Do tej pory poświęciłem dwa artykuły na dylemat cloud vs on-premise, czyli pytanie o to czy nasza infrastruktura techniczna powinna być serio nasza i stać u nas w serwerowni (albo – jak mój eksperymentalny klasterek – pod biurkiem;-)). Być może powinna zostać uruchomiona na maszynach wirtualnych wykupionych w ramach usług chmurowych? Nie ma jednej dobrej odpowiedzi na te tematy. Dzisiaj chciałbym jednak skomplikować temat jeszcze bardziej. Porozmawiajmy na temat tego czym jest hybrid cloud! No to Big Coffee w dłoń i ruszamy.
Zanim przejdziemy do pojęcia hybrid cloud, wyjaśnijmy pojęcie które będzie nam potrzebne – czyli private cloud, chmura prywatna. Jest to taki rodzaj usługi chmurowej, który odznacza się daleko idącym wydzieleniem zasobów sprzętowych na potrzeby klienta. Może to być zarówno przechowywane w miejscu jego pracy jak i u dostawcy chmurowego. To ostatnie jednak z zastrzeżeniem, że zasoby sprzętowe powinny realnie być oddzielone od reszty.
Stoi to w opozycji do chmury publicznej (ang. public cloud), gdzie dzielimy de facto zasoby z bardzo wieloma innymi użytkownikami (przy czym bazujemy na utworzonych dla nas maszynach wirtualnych lub kontach w konkretnych serwisach). Takie podejście pozwala zachować większe bezpieczeństwo i spełnić wymogi niektórych regulatorów.
Istnieje jeszcze pojęcie Virtual Private Cloud (VPC), czyli wirtualnej chmury prywatnej. Jest to de facto klasyczna chmura publiczna, która po prostu jest oddzielona logicznie od innych “uczestników” chmury (chodzi o tenantów;-)). Moim zdaniem jednak takie podejście ciężko nazywać “prywatnym” – nie spełnia bowiem podstawowych założeń chmury prywatnej, czyli udostepnienia klientowi zasobów “na wyłączność”, dzięki czemu mógłby osiągnąć większą kontrolę i bezpieczeństwo.
Oczywiście chmura to nie tylko wirtualne maszyny. Powstaje pytanie, jakie usługi może dostarczać dostawca chmurowy w ramach chmuryprywatnej? Odpowiedź poniżej.
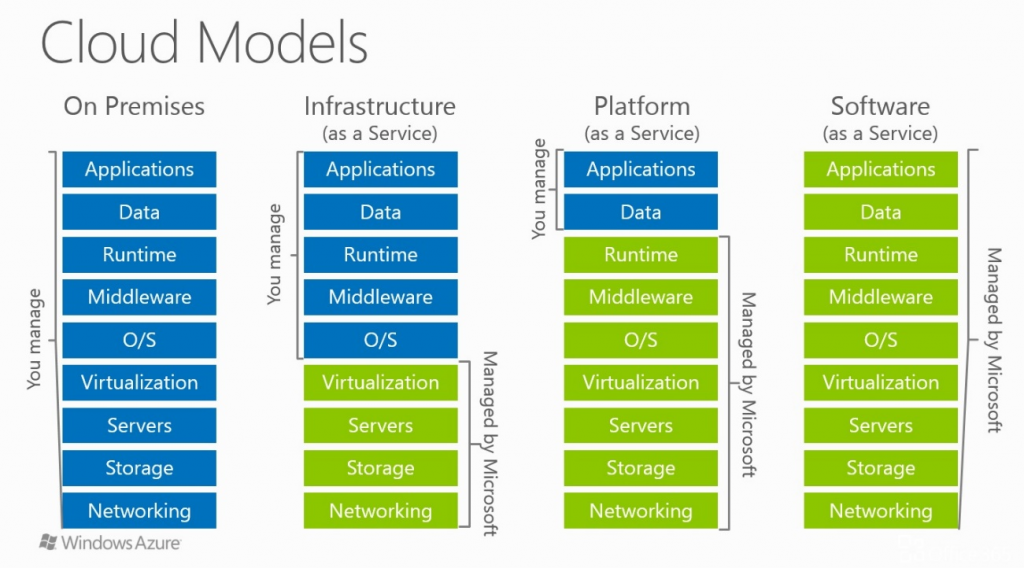
Infrastructure as a Service (IaaS) – A więc chmura przejmuje wirtualizację, serwery, storage i networking. Klient natomiast dba o resztę (system operacyjny, middleware, runtime, dane i aplikacje)
Platform as a Service (PaaS) – W tym przypadku po stronie klienta zostają już tylko dane i aplikacje.
Cały podział (razem z on-premise oraz SaaS) poniżej. Grafika pochodzi od Microsoftu i jest używana do opisu Azure.
Hybrid Cloud
Hybryda, jak to hybryda, łączy różne style. W tym przypadku łączymy public cloud z private cloud lub z on-premise. Jeśli używasz kombinacji tych trzech składników w jakiejkolwiek konfiguracji – znaczy, że Twoja infrastruktura jest hybrydowa.
Jakie są zalety rozwiązania hybrydowego? Otóż – przede wszystkim jest to pewna zwinność, elastyczność. Jak już wykazywałem w dwóch artykułach na temat dylematu “cloud vs on-premise” – nie ma jednoznacznie dobrego lub złego rozwiązania. Każde wiąże sięz pewnymi wadami i zaletami. Jeszcze lepiej byłoby stwierdzić, że każde powinno być dostosowane do określonej specyfiki danego problemu. Przykładowo – w rozwiązaniu on-premise problemem może być koszt personelu potrzebnego do serwisowania infrastruktury. Jeśli chodzi o chmurę, w niektorych, szczegolnie wrażliwych przypadkach problemem może być pytanie o to gdzie dokładnie dane są przechowywane (np. wrażliwe dane rządowe).
Decydując się na mix infrastruktury, zachowujemy elastyczność i zwinność. Możemy dostosować wady i zalety rozwiązań tak, aby finalna konstrukcja była idealnie dopasowana do charakterystyki naszego projektu.
Kolejną zaletą hybrid cloud może być także większa efektywność kosztowa. Możemy zauważyć na przykład, że dane chcemy co prawda trzymać na własnych maszynach, jednak przetwarzanie ich może czasami osiągać zawrotne wymagania jeśli chodzi o zasoby. W takiej sytuacji możemy przechowywać je u siebie, natomiast przetwarzać w chmurze, gdzie przydzielanie zasobów może odbywać się niezwykle prosto i dynamicznie.
Podsumowanie
Nie ma jednej prostej odpowiedzi na pytanie “co jest lepsze: chmura czy rozwiązania on-premise?”. Wszystko ma nie tylko swoje wady i zalety, ale i charakterystykę, która musi zostać dopasowana do problemu. Warto jednak pamiętać, że istnieją nie tylko dwie skrajne opcje, ale także rozwiązania hybrydowe. Można dzięki nim manipulować “suwakiem” kosztów, bezpieczeństwa, wygody itd. w inny sposób, niż zastanawiając się jedynie nad podstawowym wyborem.
