Machine Learning w Sparku? Jak najbardziej! W poprzednim artykule pokazałem efekty prostego mechanizmu do porównywania tekstów, który zbudowałem. Całość jest zrobiona w Apache Spark, co niektórych może dziwić. Dzisiaj chcę się podzielić tym jak dokładnie zbudować taki mechanizm. Kubki w dłoń i lecimy zanurzyć się w kodzie!
Założenia
Jeśli chodzi o założenia, które dotyczą Ciebie – zakładam że umiesz tu Scalę oraz Sparka. Oba w stopniu podstawowym;-). W kontekście sparka polecam mój cykl “zrozumieć Sparka” czy generalnie wszystkie wpisy dotyczące tej technologii.
Jeśli chodzi o założenia naszego “projektu” – to są one dość proste:
- Bazujemy na zbiorze, który ma ~204 tysiące krótkich tekstów – konkretnie tweetów.
- Tweety dotyczą trzech dziedzin tematycznych:
- COVID – znakomita większość (166543 – 81,7%)
- Finanse – pewna część (28874 – 14,1%)
- Grammy’s – margines (8490 – 4,2%)
- W ramach systemu przekazujemy tekst od użytkownika. W odpowiedzi dostajemy 5 najbardziej podobnych tweetów.
Pobieranie datasetów (wszystkie dostępne na portalu Kaggle): covid19_tweets, financial, GRAMMYs_tweets
Powiem jeszcze, że tutaj pokazuję jak zrobić to w prostej, batchowej wersji. Po prostu uruchomimy cały job sparkowy wraz z tekstem i dostaniemy odpowiedzi. W innym artykule jednak pokażę jak zrobić także joba streamingowego. Dzięki temu stworzymy mechanizm, który będzie nasłuchiwał i naprawdę szybko będzie zwracał wyniki w czasie rzeczywistym (mniej więcej, w zależności od zasobów – czas ocekiwania to kilka, kilkanaście sekund). Jeśli chcesz dowiedzieć się jak to zrobić – nie zapomnij zasubskrybować bloga RDF!
Spark MlLib
Zacznijmy od pewnej rzeczy, żeby nam się nie pomyliło. Spark posiada bibliotekę, która służy do pracy z machine learning. Nazywa się Spark MlLib. Problem polega na tym, że wewnątrz rozdziela się na dwie pod-biblioteki (w scali/javie są to po prostu dwa pakiety):
- Spark MlLib – metody, które pozwalają na prace operując bezpośrednio na RDD. Starsza część, jednak nadal wspierana.
- Spark Ml – metody, dzięki którym pracujemy na Datasetach/Dataframach. Jest to zdecydowanie nowocześniejszy kawałek biblioteki i to z niego właśnie korzystam.
Spark MlLib możemy pobrać z głównego repozytorium mavena tutaj.
Dodawanie dependencji jeśli korzystamy z Mavena (plik pom.xml):
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>3.0.0</version>
<scope>provided</scope>
</dependency>
Oczywiście scope “provided” podajemy tylko w przypadku wysyłania później na klaster. Jeśli chcemy eksperymentować lokalnie, nie dodajemy go.
Dodawanie dependencji jeśli korystamy z SBT (plik build.sbt):
libraryDependencies += "org.apache.spark" %% "spark-mllib" % "3.0.0" % "provided"
Ta sama uwaga odnośnie “provided” co w przypadku mavena.
Spark NLP od John Snow Labs
Chociaż Spark posiada ten znakomity moduł SparkMlLib, to niestety brak w nim wielu algorytmów. Zawierają się w tych brakach nasze potrzeby. Na szczęście, luka została wypełniona przez niezależnych twórców. Jednym z takich ośrodków jest John Snow Labs (można znaleźć tutaj). Samą bibliotekę do przetwarzania tekstu, czyli Spark-NLP zaciągniemy bez problemu z głównego repozytorium Mavena
Dodawanie dependencji, jeśli korzystamy z Mavena (plik pom.xml):
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>3.3.4</version>
<scope>test</scope>
</dependency>
Dodawanie dependencji jeśli korystamy z SBT (plik build.sbt):
libraryDependencies += "com.johnsnowlabs.nlp" %% "spark-nlp" % "3.3.4" % Test
Dane
Dane same w sobie pochodzą z 3 różnych źródeł. I jak to bywa w takich sytuacjach – są po prostu inne, pomimo że teoretycznie dotyczą tego samego (tweetów). W związku z tym musimy zrobić to, co zwykle robi się w ramach ETLów: sprowadzić do wspólnej postaci, a następnie połączyć.
