. Tak jest dzisiaj. Tylko, że 25 lat temu… nikt tak nie myślał. Nawet nie było takiej możliwości. “Szukaj” to znakomita książka, która opisuje rozwój wyszukiwarek internetowych, z Google w roli głównej. Jednak najciekawszą rzeczą jest to, że napisana została 2005 roku. Z dzisiejszej perspektywy wiemy znacznie więcej i możemy zweryfikować niektóre fakty. Zapraszam do pierwszej recenzji książki na blogu RDF –“Szukaj – Jak Google i konkurencja wywołali biznesową i kulturową rewolucję”.
O czym jest, a o czym nie jest książka “Szukaj”?
Cóż, wbrew pozorom (oraz wbrew okładce), nie dostaniemy wcale historii Google. Nie dostajemy tu także życiorysu Siergieja Brina ani Larry’ego Page’a (założycieli Google). Wbrew temu co można pomyśleć czytając tytuł – nie będzie o kształtowaniu współczesnej debaty i problemach z cenzorowaniem treści o zabarwieniu konserwatywnym. Nie będzie, bo książka została napisana w roku 2005, a nie 2020.
Żeby właściwie oddać skalę czasu powiem tylko, że 2005 rok to 7 lat po założeniu Google. Obecnie zbliżają się już… 23 lata technologicznego giganta. Historia Google to niemalże historia Internetu. W czasie, w którym pisane były stronice “Szukaj”, nie było jeszcze Androida, Youtuba (w obecnym kształcie) ani Google Drive. Była za to… wyszukiwarka. Jedna z najnudniejszych usług o jakich można pomyśleć.
Czy na pewno? Książka zręcznie pokazuje, że wcale nie. Pokazuje drogę, jaką przeszły wyszukiwarki oraz cały kontekst. Opisuje rzeczy, które wydają się być z innego świata – długie dyskusje i zastanawianie się, czy opcja wyszukiwarki (nawet na pojedynczej stronie) jest dobrym i potrzebnym pomysłem. John Batelle maluje nam naprawdę kompleksowy obraz – włączając technikalia, aktualny rozwój internetu oraz rywalizację biznesową, a nawet kulturową (poruszany jest wątek chiński). Choć napisałem, że nie jest to książka o Google, to w rzeczywistości dostajemy kawał historii tej firmy. Stajemy się bliskimi obserwatorami przeżyć i przemyśleń dwóch założycieli, pierwszych pracowników firmy oraz ich konkurencji. To wszystko pozwala nam dostrzec, jak dynamiczna była sytuacja oraz jak wiele problemów musiała rozwiązać dwójka doktorantów Stanforda.
Pierwsze wyszukiwarki nie przypominały w niczym dzisiejszych. Na obrazku jeden z pionierów wyszukiwania internetowego – AltaVista
Jak wyglądał internet… 25 lat temu?
Wyobraź sobie, że chcesz się podzielić zdjęciami ze znajomymi. Nie wyślesz ich przez Signal czy Messenger. Nie zamieścisz na Instagramie. Pomyśl sobie, że chcesz się przekwalifikować. Co robisz? Na pewno nie wejdziesz do internetu, żeby poszukać dobrego kursu z danej dziedziny – po prostu nie ma ani takich kursów, ani… możliwości prostego wyszukania. Jedziesz do innego miasta? Zapomnij o GPS – przecież nie jesteś amerykańskim Marine! Nie umieścisz w sieci szybkich informacji, wiadomości sprawdzisz dopiero po wizycie w kiosku a żeby czymkolwiek zapłacić, musisz mieć gotówkę (lub czek).
To nie jest katastroficzna wizja sparaliżowania ludzkości. To nie jest też opis ery kamienia łupanego, wymalowany na ścianie jaskini. To opis naszego świata zaledwie 20-25 lat temu. TAK – było całkiem analogowo! Druga połowa lat 90′ to dopiero raczkujący Internet, raczej nowinka. Pamiętajmy, że chociaż sama technologia Internetu jest bardzo ciekawa, to naprawdę rewolucyjna staje się dopiero wtedy, gdy jest wypełniona treścią. Dziś wiadomo, że w jakiejś formie trzeba być obecnym w Internecie, jeśli prowadzisz działalność. Wtedy było to równie popularne, co współcześnie umieszczanie banerów nad pisuarem w pubie. Tak więc pierwsza rzecz jaką autor nam uświadamia: dzisiaj wiadomo, że na każde pytanie odpowiedź znajdę w internecie, wtedy absolutnie nie było takiego przeświadczenia.
To były czasy tzw. Web 1.0. Czasy twórców i statycznych stron. Użytkownicy byli jedynie biernymi obserwatorami. Przypominało to nieco tak naprawdę tradycyjne media, przede wszystkim gazety, z którymi nie możemy nawiązać żadnej interakcji, ale które możemy przeglądać. Tyle tylko, że Internet był dostępny na ekranie, a nie w formie gazety. No i mieliśmy dostęp do wielu twórców… o ile mieliśmy ich adresy.
Search 1.0 – czyli jak to się zaczęło, z tym wyszukiwaniem?
Archie, australopitek wśród wyszukiwarek
Jednym z ciekawszych aspektów książki jest wycieczka po pierwszych, dawno zapomnianych wyszukiwarkach. W zasadzie jedyne w czym przypominały obecne, to fakt, że istnieje tam jakieś okienko, w które coś możemy wpisać, a na końcu dostajemy jakieś wyniki. Poza tym – absolutnie wszystko było inne. Wszystko zaczęło się od sympatycznie brzmiącej Archie. Aby nadać kontekst, przywołajmy słowa samego Autora:
“W roku 1990 naukowcy i technicy regularnie używali Internetu do składowania prac naukowych, specyfikacji technicznych i innego rodzaju dokumentów na publicznie dostępnych komputerach. Jednak bez znajomości dokładnego adresu komputera i nazwy pliku znalezienie tych archiwów graniczyło z niemożliwością. Program Archie przeszukiwał internetowe archiwa (stąd jego nazwa) i tworzył indeks każdego znalezionego pliku.”
Archie to pierwsza wyszukiwarka, dzięki której można było przeczesywać internetowe archiwa.