Z pewnością będziemy kontynuować temat – dziś jedynie zajawka;-). Jeśli nie chcesz przegapić zmian, zapisz się na newsletter i obserwuj nasz profil na LinkedIn. Powodzenia!
Ostatnio miałem okazję rozmawiać z koleżanką, z którą pracuję w jednym projekcie. Być może warto dodać, że jest to projekt medyczno-genetyczny, bo rozmowa zeszła na kwestie etyczne. Zadała niezwykle ważne pytanie: “Czy ludzie pracujący w IT, ale przede wszystkim w Big Data, zdają sobie sprawę z tego w jak ważnej branży pracują? Czy wy myślicie o jakiś aspektach etycznych swojej pracy?”. No cóż – ja myślę od zawsze, kwestia wiary i wychowania. Czy jednak każdy myśli? Zapraszam dzisiaj do innego artykułu niż zwykle. Zaczniemy lekko łatwo i przyjemnie, ale to dopiero początek nowych tematów na blogu RDF;-). Zapraszam serdecznie;-)
Waga Big Data we współczesnym świecie
Dziś Big Data stało się moim zdaniem rdzeniem współczesnego świata. A jeśli jeszcze się nie stało, to zdecydowanie i bezpowrotnie staje się nim. To dzięki Big Data świat idzie do przodu i to dzięki tej branży może się rozwijać.
Ma to jednak swoje mroczne strony. Wszechobecna inwigilacja, przewidywanie każdego aspektu naszego życia, wojna informacyjna (i dezinformacja) na niespotykaną nigdy wcześniej skalę. Uzależnienia całych pokoleń od elektroniki i mediów społecznościowych, oszustwa finansowe, wielkie manipulacje społeczno-polityczne. Mógłbym wymieniać w nieskończoność.
Czy oznacza to, że żyjemy w najbardziej mrocznych czasach w historii? Moim zdaniem nie, choć złe tematy są znacznie, znacznie bardziej “klikalne”. Dobro bardzo często jest ciche, jednak robi ogromną i trwałą robotę. Dzisiaj nieśmiało chciałbym tym artykułem rozpocząć tematykę etyki w Big Data. Zacznijmy od prostego i przyjemnego tematu – a konkretnie kilku przykładów dobrego wykorzystania inteligentnego przetwarzania dużych danych.
3 projekty, które wykorzystują duże dane dla słusznej sprawy
Cloudera co roku wyłania 3 organizacje w ramach swojego konkursu “Data for good”. Oczywiście są to organizacje związane z Clouderą (poprzez korzystanie z ich produktów). Nie zmienia to jednak postaci rzeczy, że mamy tu znakomite przykłady inteligentnego zastosowania obsługi dużych danych do poprawy czegoś w naszym świecie. Zapraszam na krótki opis każdej z organizacji.
Union Bank (Union Bank of Philippines)
Tło całej sprawy to oczywiście COVID, który doprowadził do ciężkiej sytuacji ogromnej rzeszy Filipińczyków. Bardzo wielu z nich musiało coś zrobić, aby przetrwać ciężki czas ledwo wiążąc koniec z końcem. Jednym z podstawowych pomysłów jest pożyczka. Problem? Ponad 70 milionów osób było tam pozbawionych konta bankowego, przez to bank nie miał możliwości prostego sprawdzenia zdolności kredytowej.
Bank Filipiński skorzystał z Cloudera Data Science Workbench. Utworzyli oni ukierunkowany na dane system, który bazując na algorytmach AI pozwolił na szybszą predykcję swoich klientów – ich potencjalnego ryzyka i przydzielanych punktów kredytowych.
W rezultacie wskaźnik akceptacji kredytu wzrósł do 54%. Wzrosły też zyski banku, a co istotniejsze – miliony Filipińczyków mogły przetrwać kryzys. Oczywiście, tak, można zauważyć, że pożyczka nie jest najszczęśliwszym sposobem na utrzymanie się na powierzchni. Można też zwrócić uwagę, że końcem końców chodziło po prostu o zysk.
Tylko, że czasem kredyt to po prostu mniejsze zło. Jeśli zaś chodzi o zysk – cóż. Czy nie jest najlepszą sytuacja, w której zysk oparty jest o świadczenie naprawdę potrzebnych komuś usług?
Keck Medicine of USC
Druga organizacja która otrzymała wyróżnienie w “Data for good” to Keck Medicine of USC. Jest to przedsiębiorstwo medyczne Uniwersytetu Południowej Kalifornii. W tym przypadkiem tło jest chyba jeszcze “cięższe” niż poprzednio. Chodzi mianowicie o uzależnienia od opioidów. Według HHS, w 2019 roku ok 10.1 mln osób (w USA) nadużywało leków opioidowych. W 2018 roku natomiast opioidy były odpowiedzialne za 2/3 zgonów związanych z przedawkowaniem narkotyków.
W Keck Medicine od USC uznali, że spora część uzależnień może wynikać ze złych standardów (lub nie trzymania się dobrych praktyk) przypisywania środków przeciwbólowych przez lekarzy (najczęściej po operacjach lub w przypadku leczenia szczególnie przewlekłych, wyniszczających stanów). W związku z tym utworzony został projekt mający na celu wgląd w praktyki lekarzy. Centralnym punktem był Data Lake, który eliminował potencjalne błędy manualnego zbierania danych. Dodatkowo pozwalał spojrzeć “z lotu ptaka” na dane z całej organizacji.
Dzięki zaawansowanej analityce, naukowcy i lekarze mogą wykrywać najbardziej ryzykowne sytuacje i podjąć odpowiednią reakcję, taką jak edukacja. Dzięki systemowi organizacja może lepiej zadbać o swoich pacjentów, unikając uzależnień zamiast w nie (przypadkowo) wpędzać.
National organisation for rare disorders (National Marrow Donor Program)
Tło to tym razem nowotwory krwi, takie jak białaczka, na które co 10 minut ktoś umiera (tak, wciąż nic wesołego). Wielu z tych ludzi mogłoby żyć, gdyby znaleźli się dawcy na przeszczep szpiku kostnego. Niestety, u 70% osób nie ma odpowiednich osób do przeszczepu wśród najbliższej rodziny.
National Organisation for rare disorders utworzyła National Marrow Donor Program, który ma na celu kojarzenie ze sobą osób potrzebujących i dawców. W ich bazach jest obecnie zarejestrowanych 44 miliony osób. Jak nietrudno się domyślić, sprawne przeszukiwanie bazy to robota dla Big Data. Organizacja razem z Clouderą utworzyła odpowiedni system, dzięki czemu możliwe jest przeszukiwanie milionów rekordów w minutę.
Warto dodać, że na ten moment program pomógł uratować życie ponad 6 600 biorcom szpiku. To absolutnie rewelacyjna wiadomość!
