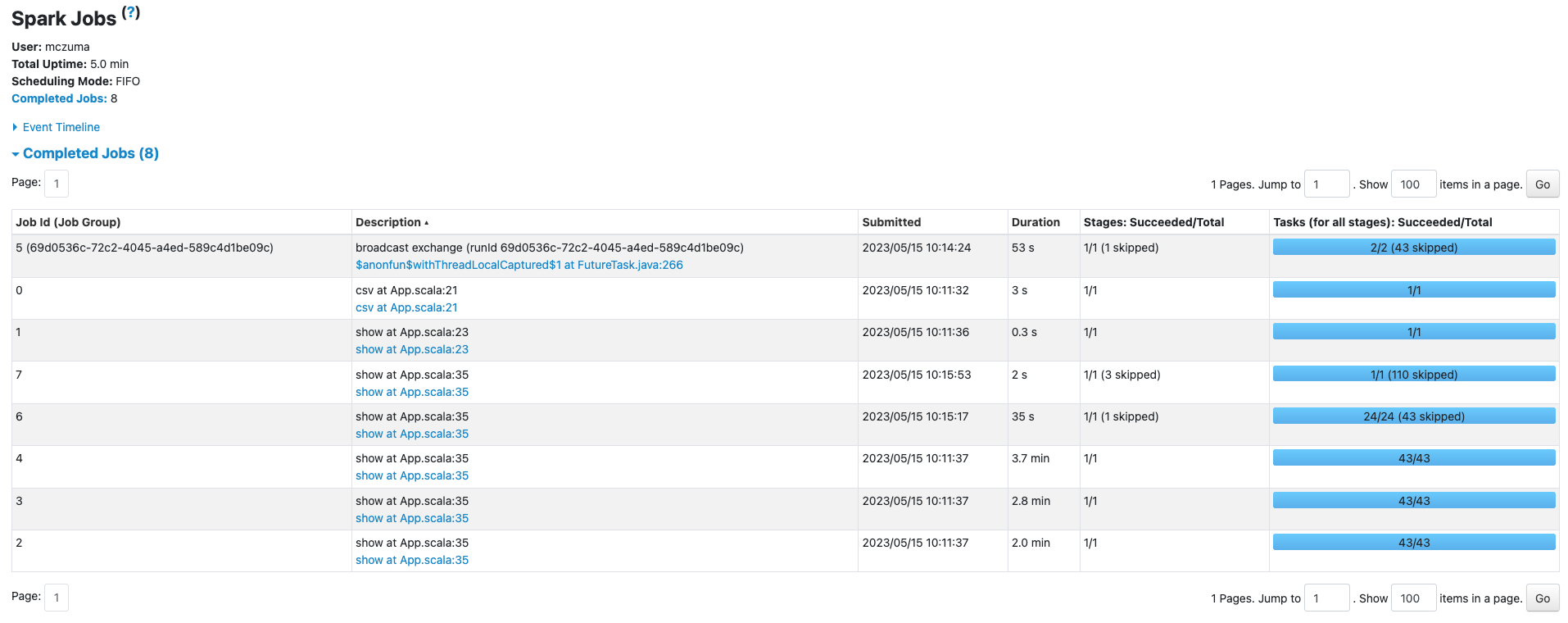
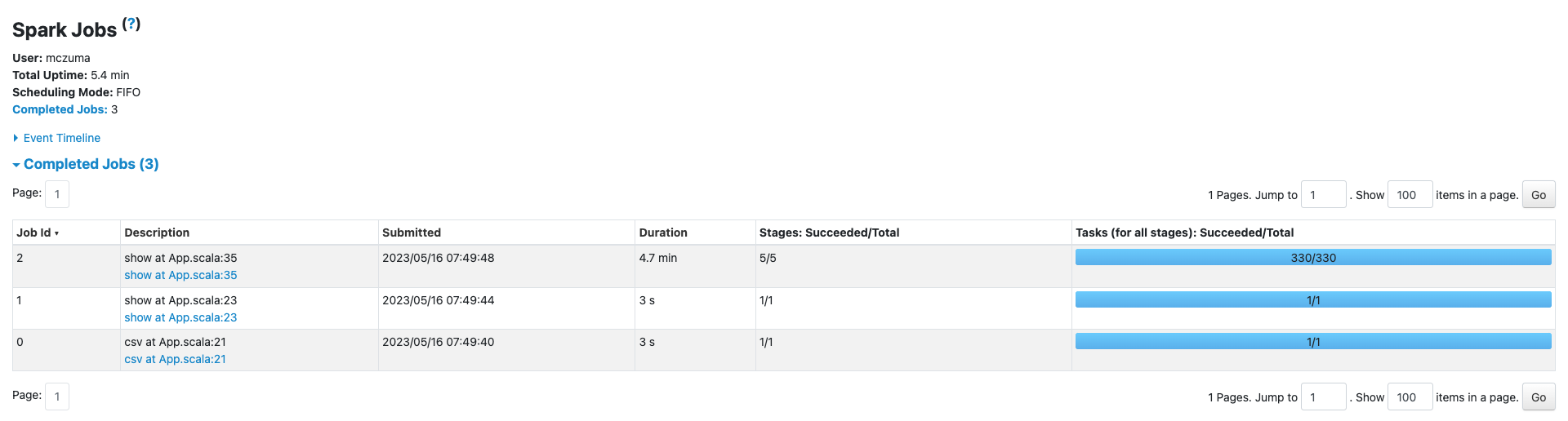
W tym artykule cofniemy się do zeszłego roku (2022). Wyjaśnię, jak znalazłem rozwiązanie na wybranie odpowiedniej technologii i z jakimi przeszkodami się zmagałem szukając “furtki” do świata Big Data;-).