Jak wyglądała Archie? Mniej więcej tak jak to widać powyżej. Swoją drogą, Archie miała swoje narodziny 10 września 1990 r. Co prawda było to 3 lata przed narodzinami autora tego artykułu, ale za to urodziny możemy obchodzić niemal razem (09.09);-). Co ciekawe – z wyszukiwarki można skorzystać nawet teraz, pod tym linkiem (choć raczej jedynie w ramach ciekawostki).
Warto jednak powiedzieć w jaki sposób Archie działała (działał?). Wyszukiwarka odbierała zapytania zbudowane ze słów kluczowych. Następnie przeszukiwała archiwa poszukując tych słów w nazwach plików. Po wszystkim, jako wynik zwracała listę miejsc, w których owe pliki znaleziono. Nie jest wielką sztuką dostrzec, że rozwiązanie to było podobne do współczesnych wyszukiwarek podobnie, jak australopitek do nas. Problematyczne było zarówno to, że zwracane nie były pliki a lokalizacje, jak i to, że indeksowane były jedynie tytuły. Trzeba było mieć więc albo wiedzę, że taki dokument istnieje, albo mieć znakomitego nosa.
Altavista, czyli pierwszy mocny przełom
Lata później sprawy zaczęły nieodwracalnie pędzić w kierunku, który mamy współcześnie. Nie chodzi tu jednak o kwestię wyszukiwarek, a o dynamikę rozwoju Internetu. W 1995 roku sieć liczy już 10 mln witryn i rozwija się w absurdalnym tempie 2000% rocznie. Oczywistym staje się, że ogarnięcie takiego zbioru danych będzie bardzo, bardzo trudne. Nie chodzi, pamiętajmy, o samo zebranie (co już jest wyczynem), ale także o przeszukiwanie w czasie rzeczywistym. Potrzeba byłoby jakiegoś… superkomputera.
I tutaj z pomocą przychodzi firma DEC (Digital Equipment Corp.) ze swoją Alta Vistą. Historia powstania tej wyszukiwarki jest niejasna. Powtarzający się jednak motyw jest taki, że firma stała na krawędzi upadku. Jak tlenu potrzebowała pieniędzy oraz dobrego PR. I tu pojawił się pomysł, żeby dla nowego superprocesora napisać coś, co będzie imponującym eksperymentem pokazującym jego możliwości. W ten sposób Louis Monier zabrał się do pracy, w efekcie tworząc przełomową wyszukiwarkę internetową – Alta Vistę. Różniła się od innych obecnych na rynku tym, że nie indeksowała jedynie adresów url, ale całe strony oraz… no własnie, indeksowała je w ogromnym tempie, dzięki wysłaniu “na łowy” nie jednego crawlera, a… tysiąc. Było to możliwe właśnie dzięki procesorowi.
Niestety, Alta Vista została z czasem wyprzedzona przez Google. Po drodze przeszła długą wędrówkę miotając się między rozmaitymi decyzjami biznesowymi, kilkukrotnymi próbami wejścia na giełdę, zmianą właścicieli, aż w końcu żywot swój dokonała w Yahoo! w 2013 roku. Alta Vista jest wzorcowym przykładem tego co dzieje się, gdy nie umiemy dostosować biznesu do zmieniającej się rzeczywistości.
Baza Intencji – wyszukiwanie, jako “rdzeń” Internetu oraz Big Data
Powoli dochodzimy do sedna, które moim zdaniem najmocniej pokazuje jaką potęgę od początku trzyma w swoich rekach Google. Jeśli ktoś nie będzie mógł przebrnąć przez książkę – najlepiej przeczytać chociaż pierwszy rozdział “Baza Danych Intencji”. Bardzo często w debacie przewija się pytanie o to kto jest na naszym świecie najbardziej wpływowy. Wymieniamy tu zwykle polityków i biznesmenów. No więc jak myślisz, jaki rodzaj biznesu ma największy wpływ na nas wszystkich? Dostawcy ropy? Media? Blisko. Kiedy nad tym pomyślimy, dojdziemy do oczywistego wniosku, że największy wpływ mają na nas ci, którzy nas najlepiej znają. Zwykle to była nasza rodzina, przyjaciele, czasami przebiegli politycy.
Problem polega jednak na tym, że oni wszyscy widzą pewną powłokę, którą chcemy (lub nie) im sprzedać. Nawet jeśli z kimś rozmawiamy, modelujemy intencjami, które z nas wychodzą. A co, jeśli… mieć dostęp do samego wnętrza naszego mózgu? Bez wszystkich filtrów, po prostu – jeśli znać nasze myśli, które wychodzą prosto z mózgu (czy też “z serca”)?
Właśnie w takiej pozycji usadził się Google. Jak pisze John Battelle, zdał sobie sprawę z tego jaką potęgę trzyma Google, gdy przeglądał wydanie Google Zeitgeist podsumowujące 2001 rok (Google Zeitgeist to poprzednik Google Trends). w tamtym czasie najpopularniejszymimi wyszukiwania były: Nostradamus, CNN, World Trade Center, Harry Potter, wąglik. Lista tracących popularność fraz wskazywała, że ludzie przestawali interesować się głupotami: Pokemon, Napster, Big Brother, X-Men, zwyciężyni teleturnieju “Kto chce poślubić multimilionera”.
Jak napisał Autor:
“Byłem w szoku. Zeitgeist ukazał mi, że Google nie tylko trzyma rękę na pulsie kultury, ale tkwi bezpośrednio w jej systemie nerwowym. Tak wyglądało moje pierwsze zetknięcie z tym, co później nazwałem Bazą Danych Intencji – żywym artefaktem o wielkiej mocy. >>Dobry Boże<<, pomyślałem sobie, Google wie, czego szukają ludzie! Stwierdziłem, biorąc pod uwagę miliony zaputań zmierzających każdej godziny do serwerów Google, że firma ta siedzi na kopalni złota. Na podstawie zgromadzonych w niej informacji o ludzkich zamiarach można by utworzyć wiele przedsiębiorstw prasowychL w istocie pierwsze – eksperymentalny >>Google News<< – już powstało. Czy Google nie mogło założyć też firmy zajmującej się badaniami i marketingiem, która mogłaby precyzyjnie informować o tym, co ludzie kupują, co chcą a czego unikają?”