Dane zapisane są w plikach CSV. Ponieważ do porównywania będziemy używać tylko teksty, z każdego zostawiamy tą samą kolumnę – text. Poza tą jedną kolumną dorzucimy jednak jeszcze jedną. To kolumna “category”, która będzie zawierać jedną z trzech klas (“covid”, “finance”, “grammys”). Nie będą to oczywiście klasy służące do uczenia, natomiast dzięki nim będziemy mogli sprawdzić potem na ile dobrze nasze wyszukiwania się “wstrzeliły” w oczekiwane grupy tematyczne. Na koniec, gdy już mamy identyczne struktury danych, możemy je połączyć zwykłą funkcją “union”.
Całość upakowałem w metodę zwracającą Dataframe:
def prepareTwitterData(sparkSession: SparkSession): Dataset[Row] ={
val covidDF: Dataset[Row] = sparkSession.read
.option("header", "true")
.csv("covid19_tweets.csv")
.select("text")
.withColumn("category", lit("covid"))
.na.drop()
val financialDF: Dataset[Row] = sparkSession.read
.option("header", "true")
.csv("financial.csv")
.select("text")
.withColumn("category", lit("finance"))
.na.drop()
val grammysDF: Dataset[Row] = sparkSession.read
.option("header", "true")
.csv("GRAMMYs_tweets.csv")
.select("text")
.withColumn("category", lit("grammys"))
.na.drop()
covidDF.union(financialDF)
.union(grammysDF)
}
Przygotowanie tekstu do treningu
Gdy pracujemy z NLP, bazujemy oczywiście na tekście. Niestety, komputer nie rozumie tekstu. A co rozumie komputer? No jasne, liczby. Musimy więc sprowadzić tekst do poziomu liczb. Konkretnie wektorów, a jeszcze konkretniej – embeddingów. Embeddingi to nisko-wymiarowe reprezentacje czegoś wysoko-wymiarowego. W naszym przypadku będzie to tekst. Czym dokładnie są embeddingi, dobrze wyjaśnione jest na tej stronie. Na nasze, uproszczone potrzeby musimy jednak wiedzieć jedno: embeddingi pozwalają zachować kontekst. Oznacza to w dużym skrócie, że słowo “pizza” będzie bliżej słowa “spaghetti” niż słowa “sedan”.
Sprowadzanie do postaci liczbowej może się odbyć jednak dopiero wtedy, gdy odpowiednio przygotujemy tekst. Bardzo często w skład takiego przygotowania wchodzi oczyszczenie ze “śmieciowych znaków” (np. @, !, ” itd) oraz tzw. “stop words”, czyli wyrazów, które są spotykane na tyle często i wszędzie, że nie opłaca się ich rozpatrywać (np. I, and, be). Oczywiście może to rodzić różne problemy – np. jeśli okroimy frazy ze standardowych “stop words”, wyszukanie “To be or not to be” będzie… puste. To jednak już problem na inny czas;-).
Do przygotowania często wprowadza się także tokenizację, czyli podzielenie tekstu na tokeny. Bardzo często to po prostu wyciągnięcie wyrazów do osobnej listy, aby nie pracować na stringu, a na kolekcji wyrazów (stringów). Spotkamy tu także lemmatyzację, stemming (obie techniki dotyczą sprowadzenia różnych słów do odpowiedniej postaci, aby móc je porównywać).
W naszym przypadku jednak nie trzeba będzie robić tego wszystkiego. Jedyne co musimy, to załączyć DocumentAssembler. Jest to klasa, która przygotowuje dane do formatu zjadliwego przez Spark NLP.
Po zastosowaniu dostajemy kolumnę, która ma następującą strukturę:
root |-- document: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- annotatorType: string (nullable = true) | | |-- begin: integer (nullable = false) | | |-- end: integer (nullable = false) | | |-- result: string (nullable = true) | | |-- metadata: map (nullable = true) | | | |-- key: string | | | |-- value: string (valueContainsNull = true) | | |-- embeddings: array (nullable = true) | | | |-- element: float (containsNull = false)
W naszym kodzie najpierw inicjalizujemy DocumentAssembler, wykorzystamy go nieco później. Przy inicjalizacji podajemy kolumnę wejściową oraz nazwę kolumny wyjściowej:
val docAssembler: DocumentAssembler = new DocumentAssembler().setInputCol("text")
.setOutputCol("document")
Zastosowanie USE oraz budowa Pipeline
Jak już napisałem, my wykorzystamy Universal Sentence Encoder (USE). Dzięki tym embeddingom całe frazy (tweety) będą mogły nabrać konktekstu. Niestety, sam “surowy” Spark MlLib nie zapewnia tego algorytmu. Musimy tu zatem sięgnąć po wspomniany już wcześniej Spark NLP od John Snow Labs (podobnie jak przy DocumentAssembler). Zainicjalizujmy najpierw sam USE.
val use: UniversalSentenceEncoder = UniversalSentenceEncoder.pretrained()
.setInputCols("document")
.setOutputCol("sentenceEmbeddings")
Skoro mamy już obiekty dosAssembler oraz use, możemy utworzyć pipeline. Pipeline w Spark MlLib to zestaw powtarzających się kroków, które możemy razem “spiąć” w całość, a następnie wytrenować, używać. Wyjście jednego kroku jest wejściem kolejnego. Wytrenowany pipeline (funkcja fit) udostępnia nam model, który możemy zapisać, wczytać i korzystać z niego.