Podsumowanie
Dziś zdecydowanie inny artykuł niż przeważnie. Tak już jest, że Big Data jest medalem, który ma bardzo, bardzo wiele stron. Chciałbym pisać tu o możliwie wielu z nich. Mam nadzieję, że dzisiejszy opis trzech organizacji które robią z danymi coś bardzo, bardzo sensownego, zainspiruje do innego myślenia.
Zostaw komentarz, podaj artykuł dalej i… cóż, koniecznie dołącz do nas na LinkedIn oraz newsletterze. Zostańmy w kontakcie dłużej i razem budujmy polską społeczność Big Data!
Wielokrotnie na tym blogu tłumaczyłem zawiłości Big Data od podstaw (nie oszukujmy się – sam wielokrotnie pisałem to także dla siebie, chcąc usystematyzować wiedzę). Nie tylko technicznie, ale i “z lotu ptaka”, biznesowo. Zawsze żałowałem, że muszę to robić “po łebkach”, w skondensowanej formie, wyrywkowo. Czym innym jest przedstawić jakieś okrojone zagadnienie a czym innym móc wyjaśnić kontekst, zagłębić się, pozwolić sobie na więcej, szerzej, głębiej. Postanowiłem dołączyć do bloga RDF jeden element, który rozwiąże ten problem. I jestem szalenie ciekawy, co o tym sądzisz!
UWAGA! Pierwszy polski ebook o Big Data już dostępny! Zapisz się na listę newslettera i podążaj “Szlakiem Big Data”. Więcej tutaj.
Ebook o Big Data. Po polsku!
No właśnie. Idealnym miejscem aby się zagłębić w temat i przedstawić coś od A do Z jest książka. A najlepiej, żeby była to książka powszechna, dostępna za darmo dla każdego. No więc co? No więc ebook!
Celem ebooka będzie wprowadzenie do branży Big Data. Od historii, filozofii, przez przegląd technologii i architektur. Na słowniczku skończywszy, o. Czy ma wyczerpać temat? Odpowiedź jest oczywista – nie da się go wyczerpać. Ja, po kilku latach naprawdę wytężonej pracy w BD, czuję się… jak kompletny świeżak.
Cel: traktuję Ebooka raczej jako furtkę do świata Big Data. Ja wyjmuję klucz i ją otwieram. Potem Ty dalej już wiesz gdzie iść.
Całość będzie napisana po polsku. RDF powstał po to, żeby szkolić i doradzać tu, w Polsce. Blog jest tego emanacją i podstawowym elementem budowy naszej społeczności Big Data.
Jak będzie zbudowany ebook o Big Data? (Spis Treści)
Przejdźmy do konkretu. Co znajdziesz w ebooku? Pomyślałem o kilku częściach:
Miękkie wprowadzenie do Big Data – czyli opis jak to się wszystko zaczęło (historia) oraz filozofia myślenia w branży. Nie pomijaj tego! Dzięki temu rozdziałowi zobaczysz jak zaczęła toczyć się ta kula śnieżna i… nauczysz się myśleć “po bigdatowemu”.
Opis kluczowych technologii – oczywiście nie będziemy tu robić kursów;-). Poznasz tam zgrubne zestawienie tego jaka technologia służy do jakiego celu. Już bardziej techniczne, ale bez przesady.
Rozważania architektoniczne – wbrew pozorom przyda się nie tylko inżynierom, ale także menedżerom. Do głębszego zrozumienia. Choć, powiedzmy szczerze, Ci ostatni mogą ten rozdział “przelecieć wzrokiem”.
Odwieczny dylemat: cloud czy on-premise? Czyli pytanie o to, czy samodzielnie tworzyć infrastrukturę czy skorzystać z dostawców.
Słowniczek – gdyby coś w trakcie było niezbyt zrozumiałe. Tylko nie zakuwaj za dużo!
Jestem jednak otwarty na różne sugestie. Mogę to zarówno pociąć jak i dobudować.
Zdjęcie bardzo poglądowe;-) Okładkę ebooka o Big Data też zaprojektujemy wspólnie!
UPDATE! 20.07.2022 – premiera ebooka. Dołącz do newslettera, aby otrzymać go za darmo.
Włącz się w tworzenie!
No właśnie – otwarty na sugestie. Twoje. Mam przynajmniej taką nadzieję. Ebook będzie znacznie bardziej wartościowy jeśli dowiem się od Was co was nurtuje, czego nie rozumiecie. A może co było trudne na początkowym etapie rozwoju? Każda uwaga jest cenna.
Jest jednak mały “haczyk”. Chcę, żebyśmy tworzyli jedno naprawdę spójne środowisko. Najlepiej bez pośredników w postaci mediów społecznościowych (w końcu pracuję w Big Data! Wiem jak to działa;-)). W związku z tym cały proces twórczy będzie opierał się o newsletter.
W ramach newslettera będę komunikował znacznie, znacznie więcej niż dotychczas.
Przez newsletter dostaniesz każdy kolejny kawałek skończonego ebooka.
Będziesz mógł odpowiedzieć na konkretny email i zasugerować zmiany. Jestem otwarty na rozmowę, a nawet czekam na nią!
Ebook będzie później dostępny dla każdego newsletterowicza. Pomagając więc tworzyć książkę, w sposób najpełniejszy wspierasz społeczność. Razem możemy zbudować coś, od czego wyjdzie każdy nowy Inżynier Big Data i menedżer BigDato-świadomy (:D).
Aby tak się stało, zapisz się na newsletter już teraz:
Podsumowanie – jak włączyć się w proces twórczy?
No więc, podsumowując: zaczynam (już zacząłem;-)) tworzenie ebooka o Big Data. Pierwszy taki na polskim rynku. Będzie w całości za darmo dla newsletterowiczów RDF. Co więcej – jeśli jesteś (lub zostaniesz) subskrybentem, możesz włączyć się w proces twórczy:
Każdorazowo gdy skończę jakiś większy fragment, wyślę Ci go do sprawdzenia.
Ponadto możesz odpowiadać na emaile i podpowiadać jakie poprawki chcesz wprowadzić. Zarówno te drobne (jeszcze jedna technologia?) jak i te fundamentalne (nowy dział?).
Jestem głęboko przekonany, że razem zbudujemy coś wyjątkowego! Dołącz także do naszego LinkedIn i podaj artykuł znajomym, którzy mogą być zainteresowani;-).
Dokonując transformacji w Sparku, bardzo często korzystamy z gotowych, wbudowanych rozwiązań. Łączenie tabel, explodowanie tablic na osobne wiersze czy wstawianie stałej wartości – te i wiele innych operacji zawarte są jako domyślne funkcje. Może się jednak okazać, że to nie wystarczy. Wtedy z pomocą w Sparku przychodzi mechanizm UDF (User Defined Function).
Dzisiaj o tym jak krok po kroku stworzyć UDFa, który może być wyorzystany w wygodny sposób wszędzie w projekcie. Do dzieła! Całą serię “zrozumieć sparka” poznasz tutaj.