I tutaj właśnie leży sedno. Wyniki wyszukiwania są zakryte przed znajomymi. Znamy je tylko my i maszyny Google. Udajemy się tam tylko wtedy, gdy chcemy coś znaleźć, czegoś się dowiedzieć. Szkodzilibyśmy więc sobie bez pożytku, gdybyśmy udawali. Jesteśmy szczerzy, naturalni. Google dokładnie wie, czego poszukujemy, czym żyjemy, czego pragniemy. To właśnie autor nazwał Bazą Danych Intencji. Kto więc może być najbardziej wpływowy? Oczywiście – firma, która ma dostęp do naszego serca, naszej świadomości, pragnień… i która to firma może na tym robić pieniądze oraz zręcznie modelować wynikami.
Moim zdaniem właśnie dlatego przeszukiwanie to samo sedno zarówno internetu, jak i Big Data. Docieramy do samego sedna i przetwarzamy najbardziej “szczere” dane, aby poznać prawdę o nas. Jakkolwiek górnolotnie by to nie brzmiało, jest to prawda i olbrzymia moc. A jak wiadomo – “Z wielką mocą wiąże się wielka odpowiedzialność ;-).
Google wczoraj, Google dzisiaj, czyli jak autor widział przyszłość?
Podtytuł ten to parafraza rozdziału “Google dzisiaj, Google jutro”, który jest pewną próbą przewidzenia przyszłości. Z dzisiejszej perspektywy, po niemal 16 latach, możemy powiedzieć, czy trafną;-).
Rywalizacja z Yahoo (i Microsoftem)
Autor zaznacza, że:
“Konkurencja Google jest bardzo liczna, ale najważniejszym z rywali, przynajmniej w latach 2005-2006 jest Yahoo. W roku 2007 trzeba też będzie stawić czoła przygotowującemu najcięższą artylerię Microsoftowi, ale na dzień dzisiejszy głównym wrogiem Google jest Yahoo”
Zacznijmy od tej drugiej części – Microsoft. Być może Autor miał na myśli wyszukiwarkę Msn Search, która weszła jednak do użycia w 2005 roku. W chwili inauguracji indeksowała 5 mld stron i była używana przez 1/6 internautów. Następnie przekształciło się w Windows Live, aby zostać przemianowane na Bing.
Jeśli chodzi o Yahoo, nie była i nie jest to stricte wyszukiwarka. Oczywiście funkcja wyszukiwarki oczywiście także istnieje, natomiast inne elementy są znacznie silniejszym atutem firmy (jak na przykład Yahoo Finance).
Jak wyglądają obecnie procentowe udziały w całym torcie wyszukiwarek na świecie?
Google – 91.95%
Bing – 2.93%
Yahoo – 1.51%
Można powiedzieć, że z jednej strony faktycznie najsilniejsza konkurencja pozostała najsilniejszą konkurencją. Tyle, że realnie Google jest monopolistą.
Wielki system operacyjny WWW działający na infrastrukturze Google
Najbardziej śmiała wizja przytoczona przez autora to utworzenie wielkiego systemu operacyjnego, który łączy różne urządzenia i usługi. Taki system miałby działać na infrastrukturze Google. Następuje tu analogia do Microsoftu, który postawił komputer w każdym domu i zainstalował na nim Windowsa. Niedługo – według Battella – będziemy pracować na jednym wielki systemie. Tam będą składowane dane, tam będziemy rozmawiać, pracować itd.
Dzięki temu Google uda się zrealizować swoją misję o “uporządkowaniu światowych zasobów informacji, aby stały się one powszechnie dostępne i użyteczne”.
“Misja Google, polegająca na porządkowaniu i udostępnianiu światowych informacji, pozwala spółce udostępniać wszystkie usługi, które mogą się naleźć na komputerowej platformie – od codziennych aplikacji jak przetwarzanie tekstu i arkusze kalkulacyjne (w tej chwili domena Microosftu), do bardziej futurystycznych usług, takich jak wideo na żądanie, składowanie osobistych mediów, albo nauka na odległość.“
Cóż, sądzę że ta śmiała wizja została w większości zrealizowana. Co prawda w pomyśle Autora Google byłby hegemonem, który staje się głównym dostawcą całego życia (dalej jest mowa także o dostarczaniu kablówki, bycie uniwersytetem itd). W tym zakresie nie udało się Google zawłaszczyć całego tortu – moim zdaniem na szczęście. Są inne przestrzenie, takie jak Microsoft Teams, Zoom, wirtualne dyski itd.
Znakomita większość jednak… ma miejsce! Mamy przecież Hangouts, mamy Google Drive (w tym dokumenty i arkusze kalkulacyjne). Co więcej – mamy androida, a nawet Google Street View, tak więc firma weszła na obszary, które (pozornie) z wyszukiwaniem nie mają wiele wspólnego. Stanowi to naprawdę wysoki kunszt wizjonerski Johna Battella i należy mu oddać szacunek.
Google Video, poprzednik YouTube. Wielki gigant nie zawsze może rywalizować z niezależnymi usługami.
Youtube
“Kolejnym ważnym trendem jest wzrost popularności wideo. W zeszłym roku YouTube, serwis udostępniania plików filmowych, stał się jednym z największych w sieci, a w reklamę wideo zainwestowano setki milionów dolarów. Mimo, że produkt Google Video jest nowatorski i popularny, firma ta w oczach opinii publicznej przegrała z YouTube. Czy Google pozostanie miłe dla firm typu YouTube, indeksując ich zawartość i ograniczając się do roli centrali telefonicznej, tak jak w przypadku tekstu? Czy też spróbuje rywalizować poprzez własną usługę, z nadzieją na przechwycenie całego naszego zainteresowania, tak jak to robiły stare sieci (ABC, CBS, NBC)? Nie znamy jeszcze odpowiedzi, ale same pytania są bardzo ciekawe”
To chyba mój ulubiony cytat;-). Google Video można zobaczyć powyżej (obecnie także dostępne, ale w zupełnie innym celu i formie). Tak więc, cóż… dziś już znamy odpowiedzi na te pytania. Google wykupiło YouTube, pozyskując tym samym ogromną rzeczywistość, rzeczywistość filmów. Nawiasem mówiąc, poprzez Youtube (i system rekomendacji) ma gigantyczne możliwości oddziaływania na nasz styl myślenia.