Nasz pipeline będzie bardzo prosty:
val pipeline: Pipeline = new Pipeline().setStages(Array(docAssembler, use)) val fitPipeline: PipelineModel = pipeline.fit(tweetsDF)
Gdy dysponujemy już wytrenowanym modelem, możemy przetworzyć nasze dane (funkcja transform). Po tym kroku otrzymamy gotowe do użycia wektory. Niestety, USE zagnieżdża je w swojej strukturze – musimy więc je sobie wyciągnąć. Oba kroki przedstawiam poniżej:
val vectorizedTweetsDF: Dataset[Row] = fitPipeline.transform(tweetsDF)
.withColumn("sentenceEmbeddings", org.apache.spark.sql.functions.explode(col("sentenceEmbeddings.embeddings")))
Znakomicie! Mamy już tweety w formie wektorów. Teraz należy jeszcze zwektoryzować tekst użytkownika. Tekst będzie przechowywany w Dataframe z jednym wierszem (właśnie owym tekstem) w zmiennej sampleTextDF. Po wektoryzacji usunę zbędne kolumny i zmienię nazwy tak, aby było wiadomo, że te wektory dotyczą tekstu użytkownika, a nie tweetów (przyda się później, gdy będziemy łączyć ze sobą oba Dataframy).
val vectorizedUserTextDF: Dataset[Row] = fitPipeline.transform(sampleTextDF)
.drop("document")
.withColumn("userEmbeddings", org.apache.spark.sql.functions.explode(col("sentenceEmbeddings.embeddings")))
.drop("sentenceEmbeddings")
Implementacja cosine similarity
Uff – sporo roboty za nami, gratuluję! Mamy już tweety oraz tekst użytkownika w formie wektorów. Czas zatem porównać, aby znaleźć te najbardziej podobne! Tylko pytanie, jak to najlepiej zrobić? Muszę przyznać że trochę czasu zajęło mi szukanie algorytmów, które mogą w tym pomóc. Finalnie wybór padł na cosine similarity. Co ważne – nie jest to żaden super-hiper-ekstra algorytm NLP. To zwykły wzór matematyczny, znany od dawna, który porównuje dwa wektory. Tak – dwa najzwyklejsze, matematyczne wektory. Jego wynik zawiera się między -1 a 1. -1 to skrajnie różne, 1 to identyczne. Nas zatem będą interesować wyniki możliwie blisko 1.
Problem? A no jest. Spark ani scala czy java nie mają zaimplementowanego CS. Tu pokornie powiem, że być może po prostu do tego nie dotarłem. Jeśli znasz gotową bibliotekę do zaimportowania – daj znać w komentarzu! Nie jest to jednak problem prawdziwy, bowiem możemy rozwiązać go raz dwa. Samodzielnie zaimplementujemy cosine similarity w sparku, dzięki UDFom (User Defined Function).
Najpierw zacznijmy od wzoru matematycznego:

Następnie utwórzmy klasę CosineSimilarityUDF, która przyjmuje dwa WrappedArrays (dwa wektory), natomiast zwraca zwykłą liczbę zmiennoprzecinkową Double. Wewnątrz konwertuję tablice na wektory, wykorzystuję własną metodę magnitude i zwracam odległość jednego wektora od drugiego.
Klasa CosineSimilarityUDF
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.sql.api.java.UDF2
import scala.collection.mutable
class CosinSimilarityUDF extends UDF2[mutable.WrappedArray[Float], mutable.WrappedArray[Float], Double]{
override def call(arr1: mutable.WrappedArray[Float], arr2: mutable.WrappedArray[Float]): Double = {
val vec1 = Vectors.dense(arr1.map(_.toDouble).toArray)
val vec2 = Vectors.dense(arr2.map(_.toDouble).toArray)
val mgnt1 = magnitude(vec1)
val mgnt2 = magnitude(vec2)
vec1.dot(vec2)/(mgnt1*mgnt2)
}
def magnitude(vector: Vector): Double={
val values = vector.toArray
Math.sqrt(values.map(i=>i*i).sum)
}
}
Wykorzystanie Cosine Similarity – sprawdzamy podobieństwo tekstów!