Co to jest UDF w Sparku?
Wczuj się w sytuację. Tworzysz joba sparkowego, który obsługuje dane firmowe dotyczące pracowników. Chcesz przyznawać premie tym najlepszym, najwierniejszym i najbardziej pracowitym i zyskownym. Po zebraniu potrzebnych informacji w jednym DataFrame, będziemy chcieli utworzyć kolumnę “bonus” która zawiera prostą informację: kwotę premii na koniec roku.
Aby to wyliczyć, został utworzony wcześniej wzór. Wykorzystując informacje dotyczące stanowiska, zyskowności projektu, oceny współpracowników, przepracowanych godzin i kilku innych rzeczy. Oczywiście nie ma możliwości, żeby wyliczyć to przy pomocy zwykłych funkcji. Z drugiej jednak strony, jeśli mielibyśmy jednostkowo wszystkie potrzebne dane – nie ma problemu, aby taki wzór zakodować.
Temu właśnie służą sparkowe UDFs, czyli User Defined Functions. To funkcje, których działanie sami możemy napisać i które pozwolą nam na modyfikację Datasetów w sposób znacznie bardziej customowy. Można je utworzyć na kilka różnych sposobów, ale ja dzisiaj chciałbym przedstawić Ci swój ulubiony.
A ulubiony dlatego, ponieważ:
Jest elegancko zorganizowany
Daje możliwość wielokrotnego wykorzystywania UDFa w całym projekcie, przy jednokrotnej inicjalizacji go.
Jak zbudować UDF w Apache Spark? Instrukcja krok po kroku.
Instrukcja tworzenia UDFa jest dość prosta i można ją streścić do 3 kroków:
Stwórz klasę UDFa (rozszerzającą UDFX – np. UDF1, jeśli mamy do podania jedną kolumnę).
ZarejestrujUDFa.
Wywołaj UDFa podczas dodawania kolumny.
Scenariusz
Zobrazujmy to pewnym przykładem. Mamy do dyspozycji dataframe z danymi o ludziach. Chcemy sprawdzić zagrożenie chorobami na podstawie informacji o nich. Dla zobrazowania – poniżej wygenerowany przeze mnie Dataframe. Taki sobie prosty zestaw:-).
Efekt który chcemy osiągnąć? te same dane, ale z kolumną oznaczającą zagrożenie: 1- niskie, 2-wysokie, 3-bardzo wysokie. Oczywiście bardzo tu banalizujemy, w rzeczywistości to nie będzie takie proste!
Załóżmy jednak, że mamy zakodować następujący mechanizm: zbieramy punkty zagrożenia.
Bycie palaczem daje +20 do zagrożenia,
Wiek ma przedziały: do 30 lat (+0); do 60 lat (+10); do 80 lat (+20); powyżej (+40)
Aktywności fizyczne: jeśli są, to każda z nich daje -10 (czyli zabiera 10 pkt).
Tak, wiem – to nawet nie banalne, a prostackie. Rozumiem, zebrałem już baty od siebie samego na etapie wymyślania tego wiekopomnego dzieła. Idźmy więc dalej! Grunt, żeby był tutaj jakiś dość skomplikowany mechanizm (w każdym razie bardziej skomplikowany od takiego który łatwo możemy “ograć” funkcjami sparkowymi).
Krok 1 – Stwórz klasę UDFa
Disclaimer: zakładam, że piszemy w Scali (w Javie robi się to bardzo podobnie).
Oczywiście można też zrobić samą metodę. Ba! Można to “opękać” lambdą. Jednak, jak już napisałem, ten sposób rodzi największy porządek i jest moim ulubionym;-). Utwórz najpierw pakiet który nazwiesz “transformations”, “udfs” czy jakkolwiek będzie dla Ciebie wygodnie. Grunt żeby trzymać wszystkie te klasy w jednym miejscu;-).
Wewnątrz pakietu utwórz klasę (scalową) o nazwie HealtFhormulaUDF. Ponieważ będziemy przyjmowali 3 wartości wejściowe (będące wartościami kolumn smoker, age i activities), rozszerzymy interfejs UDF3<T1, T2, T3, R>. Oznacza to, że musimy podczas definicji klasy podać 3 typy wartości wejściowych oraz jeden typ tego co będzie zwracane.
Następnie tworzymy metodę call(T1 t1, T2 t2, T3 t3), która będzie wykonywać realną robotę. To w niej zaimplementujemy nasz mechanizm. Musi ona zwracać ten sam typ, który podaliśmy na końcu deklaracji klasy oraz przyjmować argumenty, które odpowiadają typami temu, co podaliśmy na początku deklaracji. Gdy już to mamy, wewnątrz należy zaimplementować mechanizm, który na podstawie wartości wejściowych wyliczy nam nasze ryzyko zachorowania. Wiem, brzmi to wszystko odrobinę skomplikowanie, ale już pokazuję o co chodzi. Spójrz na skończony przykład poniżej.
package udfs
import org.apache.spark.sql.api.java.UDF3
class HealthFormulaUDF extends UDF3[String, Int, String, Int]{
override def call(smoker: String, age: Int, activities: String): Int = {
val activitiesInArray: Array[String] = activities.split(",")
val agePoints: Int = ageCalculator(age)
val smokePoints: Int = if(smoker.toLowerCase.equals("t")) 20 else 0
val activitiesPoints = activitiesInArray.size * 10
agePoints + smokePoints - activitiesPoints
}
def ageCalculator(age: Int): Int ={
age match {
case x if(x < 30) => 0
case x if(x >= 30 && x < 60) => 10
case x if(x >= 60 && x < 80) => 20
case _ => 40
}
}
}
Dodałem sobie jeszcze pomocniczą funkcję “ageCalculator()”, żeby nie upychać wszystkiego w metodzie call().
Zarejestruj UDF
Drugi krok to rejestracja UDF. Robimy to, aby potem w każdym miejscu projektu móc wykorzystać utworzony przez nas mechanizm. Właśnie z tego powodu polecam dokonać rejestracji zaraz za inicjalizacją Spark Session, a nie gdzieś w środku programu. Pozwoli to nabrać pewności, że ktokolwiek nie będzie w przyszłości wykorzystywał tego konkretnego UDFa, zrobi to po rejestracji, a nie przed. Poza tym utrzymamy porządek – będzie jedno miejsce na rejestrowanie UDFów, nie zaś przypadkowo tam gdzie komuś akurat się zachciało.
Aby zarejestrować musimy najpierw zainicjalizować obiekt UDFa. Robimy to w najprostszy możliwy sposób. Następnie dokonujemy rejestracji poprzez funkcję sparkSession.udf.register(). Musimy tam przekazać 3 argumenty:
Nazwę UDFa, do której będziemy się odnosić potem, przy wywoływaniu
Obiekt UDFa
Typ danych, jaki zwraca konkretny UDF (w naszym przypadku Integer). UWAGA! Typy te nie są prostymi typami Scalowymi. To typy sparkowe, które pochodzą z klasy DataTypes.