Podsumowanie
John Battelle wykonał kawał roboty pokazując historię wyszukiwania. Zrobił jednak jeszcze więcej roboty, ukazując jak bardzo potężnym sednem całej branży może być wyszukiwanie. Z całą pewnością wrażenie powinno zrobić z dzisiejszej perspektywy to, do jakiego punktu doszedł Google. Nie jest to już jedynie wyszukiwarka – to ogromny moloch, który dostarcza nam całą gamę usług, z których korzystamy. Uczy się każdego naszego ruchu i upraszcza życie. Ma to oczywiście swoją cenę. Pytanie “czy jesteśmy gotowi ją płacić?” pozostaje otwarte – do odpowiedzi przez każdego z osobna.
Ja ze swojej strony na pewno polecam “Szukaj”. Lektura pouczająca i mocno wgryzająca się w całą sprawę.
Polecam także oczywiście naszą stronę na LinkedIn oraz newsletter, dzięki któremu zostaniemy w kontakcie;-).
Machine Learning w Sparku? Jak najbardziej! W poprzednim artykule pokazałem efekty prostego mechanizmu do porównywania tekstów, który zbudowałem. Całość jest zrobiona w Apache Spark, co niektórych może dziwić. Dzisiaj chcę się podzielić tym jak dokładnie zbudować taki mechanizm. Kubki w dłoń i lecimy zanurzyć się w kodzie!
Powiem jeszcze, że tutaj pokazuję jak zrobić to w prostej, batchowej wersji. Po prostu uruchomimy cały job sparkowy wraz z tekstem i dostaniemy odpowiedzi. W innym artykule jednak pokażę jak zrobić także joba streamingowego. Dzięki temu stworzymy mechanizm, który będzie nasłuchiwał i naprawdę szybko będzie zwracał wyniki w czasie rzeczywistym (mniej więcej, w zależności od zasobów – czas ocekiwania to kilka, kilkanaście sekund). Jeśli chcesz dowiedzieć się jak to zrobić – nie zapomnij zasubskrybować bloga RDF!
Spark MlLib
Zacznijmy od pewnej rzeczy, żeby nam się nie pomyliło. Spark posiada bibliotekę, która służy do pracy z machine learning. Nazywa się Spark MlLib. Problem polega na tym, że wewnątrz rozdziela się na dwie pod-biblioteki (w scali/javie są to po prostu dwa pakiety):
Spark MlLib – metody, które pozwalają na prace operując bezpośrednio na RDD. Starsza część, jednak nadal wspierana.
Spark Ml – metody, dzięki którym pracujemy na Datasetach/Dataframach. Jest to zdecydowanie nowocześniejszy kawałek biblioteki i to z niego właśnie korzystam.
Ta sama uwaga odnośnie “provided” co w przypadku mavena.
Spark NLP od John Snow Labs
Chociaż Spark posiada ten znakomity moduł SparkMlLib, to niestety brak w nim wielu algorytmów. Zawierają się w tych brakach nasze potrzeby. Na szczęście, luka została wypełniona przez niezależnych twórców. Jednym z takich ośrodków jest John Snow Labs (można znaleźć tutaj). Samą bibliotekę do przetwarzania tekstu, czyli Spark-NLP zaciągniemy bez problemu z głównego repozytorium Mavena
Dodawanie dependencji, jeśli korzystamy z Mavena (plik pom.xml):
Dodawanie dependencji jeśli korystamy z SBT (plik build.sbt):
libraryDependencies += "com.johnsnowlabs.nlp" %% "spark-nlp" % "3.3.4" % Test
Dane
Dane same w sobie pochodzą z 3 różnych źródeł. I jak to bywa w takich sytuacjach – są po prostu inne, pomimo że teoretycznie dotyczą tego samego (tweetów). W związku z tym musimy zrobić to, co zwykle robi się w ramach ETLów: sprowadzić do wspólnej postaci, a następnie połączyć.
Dane zapisane są w plikach CSV. Ponieważ do porównywania będziemy używać tylko teksty, z każdego zostawiamy tą samą kolumnę – text. Poza tą jedną kolumną dorzucimy jednak jeszcze jedną. To kolumna “category”, która będzie zawierać jedną z trzech klas (“covid”, “finance”, “grammys”). Nie będą to oczywiście klasy służące do uczenia, natomiast dzięki nim będziemy mogli sprawdzić potem na ile dobrze nasze wyszukiwania się “wstrzeliły” w oczekiwane grupy tematyczne. Na koniec, gdy już mamy identyczne struktury danych, możemy je połączyć zwykłą funkcją “union”.
Gdy pracujemy z NLP, bazujemy oczywiście na tekście. Niestety, komputer nie rozumie tekstu. A co rozumie komputer? No jasne, liczby. Musimy więc sprowadzić tekst do poziomu liczb. Konkretnie wektorów, a jeszcze konkretniej – embeddingów. Embeddingi to nisko-wymiarowe reprezentacje czegoś wysoko-wymiarowego. W naszym przypadku będzie to tekst. Czym dokładnie są embeddingi, dobrze wyjaśnione jest na tej stronie. Na nasze, uproszczone potrzeby musimy jednak wiedzieć jedno: embeddingi pozwalają zachować kontekst. Oznacza to w dużym skrócie, że słowo “pizza” będzie bliżej słowa “spaghetti” niż słowa “sedan”.
Sprowadzanie do postaci liczbowej może się odbyć jednak dopiero wtedy, gdy odpowiednio przygotujemy tekst. Bardzo często w skład takiego przygotowania wchodzi oczyszczenie ze “śmieciowych znaków” (np. @, !, ” itd) oraz tzw. “stop words”, czyli wyrazów, które są spotykane na tyle często i wszędzie, że nie opłaca się ich rozpatrywać (np. I, and, be). Oczywiście może to rodzić różne problemy – np. jeśli okroimy frazy ze standardowych “stop words”, wyszukanie “To be or not to be” będzie… puste. To jednak już problem na inny czas;-).
Do przygotowania często wprowadza się także tokenizację, czyli podzielenie tekstu na tokeny. Bardzo często to po prostu wyciągnięcie wyrazów do osobnej listy, aby nie pracować na stringu, a na kolekcji wyrazów (stringów). Spotkamy tu także lemmatyzację, stemming (obie techniki dotyczą sprowadzenia różnych słów do odpowiedniej postaci, aby móc je porównywać).