Znakomicie – po utworzeniu tego UDFa, możemy śmiało wykorzystać go do obliczenia podobieństw między każdym z tweetów a tekstem użytkownika. Aby to uczynić, najpierw rejestrujemy naszego UDFa. Polecam to co zawsze polecam na szkoleniach ze Sparka – zrobić to zaraz po inicjalizacji SparkSession. Dzięki temu utrzymamy porządek i nie będziemy się martwić, jeśli w przyszłości w projekcie ktoś będzie również chciał użyć UDFa w nieznanym obecnie miejscu (inaczej może dojść do próby użycia UDFa zanim zostanie zarejestrowany).
val cosinSimilarityUDF: CosinSimilarityUDF = new CosinSimilarityUDF()
sparkSession.udf.register("cosinSimilarityUDF", cosinSimilarityUDF, DataTypes.DoubleType)
Wróćmy jednak na sam koniec, do punktu w którym mamy już zwektoryzowane wszystkie teksty. Najpierw sprawimy, że każdy tweet będzie miał dołączony do siebie tekst użytkownika. W tym celu zastosujemy crossjoin (artykuł o sposobach joinów w Sparku znajdziesz tutaj). Następnie użyjemy funkcji withColumn, dzięki której utworzymy nową kolumnę – właśnie z odległością. Wykorzystamy do jej obliczenia oczywiście zarejestrowany wcześniej UDF.
val dataWithUsersPhraseDF: Dataset[Row] = vectorizedTweetsDF.crossJoin(vectorizedUserTextDF)
val afterCosineSimilarityDF: Dataset[Row] = dataWithUsersPhraseDF.withColumn("cosineSimilarity", callUDF("cosinSimilarityUDF", col("sentenceEmbeddings"), col("userEmbeddings"))).cache()
Na sam koniec pokażemy 20 najbliższych tekstów, wraz z kategoriami. Aby uniknąć problemów z potencjalnymi “dziurami”, odfiltrowujemy rekordy, które w cosineSimilarity nie mają liczb. Następnie ustawiamy kolejność na desc, czyli malejącą. Dzięki temu dostaniemy wyniki od najbardziej podobnych do najmniej podobnych.
afterCosineSimilarityDF.filter(isnan(col("cosineSimilarity")) =!= true)
.orderBy(col("cosineSimilarity").desc)
.show(false)
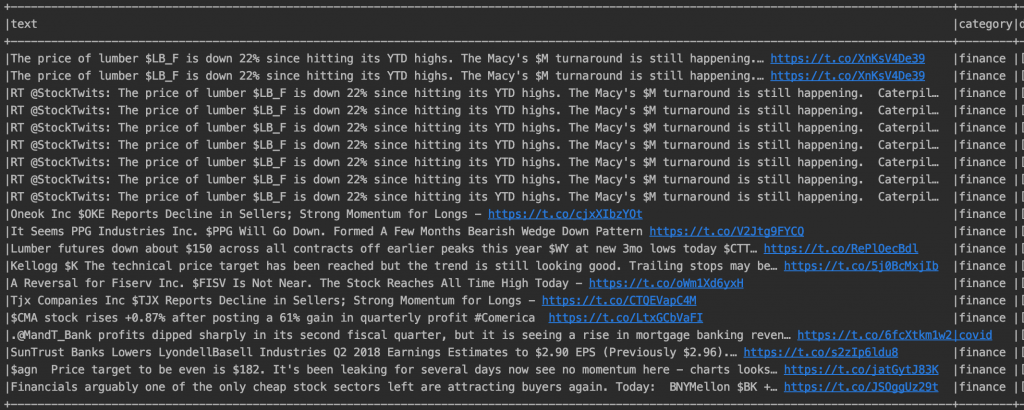
I to koniec! Wynik dla hasła “The price of lumber is down 22% since hitting its YTD highs. The Macy’s $M turnaround is still happening” można zaobserwować poniżej. Więcej wyników – przypominam – można zaobserwować w poprzednim artykule;-).
Podsumowanie
Mam nadzieję, że się podobało! Daj znać koniecznie w komentarzu i prześlij ten artykuł dalej. Z pewnością to nie koniec przygody z Machine Learning w Sparku na tym blogu. Zostań koniecznie na dłużej i razem budujmy polskie środowisko Big Data;-). Jeśli chcesz pozostać z nami w kontakcie – zapisz się na newsletter lub obserwuj RDF na LinkedIn.
Pamiętaj także, że prowadzimy szkolenia z Apache Spark. Jakie są? Przede wszystkim bardzo mięsiste i tak bardzo zbliżone do rzeczywistości jak tylko się da. Pracujemy na prawdziwych danych, prawdziwym klastrze. Co więcej – wszystko to robimy w znakomitej atmosferze, a na koniec dostajesz garść materiałów! Kliknij tutaj i podrzuć pomysł swojemu szefowi;-).