Poniżej zamieszczam całość, razem z inicjalizacją sparkSession aby było wiadomo w którym momencie t uczynić;-).
val sparkSession = SparkSession.builder()
.appName("spark3-test")
.master("local")
.getOrCreate()
val healthFormulaUDF: HealthFormulaUDF = new HealthFormulaUDF()
sparkSession.udf.register("healthFormulaUDF", healthFormulaUDF, DataTypes.IntegerType)
W tym momencie UDF jest już zarejestrowany i można go wywoływać gdziekolwiek w całym projekcie.
Wywołaj UDF
Ostatni krok to wywołanie UDFa. To będzie bardzo proste, ale musimy zaimportować callUDF z pakietu org.apache.spark.sql.functions (można też zaimportować wszystkie funkcje;-)).
Ponieważ chcemy utworzyć nową kolumnę z liczbą punktów, skorzystamy z funkcji withColumn(). Całość poniżej.
val peopleWithDiseasePoints: Dataset[Row] = peopleDF.withColumn("diseasePoints",
callUDF("healthFormulaUDF", col("smoker"), col("age"), col("activities")))
Efekt jest jak poniżej. Im mniej punktów w “diseasePoints” tym lepiej. Cóż, chyba nie mam się czym przejmować, mam -20 pkt!
Podsumowanie
W tym artykule dowiedzieliśmy się czym w Apache Spark jest UDF. Zasadniczo całość można sprowadzić do 3 prostych kroków:
Stwórz klasę UDFa (rozszerzającą UDFX – np. UDF1, jeśli mamy do podania jedną kolumnę).
ZarejestrujUDFa.
Wywołaj UDFa podczas dodawania kolumny.
To był materiał z serii “Zrozumieć Sparka”. Nie pierwszy i definitywnie nie ostatni! Jeśli jesteś wyjątkowo głodny/a Sparka – daj znać szefowi. Przekonaj go, żeby zapisał Ciebie i Twoich kolegów/koleżanki na szkolenie ze Sparka. Omawiamy całą budowę od podstaw, pracujemy dużo i intensywnie na ciekawych danych, a wszystko robimy w miłej, sympatycznej atmosferze;-) – Zajrzyj tutaj!
A jeśli chcesz pozostać z nami w kontakcie – zapisz się na newsletter lub obserwuj RDF na LinkedIn. Koniecznie, zrób to i razem twórzmy polską społeczność Big Data!
Za mną już znacznie ponad 20 mięsistych, wyczerpujących wpisów. Wciąż jednak brakuje fundamentalnego “Co to jest Big Data?”. Na to pytanie można odpowiadać godzinami. Dziś chciałbym jednak spojrzeć z biznesowej perspektywy. Nie będzie zbyt wielu technikaliów. Nie będziemy rozważać ile executorów powinno się ustawiać w spark-submit, ani czym różni się HBase od Accumulo. Ten artykuł przeznaczony jest dla osób zarządzających. Dla tych, którzy chcą pchnąć firmę na wyższy poziom i zastanawiają się, co to jest ta Big Data. Kubek z kawą na biurko… i ruszamy!
Jak to się zaczęło?
Zanim przejdziemy do samego sedna, bardzo istotna jest jedna rzecz: Big Data to naprawdę duża, złożona działka. Ciężko opisać ją w kilku punktach. Żeby ją zrozumieć, trzeba podejść z w kilku różnych kontekstach. Zacznijmy od krótkiej historii początków. Dzięki temu prawdopodobnie nie tylko zrozumiemy kontekst, ale i kilka cech charakterystycznych tej branży – co przyda się w podejmowanych decyzjach biznesowych.
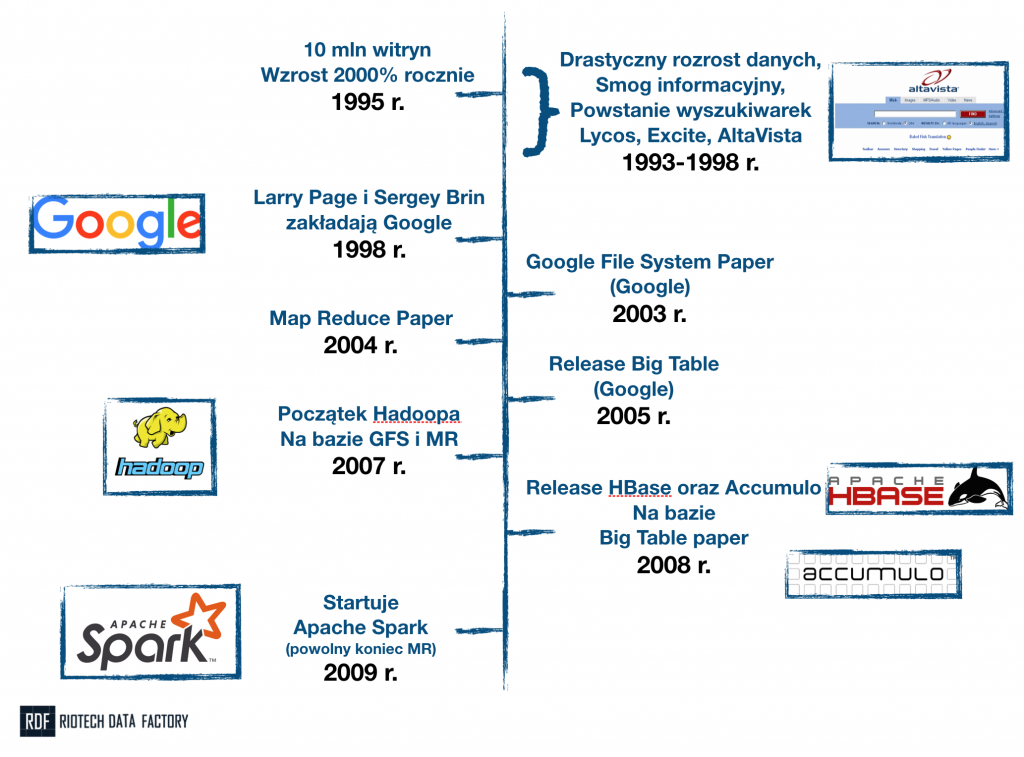
Jak to często bywa z historią, początki są niejasne i każdy może mieć troszkę swoją własną teorię. Moim zdaniem jednak, definitywny początek Big Data ma… w Google. Tak – znana nam wszystkim korporacja (i wyszukiwarka) jest absolutnie najbardziej zasłużoną organizacją dla tej branży. Niezależnie od rozmaitych swoich grzeszków;-). Ale spójrzmy jeszcze wcześniej – do roku 1995. To wtedy Internet przybiera na sile. Jego rozmiary są nie do końca znana, natomiast sięga już przynajmniej 10 mln witryn. Co “gorsza”… rozwija się w tempie 2000% rocznie.