W naszym przypadku jednak nie trzeba będzie robić tego wszystkiego. Jedyne co musimy, to załączyć DocumentAssembler. Jest to klasa, która przygotowuje dane do formatu zjadliwego przez Spark NLP.
Po zastosowaniu dostajemy kolumnę, która ma następującą strukturę:
W naszym kodzie najpierw inicjalizujemy DocumentAssembler, wykorzystamy go nieco później. Przy inicjalizacji podajemy kolumnę wejściową oraz nazwę kolumny wyjściowej:
val docAssembler: DocumentAssembler = new DocumentAssembler().setInputCol("text")
.setOutputCol("document")
Zastosowanie USE oraz budowa Pipeline
Jak już napisałem, my wykorzystamy Universal Sentence Encoder (USE). Dzięki tym embeddingom całe frazy (tweety) będą mogły nabrać konktekstu. Niestety, sam “surowy” Spark MlLib nie zapewnia tego algorytmu. Musimy tu zatem sięgnąć po wspomniany już wcześniej Spark NLP od John Snow Labs (podobnie jak przy DocumentAssembler). Zainicjalizujmy najpierw sam USE.
val use: UniversalSentenceEncoder = UniversalSentenceEncoder.pretrained()
.setInputCols("document")
.setOutputCol("sentenceEmbeddings")
Skoro mamy już obiekty dosAssembler oraz use, możemy utworzyć pipeline. Pipeline w Spark MlLib to zestaw powtarzających się kroków, które możemy razem “spiąć” w całość, a następnie wytrenować, używać. Wyjście jednego kroku jest wejściem kolejnego. Wytrenowany pipeline (funkcja fit) udostępnia nam model, który możemy zapisać, wczytać i korzystać z niego.
Nasz pipeline będzie bardzo prosty:
val pipeline: Pipeline = new Pipeline().setStages(Array(docAssembler, use))
val fitPipeline: PipelineModel = pipeline.fit(tweetsDF)
Gdy dysponujemy już wytrenowanym modelem, możemy przetworzyć nasze dane (funkcja transform). Po tym kroku otrzymamy gotowe do użycia wektory. Niestety, USE zagnieżdża je w swojej strukturze – musimy więc je sobie wyciągnąć. Oba kroki przedstawiam poniżej:
val vectorizedTweetsDF: Dataset[Row] = fitPipeline.transform(tweetsDF)
.withColumn("sentenceEmbeddings", org.apache.spark.sql.functions.explode(col("sentenceEmbeddings.embeddings")))
Znakomicie! Mamy już tweety w formie wektorów. Teraz należy jeszcze zwektoryzować tekst użytkownika. Tekst będzie przechowywany w Dataframe z jednym wierszem (właśnie owym tekstem) w zmiennej sampleTextDF. Po wektoryzacji usunę zbędne kolumny i zmienię nazwy tak, aby było wiadomo, że te wektory dotyczą tekstu użytkownika, a nie tweetów (przyda się później, gdy będziemy łączyć ze sobą oba Dataframy).
val vectorizedUserTextDF: Dataset[Row] = fitPipeline.transform(sampleTextDF)
.drop("document")
.withColumn("userEmbeddings", org.apache.spark.sql.functions.explode(col("sentenceEmbeddings.embeddings")))
.drop("sentenceEmbeddings")
Implementacja cosine similarity
Uff – sporo roboty za nami, gratuluję! Mamy już tweety oraz tekst użytkownika w formie wektorów. Czas zatem porównać, aby znaleźć te najbardziej podobne! Tylko pytanie, jak to najlepiej zrobić? Muszę przyznać że trochę czasu zajęło mi szukanie algorytmów, które mogą w tym pomóc. Finalnie wybór padł na cosine similarity. Co ważne – nie jest to żaden super-hiper-ekstra algorytm NLP. To zwykły wzór matematyczny, znany od dawna, który porównuje dwa wektory. Tak – dwa najzwyklejsze, matematyczne wektory. Jego wynik zawiera się między -1 a 1. -1 to skrajnie różne, 1 to identyczne. Nas zatem będą interesować wyniki możliwie blisko 1.
Problem? A no jest. Spark ani scala czy java nie mają zaimplementowanego CS. Tu pokornie powiem, że być może po prostu do tego nie dotarłem. Jeśli znasz gotową bibliotekę do zaimportowania – daj znać w komentarzu! Nie jest to jednak problem prawdziwy, bowiem możemy rozwiązać go raz dwa. Samodzielnie zaimplementujemy cosine similarity w sparku, dzięki UDFom (User Defined Function).
Najpierw zacznijmy od wzoru matematycznego:
Następnie utwórzmy klasę CosineSimilarityUDF, która przyjmuje dwa WrappedArrays (dwa wektory), natomiast zwraca zwykłą liczbę zmiennoprzecinkową Double. Wewnątrz konwertuję tablice na wektory, wykorzystuję własną metodę magnitude i zwracam odległość jednego wektora od drugiego.
Klasa CosineSimilarityUDF
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.sql.api.java.UDF2
import scala.collection.mutable
class CosinSimilarityUDF extends UDF2[mutable.WrappedArray[Float], mutable.WrappedArray[Float], Double]{
override def call(arr1: mutable.WrappedArray[Float], arr2: mutable.WrappedArray[Float]): Double = {
val vec1 = Vectors.dense(arr1.map(_.toDouble).toArray)
val vec2 = Vectors.dense(arr2.map(_.toDouble).toArray)
val mgnt1 = magnitude(vec1)
val mgnt2 = magnitude(vec2)
vec1.dot(vec2)/(mgnt1*mgnt2)
}
def magnitude(vector: Vector): Double={
val values = vector.toArray
Math.sqrt(values.map(i=>i*i).sum)
}
}
Znakomicie – po utworzeniu tego UDFa, możemy śmiało wykorzystać go do obliczenia podobieństw między każdym z tweetów a tekstem użytkownika. Aby to uczynić, najpierw rejestrujemy naszego UDFa. Polecam to co zawsze polecam na szkoleniach ze Sparka – zrobić to zaraz po inicjalizacji SparkSession. Dzięki temu utrzymamy porządek i nie będziemy się martwić, jeśli w przyszłości w projekcie ktoś będzie również chciał użyć UDFa w nieznanym obecnie miejscu (inaczej może dojść do próby użycia UDFa zanim zostanie zarejestrowany).