Zanim usłyszałem o Big Data
Początek roku był mglisty ze względu na to, że miałem kilka podejść do różnych technologii. Już wcześniej zdobyłem podstawowe umiejętności programowania obiektowego w Pythonie. Znałem również podstawy webdevu oraz relacyjnych i nierelacyjnych baz danych. W pracy używałem zarówno Pythona, jak i Javy do realizowania testów automatycznych, które pisałem i dokumentowałem (pozdro shared service). Ciągnęło mnie do wszystkiego, co się świeciło, w związku z czym zacząłem nawet czytać o Ruscie, myśląc o tym żeby zrealizować w nim pracę inżynierską (na szczęście odrzuciłem ten pomysł odpowiednio wcześnie).
Na przełomie drugiego kwartału dostałem zaproszenie do zaangażowania się w projekcie Javowym, ale ta technologia mnie przerosła – brak rzeczywistego doświadczenia w webdevie oraz poziom skomplikowania aplikacji z pewnością odegrał tu swoją rolę.
Mijał czas, a ja wciąż nie wiedziałem w którą stronę się rozwijać. Byłem niesamowicie sfrustrowany – i słusznie. Wpadłem na pomysł, aby do realizowania projektów wykorzystać równie pragnących (jak wtedy myślałem) rozwoju znajomych. Średnio to wyszło, ale cieszę się, że mimo mojej ówczesnej natarczywości jeszcze ze mną rozmawiają. Czas nieubłaganie mijał, a obrona mojej pracy inżynierskiej zbliżała się wielkimi krokami, więc postanowiłem działać. Z wykorzystaniem Flaska oraz Selenium stworzyłem WATS, czyli Web Automation Testing Simplified. Aplikację, która potwierdziła naszą tezę, mówiącą o tym, że testy automatyczne tworzy się dość łatwo i może to robić osoba niekoniecznie techniczna. I co najlepsze, działa i wygląda!
Dane, machine learning i… kolejne frustracje
Gdy napisałem aplikację do pracy inżynierskiej, poczułem że Python nie jest wcale takim prostym narzędziem (to złudne przeświadczenie narosło we mnie, kiedy próbowałem nauki języków kompilowanych). Aby zgłębić bardziej ten język postanowiłem zainteresować się uczeniem maszynowym. Nie rozumiałem matematyki idącej za algorytmami uczenia maszynowego, ale samo sprzątanie danych i robienie z nich rzeczywistego użytku w postaci wykresów zrobiło na mnie ogromne wrażenie. Postanowiłem bardziej się w to zagłębić. Spojrzałem ile zarabiają MLOpsi. Chciałem tyle samo. Zacząłem cisnąć temat. Zrobiłem certyfikaty Azure, aby zapoznać się bardziej z tematem chmur, danych oraz AI (były za darmo kiedy się uczęszczało na Virtual Training Day, kiedyś to było…). Jednak stanąłem przed ścianą, której nie mogłem pokonać.
Brak wiary w swoje możliwości, który wynikał z niezrozumienia algebry, nasilił się jeszcze bardziej wraz z realizowaniem zaawansowanych technik wytwarzania modeli uczenia maszynowego. Chciałem wejść w temat, jednak nie mogłem. Byłem na siebie zły z powodu wyboru uczelni, ponieważ nie poszedłem na Informatykę na studia dzienne. Postanowiłem, że powinienem obrać inną ścieżkę.