AltaVista była pierwszą, przełomową wyszukiwarką
Chaos Internetowy lat 90′
Kluczową dla funkcjonowania Internetu rzeczą, są wyszukiwarki. Dziś to dla nas rzecz oczywista, ale w 95′ wcale tak nie było. Jeśli jednak nie będzie wyszukiwarek, nie znajdziemy znakomitej większości rzeczy, których potrzebujemy. Problem polega na tym, że wyszukiwarki nie przeszukują całego internetu za każdym razem. One zapisują strony (w odpowiedniej strukturze, niekoniecznie całe strony) w swoich bazach danych. Następnie przeszukują te bazy, kiedy użytkownik przekaże zapytanie.
Wniosek jest oczywisty: wyszukiwarki to nie nudne “lupki”, a bardzo zaawansowana technologicznie maszyneria. Maszyneria, która potrzebuje dożo miejsca na dysku, dużo pamięci podręcznej oraz mocy obliczeniowej. Jak bardzo, przekonali się o tym Larry Page i Sergey Brin, którzy w 1998 roku zakładają Google. Z czasem bardzo szybko orientują się, że przyrost danych jest zbyt ogromny na jakikolwiek komputer.
I tutaj pojawia nam się pierwsza, najważniejsza (moim zdaniem) zasada, charakterystyka Big Data. Inżynierowie sporej już wtedy firmy, rozpoczęli prace nad technologią, która pozwoli przechowywać oraz przetwarzać bardzo duże dane (których jest więcej i więcej i więcej…). Ci jednak, zamiast skonstruować olbrzymi super-komputer, którym zaimponują światu, poszli w zupełnie inną stronę. Uznali, że i tak prędzej czy później (a raczej prędzej) skończy im się miejsce i moc obliczeniowa. Co wtedy, nowy super-komputer? No właśnie nie.
Podejście rozproszone (distributed)
Znacznie lepszym pomysłem będzie zbudowanie takiego oprogramowania, które pozwoli połączyć bardzo wiele komputerów. I korzystać z nich tak, jakbyśmy mieli jeden wielki komputer. Co kiedy skończą się możliwości? Cóż – po prostu dorzucimy kolejne mniejsze komputery do naszego ekosystemu. Takie podejście nazywa się podejściem “rozproszonym” (ang. distributed). Tak właśnie powstaje Google File System (GFS) oraz opublikowany zostaje Google File System Paper, na którym opisana jest architektura wynalazku. Rok i dwa lata później publikowane są kolejne przełomowe dokumenty: Map Reduce (MR) Paper (który opisuje technologię do przetwarzania danych) i Big Table Paper.
Czemu Google to fundament Big Data? Bo na wyżej wymienionych dokumentach powstają najbardziej fundamentalne technologie open-source. Fundacja Apache ogłasa w 2007 roku, że na bazie GFS oraz MR powstaje Hadoop – prawdopodobnie najbardziej znana technologia Big Data. Rok później, znów na bazie dokumentu Google (Big Table Paper) powstają dwie bazy danych: HBase oraz Accumulo.
Historia Big Data. Od chaosu w Internecie na początku lat 90′ do zaawansowanych technologii Big Data XXI wieku.
Co to jest Big Data? Zasada 3V
Skoro wiemy już jak to się wszystko zaczęło, przejdźmy do podstawowego pytania: Co to tak naprawdę jest Big Data? Skonkretyzujmy to sobie nieco. Jesteśmy w IT, więc postarajmy się zdefiniować tą materię. Dawno temu wyznaczona została zasada, która określa czym jest Big Data. Zasada ta była później rozwijana, natomiast my przyjrzymy się pierwotnej wersji. Dodajmy – wersji, która moim zdaniem jest najlepsza, każda kolejna to już troszeczkę budowa sztuki dla sztuki;-).
Chodzi mianowicie o wytłuszczoną w nagłówku zasadę 3V. Określa ona cechy danych, które najmocniej charakteryzują Big Data.
Volume (objętość) – najbardziej intuicyjna cecha. Wszyscy dobrze rozumiemy, że jak data mają być big, to muszą mieć “dużą masę”. Ile dokładnie, ciężko stwierdzić. Niektórzy mówią o dziesiątkach GB, inni dopiero o terabajtach danych.
Velocity (prędkość) – to już nieco mniej oczywista rzecz. Moim zdaniem jednak bardzo istotna dla zrozumienia naszej materii. Wyobraź sobie, że śledzisz wypowiedzi potencjalnych klientów w mediach społecznościowych. W tym celu analizujesz wszystkie posty z określonymi tagami. Można się domyślić jak szybko przybywa tych danych (i jak bardzo często są one nie do użycia, ale to już inna sprawa). Tutaj właśnie objawia się drugie “V”. Wielokrotnie mamy do czynienia nie tylko z dużymi danymi, ale także z danymi które napływają lub zmieniają się niezwykle szybko. To ogromne wyzwanie. Znacząco różni się od stanu, w którym po prostu musimy przetworzyć paczkę statycznych, zawsze takich samych danych.
Variety (różnorodność) – I ta cecha prawdopodobnie jest już zupełnie nieintuicyjna (w pierwszym odruchu). Dane które dostajemy bardzo często nie są pięknie ustrukturyzowane, ułożone, wraz z dostarczonymi schematami. Wręcz przeciwnie! To dane, które często są nieustrukturyzowane, w których panuje chaos. Dane, które nawet w ramach jednego zbioru są różne (np. wiadomości email). Są to wyzwania z którymi trzeba się mierzyć i do których zostały powołane odpowiednie technologie – technologie Big Data.
Big Data w biznesie – kiedy zdecydować się na budowanie kompetencji zespołu?
Skoro już wiemy jak to się zaczęło i czym to “dokładnie” jest, czas postawić to kluczowe pytanie. Przynajmniej kluczowe z Twojej perspektywy;-). Kiedy warto zdecydować się na budowanie kompetencji Big Data w zespole? Nie będę zgrywał jedynego słusznego mędrca. Ta branża jest skomplikowana niemal tak jak życie. Nie ma jednego zestawu wytycznych. Podzielę się jednak swoimi spostrzeżeniami.
Poniżej wymieniam 5 sytuacji, które mogą Ci się przydać. Bądźmy jednak szczerzy – to pewna generalizacja. Być może jednak całkiem przydatna;-).
Na horyzoncie pojawia się projekt, który nosi znamiona Big Data
Niezależnie od tego jaki jest charakter Twojej firmy, prace poukładane są w coś co nazwiemy “projektami”. Ten punkt sprawdzi się szczególnie wtedy, gdy outsourceujecie zasoby ludzkie lub robicie zlecaną przez innych robotę. W takiej sytuacji może na horyzoncie pojawić się projekt “legacy”, który ma kilka cech charakterystycznych:
Wykorzystywane są technologie Big Data. Dokładniej na temat tego jakie technologie za co odpowiadają, znajdziesz tutaj. Miej jednak radar nastawiony przynajmniej na kilka z nich:
Hadoop (w tym HDFS, Yarn, MapReduce (tych projektów nie bierz;-)).