val cosinSimilarityUDF: CosinSimilarityUDF = new CosinSimilarityUDF()
sparkSession.udf.register("cosinSimilarityUDF", cosinSimilarityUDF, DataTypes.DoubleType)
Wróćmy jednak na sam koniec, do punktu w którym mamy już zwektoryzowane wszystkie teksty. Najpierw sprawimy, że każdy tweet będzie miał dołączony do siebie tekst użytkownika. W tym celu zastosujemy crossjoin (artykuł o sposobach joinów w Sparku znajdziesz tutaj). Następnie użyjemy funkcji withColumn, dzięki której utworzymy nową kolumnę – właśnie z odległością. Wykorzystamy do jej obliczenia oczywiście zarejestrowany wcześniej UDF.
val dataWithUsersPhraseDF: Dataset[Row] = vectorizedTweetsDF.crossJoin(vectorizedUserTextDF)
val afterCosineSimilarityDF: Dataset[Row] = dataWithUsersPhraseDF.withColumn("cosineSimilarity", callUDF("cosinSimilarityUDF", col("sentenceEmbeddings"), col("userEmbeddings"))).cache()
Na sam koniec pokażemy 20 najbliższych tekstów, wraz z kategoriami. Aby uniknąć problemów z potencjalnymi “dziurami”, odfiltrowujemy rekordy, które w cosineSimilarity nie mają liczb. Następnie ustawiamy kolejność na desc, czyli malejącą. Dzięki temu dostaniemy wyniki od najbardziej podobnych do najmniej podobnych.
I to koniec! Wynik dla hasła “The price of lumber is down 22% since hitting its YTD highs. The Macy’s $M turnaround is still happening” można zaobserwować poniżej. Więcej wyników – przypominam – można zaobserwować w poprzednim artykule;-).
Wyniki dla mechanizmu text similarity w Apache Spark.
Podsumowanie
Mam nadzieję, że się podobało! Daj znać koniecznie w komentarzu i prześlij ten artykuł dalej. Z pewnością to nie koniec przygody z Machine Learning w Sparku na tym blogu. Zostań koniecznie na dłużej i razem budujmy polskie środowisko Big Data;-). Jeśli chcesz pozostać z nami w kontakcie – zapisz się na newsletter lub obserwuj RDF na LinkedIn.
Pamiętaj także, że prowadzimy szkolenia z Apache Spark. Jakie są? Przede wszystkim bardzo mięsiste i tak bardzo zbliżone do rzeczywistości jak tylko się da. Pracujemy na prawdziwych danych, prawdziwym klastrze. Co więcej – wszystko to robimy w znakomitej atmosferze, a na koniec dostajesz garść materiałów!Kliknij tutaj i podrzuć pomysł swojemu szefowi;-).
Co ty na to, żeby zbudować system, dzięki któremu wyszukujemy podobne wypowiedzi polityków? Tak dla sprawdzenia – jeśli jeden coś powiedział, poszukamy czy jego oponenci nie mówili przypadkiem podobnie. Dzięki temu być może oczyścimy trochę debatę – świadomość, że nasi przedstawiciele nie różnią się aż tak bardzo, może być bardzo orzeźwiająca. Jednak taki mechanizm to dużo danych do przetworzenia i zinterpretowania. Dodatkowo tekstowych.
Dziś w artykule o podobnym problemie przy wykorzystaniu Apache Spark. Porozmawiamy więc o sztucznej inteligencji – a konkretniej machine learning, natural language processing (NLP) oraz text similarity. Wyjątkowo jednak nie w kontekście pythona, a właście Scali i Sparka.
Text Similarity (AI) w Apache Spark
Wróćmy do problemu podobieństw wypowiedzi polityków. Oczywiście musimy najpierw zebrać dane. Ile może ich być? Jeśli bazujemy na krótkich wypowiedziach – ogromne ilości. Wszystko zależy od tego jak bardzo chcemy się cofać w czasie i jak wiele osób wziąć pod lupę (Sejm? Senat? Rząd? Polityków lokalnych? A może zagranicznych?). Sumarycznie można się pokusić jednak o miliony, dziesiątki a nawet setki milionów krótkich wypowiedzi. A im bardziej w używaniu jest Twitter, tym więcej.
Pytanie, czy do tak dużych zbiorów można użyć bibliotek Pythonowych? Wiele z nich bazuje na jednej maszynie, bez możliwości naturalnego przetwarzania rozproszonego. Oczywiście nie wszystkie i z pewnością jest tam najmocniej rozwinięte środowisko do NLP. Na tym blogu skupimy się dziś jednak na mało popularnym pomyśle. Sprawdzimy na ile naprawdę poważnym rozwiązaniem może być Apache Spark w świecie machine learning. Dziś pokażę owoc eksperymentu nad przetwarzaniem tekstu w Apache Spark.
Po pierwsze: efekt
Zanim wskażę jakie techniki można zastosować, spójrzmy co udało się osiągnąć.
Zacznijmy od podstawowej rzeczy
Bazujemy na zbiorze, który ma ~204 tysiące krótkich tekstów – konkretnie tweetów.
Tweety dotyczą trzech dziedzin tematycznych:
COVID – znakomita większość (166543 – 81,7%)
Finanse – pewna część (28874 – 14,1%)
Grammy’s – margines (8490 – 4,2%)
W ramach systemu przekazujemy tekst od użytkownika. W odpowiedzi dostajemy 5 najbardziej podobnych tweetów.
Efekty
Poniżej kilka efektów. Chcę zauważyć, że sporą rolę odgrywa tutaj kwestia nierówności zbiorów. Dane związane z ceremonią przyznania nagród Grammy’s są właściwie marginalne (nieco ponad 4%). Tweety COVIDowe zapełniają natomiast nasz zbiór w ponad 80%. Jest to istotne, gdyż przy sprawdzaniu efektywności najbardziej naturalnym odniesieniem jest zwykłe prawdopodobieństwo. W zbiorze 100 “najbardziej podobnych” tekstów (do jakiegokolwiek), ok 80 powinno być związanych z COVID-19, nieco ponad 10 to najpewniej finansowe, natomiast muzyczne będą w liczbie kilku sztuk.