Zdając sobie sprawę że nie zostanę Data Scientistem, postanowiłem się uczyć metodologii DevOpsu. Jenkins, Docker, K8s, Ansible. Szło naprawdę dobrze, nawet ogarnąłem ładnie Jenkinsa oraz Dockera, ale odczułem, że pociąg już odjechał, a bez Kubernetesa nie ma co podchodzić do rekrutacji na juniora. Nie miałem też nikogo, kto mógłby mnie wyprowadzić z tego błędu.
Big Data – pierwsze spojrzenie
Znajomy raz podrzucił mi pomysł Data Engineeringu. Olałem to, bo pomyślałem że nic w tym ciekawego. Sprzątać dane, żeby inni mogli robić to, co jest najbardziej interesujące? To było w momencie, kiedy wypalałem się tematem ML, ale jeszcze nie upadłem przed ścianą.
Był późny grudzień, a ja nie miałem żadnych postanowień noworocznych. Na LinkedIn pojawił mi się artykuł Marka, który ogłaszał zapisy na szkolenie Fundament Sparka. Podczas nauki Data Science widziałem jakieś sugestie o Sparku, że ma bibliotekę do ML, do konkretnego Data Engineeringu oraz do analizy danych w zbiorach oraz streamowanych i że można go postawić na tanich kompach. Podobało mi się, że to narzędzie jest tak potężne, a na dodatek moja dotychczasowa edukacja pozwalała mi na łatwe wejście w temat. Postanowiłem, że zapiszę się na kurs. W końcu najlepsza inwestycja to ta w siebie. Nie myliłem się.
Po przerobieniu kursu zaintrygowany możliwościami Sparka, pythonową zwinnością i javową elegancją Scali w połączeniu z nowym dla mnie programowaniem funkcyjnym, podjąłem decyzję o dalszym rozwoju w stronę Data Engineeringu. Postanowiłem przerwać pasmo niepowodzeń i plątania się po technologiach.
Big Data – “all in”!
Ukończywszy kurs, Marek zaproponował mi udział w programie mentoringowym. Zależało mi na zmianie pracy, spróbowałem. Szeregowaliśmy wiedzę, siedzieliśmy na spotkaniach i podejmowaliśmy po kolei tematy, metodycznie. Jednocześnie, ciągle wysyłałem CV. Miesiąc po zakończeniu kursu dostałem propozycję pracy przy Sparku jako Big Data Support Engineer.
Uważam to za sukces mój, jak i Marka, bo bez uszeregowanej wiedzy przekazanej w dobry sposób i przygotowania pod względem technicznym do wykonywania tej pracy prawdopodobnie nie byłoby tak łatwo. Albo co gorsza, znowu bym się pogubił.
Dlatego, z pełnym przekonaniem, jeżeli się zastanawiasz czy mentoring to dobry pomysł, to uwierz mi, że jest. Nieważne na jakim poziomie zaawansowania, warto mieć opatrzność drugiej osoby, zwłaszcza z doświadczeniem.
Aktualnie, wraz z drugim uczestnikiem programu mentoringowego realizujemy projekt wykorzystujący realne dane (które sami pozyskujemy i przechowujemy :)) w środowisku okołoprodukcyjnym. Wykorzystujemy techniki, sposoby wytwarzania oprogramowania oraz standardy projektowe takie, jakie znajdziesz w realnym produkcyjnym środowisku. Oczywiście, głównym fundamentem jest Scala oraz Spark.
Pracuję również nad swoim blogiem technologicznym, w którym będę opisywać napotykane problemy, obserwacje oraz wnioski i mam nadzieję, że skończę to w niedalekiej przyszłości. 🙂
Zwieńczając to wszystko, bardzo się cieszę, że postawiłem na Fundament Sparka i Program Mentoringowy RDF – mocny kickstart dla kariery w danych.
A teraz czas na “Słowo od Mentora” 😉
Rafał od samego początku wykazywał OGROMNY zapał, był niezwykle pracowity i metodyczny. Bez tego nawet oferta podana na tacy nic by nie zdziałała;-).
Gratuluję! I… jestem dumny:-).
UWAGA! Jeśli Ciebie również interesuje mentoring…
Po prostu napisz na marek.czuma@riotechdatafactory.com.
Ułożymy razem plan i ruszymy z działaniem.
Akurat pojawiło się kilka wolnych miejsc, więc nie czekaj;-)
W poniższym wideo mówię ciut więcej na temat mentoringu. Jeśli masz pytania – po prostu do mnie napisz.
Pamiętaj! Zawsze jesteś mile widziany/a