Hive, Impala, Pig
Spark, Flink
HBase, MongoDB, Cassandra
Kafka,
“Przerzucane” są duże ilości danych (powyżej kilkudziesięciu gigabajtów)
Projekt bazuje na bardzo wielu różnych źródłach danych
Projekt pracuje na średnich ilościach danych (dziesiątki gb), ale pracuje bardzo niewydajnie, działa wolno i sprawia przez to problemy.
I inne;-). Jeśli widzisz projekt, który na odległość pachnie zapychającymi się systemami, technologiami Big Data i różnorodnością danych – wiedz, że czas najwyższy na budowę zespołu z odpowiednimi możliwościami.
Projekt nad którym pracujecie, przerósł wasze oczekiwania
Wielokrotnie bywa tak, że mechanizmy zbudowane w ramach jakiegoś projektu są dobre. Szczególnie na początkowym etapie, kiedy danych nie ma jeszcze zbyt wielu. Potem jednak danych przybywa, źródeł przybywa i… funkcjonalności przybywa. Tylko technologie i zasoby pozostają te same. W takim momencie proste przetwarzanie danych w celu uzyskania raportów dziennych trwa na przykład 6 godzin. I wiele wskazuje na to, że będzie coraz gorzej.
Ważne, żeby podkreślić, że nie musi to być wina projektantów systemu. Czasami jednak trzeba dokonać pivotu i przepisać całość (albo część!) na nowy sposób pracy. Nie jest to idealny moment na rozpoczęcie wyposażania zespołu w kompetencję Big Data. Może to być jednak konieczne.
Zapada decyzja o poszerzeniu portfolio usługowego
Tu sprawa jest oczywista. Świadczycie usługi IT. Robicie już znakomite aplikacje webowe, mobilne, pracujecie w Javie, Angularze i Androidzie. Podejmujecie decyzję żeby poszerzyć portfolio o usługi w ramach Big Data. To nie będzie łatwe! Należy zbudować całą strukturę, która pozwoli odpowiednio wyceniać projekty, przejmować dziedziczony (legacy) kod czy projektować systemy. Trzeba się do tego przygotować.
Czy trzeba budować cały nowy dział od 0? Absolutnie nie – można bazować na już istniejących pracownikach, choć z całą pewnością przydałby się senior oraz architekt. Warto jednak pamiętać, że cały proces powinien rozpocząć się na wiele miesięcy przed planowanym startem publicznego oferowania usług Big Data.
Organizacja znacząco się rozrasta wewnętrznie
Bardzo często myślimy o przetwarzaniu dużych danych na potrzeby konkretnych projektów, produktów itd. Jednym słowem, zastanawiamy się nad dość “zewnętrznym” efektem końcowym. Musimy jednak pamiętać, że równie cennymi (a czasami najcenniejszymi) danymi i procesami, są te wewnętrzne. Big Data nie musi jedynie pomagać nam w wytworzeniu wartości końcowej. Równie dobrze możemy dzięki obsłudze dużych danych… zmniejszyć chaos w firmie. Nie trzeba chyba nikomu tłumaczyć jak zabójczy potrafi być chaos w organizacji. I jak łatwo powstaje.
Do danych wewnętrznych zaliczymy wszystko co jest “produktem ubocznym” funkcjonowania firmy. Na przykład dane dotyczące pracowników, projektów, ewaluacji itd. Także klientów, zamówień, stanów magazynowych. Jeśli uda nam się na to wszystko nałożyć dane geolokalizacyjne i garść informacji ze źródeł ogólnodostępnych, możemy zacząć budować sobie całkiem konkretne raporty dotyczące profili klientów. Gdy pozyskamy kilka wiader bajtów z serwisów promocyjnych i inteligentnie połączyć z resztą – możemy dowiedzieć się o racy firmy, klientach oraz nadchodzących okazjach znacznie więcej, niż wcześniej. I więcej, niż konkurencja;-).
Chmura czy własna infrastruktura? (Cloud vs On-Premise)
Gdy jesteśmy już świadomi branży Big Data oraz okoliczności, w jakich warto w nią wejść – zastanówmy się nad najbardziej fundamentalną rzeczą. Mowa o infrastrukturze komputerowej, którą będziemy wykorzystywać. Mówiąc bardzo prosto: nasze technologie muszą być gdzieś zainstalowane, a dane gdzieś przechowywane. Pytanie zwykle dotyczy wyboru między dwoma ścieżkami: albo będziemy mieli swoją własną infrastrukturę, albo wykorzystamy gotowych dostawców chmurowych.
Które podejście jest lepsze? Odpowiedź jest oczywista: to zależy. Nie ma jednego najlepszego podejścia. To przed czym chcę Cię w tym miejscu przestrzec, to przed owczym pędem w kierunku chmur. Zwykło się myśleć, że aplikacja działająca w chmurze, to aplikacja innowacyjna, nowoczesna, lepsza. To oczywiście nie jest prawda.
Czym jest Cloud a czym On-premise
Żeby w ogóle wiedzieć o czym mówimy, zacznijmy od uproszczonego wyjaśnienia, które jakoś nas ukierunkuje.
Własna infrastruktura (On-Premise, często skrótowo po prostu „on-prem”) – komputery, które fizycznie do nas należą, są przechowywane gdzieś „na naszym terytorium”. Samodzielnie łączymy je siecią, instalujemy tam odpowiednie oprogramowanie, synchronizujemy itd. Specjalnie do tego typu infrastruktury stworzona została m.in. popularna platforma Big Data Apache Hadoop. Stawiając on-premise musimy zadbać o samodzielną obsługę całości, natomiast koszt związany z zasobami jest „jednorazowy” w momencie zakupu sprzętu (potem oczywiście jeśli chcemy ją rozbudować).
Chmura (Cloud) – czyli instalacja odpowiedniego oprogramowania na komputerach (serwerach) udostępnionych przez zewnętrzną firmę. Taka firma (np. Microsoft ze swoją chmurą Azure) ma centra danych (data center) w różnych miejscach na świecie. Komputery te są ze sobą powiązane odpowiednimi sieciami i zabezpieczeniami. Szczegóły technologiczne na ten moment sobie darujmy (prawda jest taka, że to na tyle złożone tematy, że… z poszczególnych chmur (np. Azure czy AWS) robi się powszechnie uznawane certyfikaty – sam zresztą nawet jednym dysponuję;-)). Za chwilę odrobinę dokładniej opowiemy sobie jakie mamy dostępne możliwości wykorzystując chmurę. Teraz jednak to co trzeba zrozumieć, to że rezygnujemy z ręcznej obsługi zasobów. Oddajemy całość administracyjną fachowcom z konkretnej firmy. Gdy korzystamy z takich usług, nie wiemy na jakim dokładnie komputerze (komputerach, bardzo wielu) lądują nasze dane. Tak więc sporo „zabawy” nam odchodzi. Oczywiście coś za coś, natomiast o plusach i minusach porozmawiamy za chwilę.