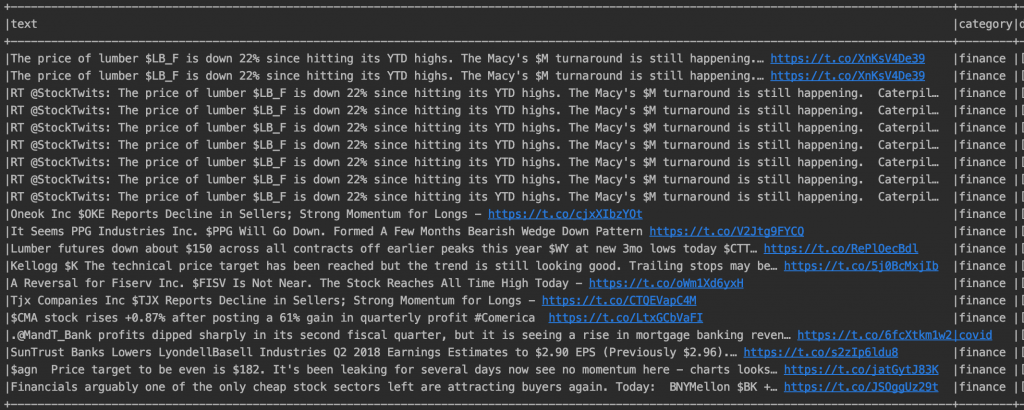
Text Similarity w Apache Spark na przykładzie wywołania tweetów związanych z COVID-19
Fraza covidowa, najprostsza
Wyszukiwania zacznijmy od najprostszego podejścia: frazą wyszukiwaną niech będzie podobna do tej, o której wiemy, że istnieje w podanym zbiorze. Liczba w nawiasie to stopień podobieństwa – od -1 do 1 (gdzie 1 to identyczne).
Fraza:Praying for health and recovery of @ChouhanShivraj . #covid #covidPositive (zmiany są bardzo drobne).
Podobne wykryte frazy:
Praying for good health and recovery of @ChouhanShivraj (0.9456217146059263)
Prayers for your good health and speedy recovery from #COVID19 @BSYBJP (0.801822609000082)
Hon’ble @CMMadhyaPradesh Shri @ChouhanShivraj Ji tested #COVID19 positive. Praying for his speedy recovery. (0.7740378229093525)
I pray for Former President Shri @CitiznMukherjee speedy recovery. Brain tumor wounds ji a lot, God may heal his p… (0.7626450268959205)
Jak widać każda z tych fraz pochodzi z grupy COVIDowych. Dodatkowo dotyczy pragnień szybkiego powrotu do zdrowia oraz modlitwy za cierpiących.
Fraza finansowa, trudniejsza
Przejdźmy do czegoś odrobinę trudniejszego – sprawdźmy coś finansowego. Niech będzie to fraza, którą absolutnie wymyślę od początku do końca.
Fraza:Ford’s earnings grow another quarter
Podobne wykryte frazy:
XLE Goes Positive Brent UP Big & WTI UP Big Rally $XOM ExxonMobil Buy Now for the Rest of 2018 GASOLINE INVENTORIE… (0.7579525402567442)
Morgan Stanley Begins Covering Murphy Oil $MUR Stock. “Shares to Hit $26.0” (0.7211353533183933)
Seaport Global Securities Lowers Cabot Oil & Gas Q2 2018 Earnings Estimates to $0.15 EPS (Previously $0.17).… (0.7211353533183933)
William E. Ford Purchases 1000 Shares of BlackRock Inc. $BLK Stock (0.7195004202231048)
Anadarko Petroleum Is On A Buyback Binge $APC (0.7187907206133348)
W tym przypadku podobieństwa są znacznie mniejsze. Warto zauważyć jednak dwie rzeczy: Po pierwsze – system wskazuje, że podobieństwa są mniejsze (0.76 to dużo mniej niż 0.95). Prawdopodobnie bardzo podobne po prostu więc nie istnieją. Druga rzecz – wszystkie podobne tweety pochodzą ze zbioru finansowych! Zbioru, który stanowi ok 14% całości danych. Pozwala to nabrać przekonania, że odpowiedzi nie są przypadkowe.
Fraza muzyczna, najtrudniejsza
Na koniec – najtrudniejsze zadanie ze wszystkich. Wybierzemy zdanie, które teoretycznie powinno pasować do zbioru będącego marginesem całości – do Grammy’s. Dodatkowo zdanie to wymyślę całkowicie. A niech tam – niech dotyczy najwspanialszej piosenkarki w dziejach! Oczywiście moim, zupełnie subiektywnym i amatorskim okiem;-).
Fraza:Amy Lee is the greatest singer of all time!
Christina Aguilera & Norah Jones were the only multiple recipients for ‘Best Female Pop Vocal Performance’ in the 2000s. (0.7306395709876714)
@billboardcharts @justinbieber @billieeilish @oliviarodrigo @taylorswift13 @kanyewest Taylor the only real queen let’s be honest she deserves the Grammy for evermore but the #GRAMMYs wont give her. (0.7019156211438091)
#GRAMMYs keep doing dirty to Lana Del Rey? Even though her talent is among the best this world has to offer (0.6868772967554752)
Kylie Minogue deserved at least one nomination for Magic #GRAMMYs (0.6820704278110573)
The answer will always be YES. #GRAMMYs #TwitterSpaces #SmallBusinesses #BlackOwned #adele #bts (0.6816903814884498)
I to właśnie te wyniki, przyznam, najmocniej wprowadziły mnie w euforię i ekscytację, gdy je zobaczyłem. I to nie tylko z powodu mojego niekłamanego uczucia do wokalistki Evanescence. Gdy spojrzymy na to “zdrowym, chłopskim okiem”, nie ma tutaj słowa o Grammy’s. Nie ma też szczególnego podobieństwa w słowach między pięcioma wymienionymi tweetami. Jest za to… kontekst. Jest podobieństwo tematyczne, jest znaczenie sensu.
A to wszystko naprawdę niedużym kosztem:-).
Text Similarity w Apache Spark na przykładzie wywołania tweetów muzycznych (z Grammy’s)
Apache Spark a text similarity – wykorzystane techniki
No dobrze, ale przejdźmy do konkretów – co należy zrobić, aby dostać takie wyniki? Tu zaproszę od razu do następnego artykułu, w którym pokażę dokładniej jak to zrobić. Dzisiejszy potraktujmy jako zajawkę. Żeby nie przeoczyć następnego – zapisz się na newsletter;-).