Teraz wypadałoby podpowiedzieć jakie dokładnie są różnice. A jest ich dużo. Od przewidywalności, przez koszty (kilka ich rodzajów), kwestie prywatności danych, łatwość skalowalności aż po terytorialność danych. W tym miejscu chciałbym odnieść do moich dwóch artykułów:
W tym artykule daję takie proste zestawienie różnych aspektów. Zajmie Ci to chwilkę, a będzie bardzo dobrym punktem startowym.
Drugi artykuł jest dla ambitnych. Poruszam tam kwestie, które zazwyczaj nie są poruszane. Jest to pogłębiona analiza zagadnienia “Cloud vs On-prem”.
Jak zacząć budowę zespołu z kompetencjami Big Data?
Oto najważniejsze być może pytanie. Napiszę na ten temat osobny artykuł. Tutaj zerknijmy jednak skrótowo na temat, który jest niezwykle istotny, a wręcz powiedzmy sobie – kluczowy. Moment zainwestowania w kompetencje może być wybrany lepiej lub gorzej, ale źle zbudowany zespół będzie się mścić przez lata. Oznacza źle zaprojektowane systemy, źle napisany kod, a to – w efekcie – projekty, które po latach trzeba będzie wyrzucić do śmieci lub napisać od początku. A można uniknąć tego wszystkiego robiąc cały proces tak, aby miał ręce i nogi;-).
Znów – nie chcę rościć sobie praw do wyznaczania jedynie słusznej ścieżki rozwoju. Zaproponuję jednak kilka punktów, które mogą nakierować myślenie na metodyczne podejście, które w perspektywie się opłaci.
Po pierwsze – przygotujmy się
Nie róbmy wszystkiego na łapu capu. Trzeba mieś pewną wiedzę, która zaczyna się w kadrze menedżerskiej. Bez tego będziemy przepalać pieniądze. Niech menedżerowie nie oddzielają się grubym murem od technicznych. Zdobycie podstawowych informacji nie będzie techniką rakietową, a pozwoli podejmować lepsze decyzje.
W jaką wiedzę się uzbroić? (przykład)
Zbudowanie zespołu kosztuje. To podstawa, z którą warto się oswoić. Inżynierowie Big Data są drogimi specjalistami, szkolenie i doradztwo jest drogie. Prawdopodobnie cały proces nie zamknie się w kilkudziesięciu tysiącach złotych, choć kosztorys to zawsze bardzo indywidualna sprawa.
Jakie są dokładnie powody budowy zespołu z kompetencjami Big Data? To bardzo istotne, bo będzie wymuszało różny start, datę, technologie itd. Omawialiśmy to trochę wyżej.
Kiedy Chcemy wystartować?
Na jakim zespole bazujemy? Czy na jakimkolwiek?
Jakie są generalne technologie Big Data? Nie chodzi o szczegóły, ale o ogólne rozeznanie się w tym co istnieje na rynku.
Jaki jest nasz dokładny plan działania? Taka road-mapa powinna być przedyskutowana z początkowym zespołem, aby ludzie Ci mieli świadomość w którym kierunku idą.
Czy potrzebujemy infrastruktury? Być może nie, ale prawdopodobnie jednak na czymś trzeba będzie bazować.
Po drugie – wyznaczmy zespół
Zespół może być tworzony od zera, może być zrekrutowany. Bardzo prawdopodobne, że uda się zrobić opcję hybrydową, czyli wyszkolić kilku specjalistów do początkowego etapu, a zrekrutować seniora, który tym pokieruje.
Jeśli bazujemy na ludziach którzy już pracują w firmie, warto patrzeć na ludzi z doświadczeniem w Javie oraz bazach danych. Oczywiście podstawą jest doświadczenie z systemami Linuxowymi, oraza z gitem.
Po trzecie – przeszkólmy zespół
Jeśli mamy już zespół, warto go przeszkolić. Szczególnie tą część, która jest “świeża”. Należy dokładnie zastanowić się nad technologiami z jakimi chcemy ruszyć, jakie bedą potrzebne na początku. W ustaleniu dokładnego planu działania pomoże specjalna firma – tu polecam nas, RDF;-). Zapraszam pod ten link, gdzie można zapoznać się z ofertą szkoleń.
W tym miejscu dodam jeszcze jedno. Szkolenia można przeprowadzać doraźne i intensywne. Na przykład kilka dni bardzo mocnego treningu z Apache Spark. Jest jednak dostępna także inna możliwość, która tutaj sprawdzi się znacznie bardziej. To bardzo obszerne, długie szkolenia, które wyposażają kursantów w umiejętności z podstaw Big Data. Takie szkolenie może trwać nawet 2, 3 miesiące. Warto rozważyć;-).
Po czwarte – niech zespół zdobędzie pierwsze rany w walce
Kiedy mamy już cały zespół, warto zrobić pierwszy projekt. Jeszcze nie dla klienta. Najlepiej, żeby projekt ten miał swój konkretny cel, który przysłuży się firmie, będzie projektem Open Source lub choćby “wizytówką”. Niestety, nie wszystko wyjdzie w czasie szkoleń – nawet naszych;-) (mimo, że w ramach tego długiego szkolenia sporo czasu zajmuje mini-projekt właśnie). Wiele rzeczy musi zostać wypalonych w projektowym ogniu. Od stricte technicznych, przez organizacyjne, po kontakcie wewnątrz zespołu.
Po takim projekcie… cóż, sami najlepiej będziecie wiedzieć, czy zespół jest gotowy do działania. Być może potrzebne będą kolejne kroki, a być może wstępne doświadczenie będzie już wystarczająco solidne:-)
Podsumowanie
Uff, to był naprawdę długi artykuł. Cieszę się, że docieramy do końca razem! Jestem przekonany, że masz teraz już podstawową wiedzę na temat Big Data, w kontekście biznesowym. Oczywiście tak naprawdę zaledwie musnęliśmy temat. Jest to jednak już dobry start do dalszej pracy.
Jeśli potrzebujesz naszych usług, polecam z czystym sumieniem. Nasze szkolenia są tworzone z myślą, że mają być możliwie podobne do prawdziwego życia. My sami jesteśmy żywymi pasjonatami naszej branży. Bardzo chętnie Ci pomożemy – czy to w temacie nauki czy konsultacji. Nie bój się napisać!
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Będzie nam bardzo miło Cię gościć;-).
WAŻNA INFORMACJA! Jestem w trakcie pisania ebooka. Będzie w tematyce takiej jak ten artykuł, jednak bardziej “na spokojnie” oraz dogłębniej. Co więcej – będzie za darmo dostępeny! Dla każdego? NIE. Jedynie dla zapisanych na newsletter. Zapisz się już dzisiaj i zyskaj wpływ na proces twórczy;-)

")