Po dość długich staraniach i wyeliminowaniu kilku ewidentnie beznadziejnych podejść, za sprawą kolegi Adama (za co ukłony w jego stronę) zacząłem czytać o embeddingach USE (Universal Sentence Encoder). Od razu powiem, że moją podstawową działką jest Big Data rozumiane jako składowanie i przetwarzanie danych. Sztuczna inteligencja to dopiero temat, który badam i definitywnie nie jestem w nim specem (choć parę kursów w tym kierunku ukończyłem i coś niecoś działałem). Liczę jednak, że obcowanie ze specami w tej działce (takimi jak właśnie Adam;-)) pomoże w eksploracji tego ciekawego gruntu.
Wróćmy jednak do USE. To była istne objawienie. Warto zaznaczyć, dla tych którzy nie do końca są zaznajomieni z tematyką machine learning, że komputer oczywiście tak naprawdę nie rozumie tekstu. Żeby mógł wyszukiwać podobieństwa, dzielić na grupy, uczyć się klas itd – potrzebne są liczby.Stąd wziął się pomysł sprowadzania tekstów do wektorów i różnego rodzaju wectorizerów – mechanizmów, które sprowadzają tekst do wektorów. Wektorów, czyli tablic jednowymiarowych o określonej długości (tu można się pomylić. Wielowymiarowe wektory dalej są jednowymiarowymi tablicami). Nieco bardziej rozbudowaną wersją są embeddingi, które mogą przechowywać w sobie wektory, natomiast które posiadają dodatkowe cechy pomocne. Jedną z nich (kluczową?) jest to, że słowa które chcemy zamienić na liczby, nabierają kontekstu. Pomaga to szczególnie mocno w niektórych przypadkach – na przykład naszych tweetów, które zawierają krótkie, czasami niezbyt treściwe przekazy. Jeśli będziemy je porównywali w prosty, czysto “statystyczny” sposób zestawiając wyrazy, nie uzyskamy odpowiedniego efektu.
Machine Learning w Apache Spark
Aby korzystać z dobrodziejstw ludzkości w zakresie machine learning, w tym text similarity w Apache Spark, należy wykorzystać bibliotekę Spark MlLib (w repozytorium Mavena dostępna tutaj). Tylko tutaj UWAGA! Wewnątrz biblioteki MlLib dostępne są dwa “rozgałęzienia”:
Spark MlLib – starsza (choć wciąż utrzymywana) wersja, operująca bezpośrednio na RDD.
Spark ML – nowocześniejsza część biblioteki. Możemy tutaj pisać operując na Datasetach i Dataframe’ach.
Wracając do technik – jednym z embeddingów jest właśnie USE. Jest on znacznie znacznie lepszym rozwiązaniem niż nieco podstarzały word2Vec, o innych, prostszych (np. Count Vectorizer) nie wspominając. Problem? Ano właśnie – nie wchodzi on w skład podstawowej biblioteki MlLib. Nie jest to jednak problem nie do przeskoczenia. Istnieje w Internecie gotowy zestaw rozwiązań, które poszerzają podstawowe biblioteki Sparkowe. Mam tu na myśli John Snow Labs. Udostępniają oni naprawdę imponująca liczbę algorytmów, które po prostu możemy wykorzystać – i to z całkiem niezłym skutkiem. Omówienie poszczególnych algorytmów można znaleźć tutaj. Samą bibliotekę do przetwarzania tekstu, czyli Spark-NLP zaciągniemy bez problemu z głównego repozytorium Mavena. To dzięki niej możemy rozwiązać bardzo wiele problemów, m.in. text-similarity w Apache Spark;-)
Jak technicznie dokładnie to zrobić, pokażę w kolejnym artykule. Już teraz zapraszam do subskrybowania;-).
Cosine Similarity
Skoro tylko udało mi się już porządnie sprowadzić tekst do jakiś ludzkich kształtów (czyli liczb;-)), należało znaleźć najlepszy z nich. Najlepszy – czyli najbardziej podobny do takiego, który wprowadzę. Dość dużo spędziłem czasu na szukaniu różnych gotowych rozwiązań. W końcu zdecydowałem się na zastosowanie czystej matematyki. Mowa tu o cosine similarity. Nie mam pojęcia jak to się tłumaczy na polski, a “podobieństwo kosinusowe” mi po prostu nie brzmi (ani nie znalazłem żeby tak się mówiło).
Z grubsza sprawa jest dość prosta – chodzi o to, żeby znaleźć podobieństwo między dwoma (niezerowymi) wektorami osadzonymi na jakiejś płaszczyźnie. Nie jest to żadna technika rakietowa i nie dotyczy ani NLP, ani nawet machine learning. Dotyczy zwykłej, prostej, nudnej matmy i można się zapoznać nawet na wikipedii.
Wzór na cosine similarity wygląda następująco:
Efekt jest prosty: wynik jest od -1 do 1. Im bliżej 1 tym bliższe są oba wektory. Problem? Oczywiście – w Sparku nie ma implementacji;-). Na szczęście jest to wzór na tyle prosty, że można go sobie zaimplementować samemu. Ja to zrobiłem w ramach UDF.
Podsumowanie
I to tyle! Tak więc można sprawę uprościć: zebrałem tweety, użyłem USE (od John Snow Labs) oraz cosine similarity. W efekcie dostałem naprawdę solidne wyniki podobieństwa. I to nie tylko jeśli chodzi o sam tekst, ale przede wszystkim jego znaczenie.
Już w najbliższym artykule pokażę jak dokładnie napisałem to w Sparku. Jeśli interesują Cię zagadnienia dotyczące Sparka, pamiętaj, że prowadzimy bardzo ciekawe szkolenia – od podstaw. Pracujemy z prawdziwymi danymi, na prawdziwych klastrach no i… cóż, uczymy się prawdziwego fachu;-). Jeśli interesuje Cię to – Zajrzyj tutaj!
Zostań z nami na dłużej. Razem budujmy polskie środowisko Big Data;-). Jeśli chcesz pozostać z nami w kontakcie – zapisz się na newsletter lub obserwuj RDF na LinkedIn. Koniecznie, zrób to i razem twórzmy polską społeczność Big Data!