Po EKSTREMALNYM sukcesie poradnikowego wideo na temat tworzenia kolekcji w Solr (prawie 50 wyświetleń w pierwszych dniach. SZOK. Hollywood stuka puka do drzwi!), pociągnąłem temat. Ciągle poradnikowo, ciągle Solr. Tym razem jednak zaindeksujemy więcej dokumentów niż tradycyjnie robi się to w tutorialach. I zrobimy to znacznie przyjemniej, niż robi się to zwykle w tutorialach;-). Czas zaprzęgnąć Sparka do indeksacji danych w Solr!
How to index data in Solr with Apache Spark?
Poniżej wklejam wideo i zapraszam do subskrybowania kanału RDF na YouTube;-)
Iii stało się! Wreszcie przemogłem się (i znalazłem czas w szkoleniowym młynie) żeby nagrać pierwsze RDFowe wideo. Liczę że od tej pory sukcesywnie będziemy przesuwali się także i na tym polu;-). Treści wideo będą przeróżne, ale na pierwszy ogień idzie typowy poradnik “how-to”.
Inauguracje weźmie na siebie Solr, a konkretnie tworzenie kolekcji. Jest to temat zdecydowanie nieprosty, a przede wszystkim – nieintuicyjny do bólu. Szczególnie, jeśli ktoś wie jak to się robi w Elastic Search. Smacznego!
How to create solr collection?
Poniżej wklejam wideo i zapraszam do subskrybowania kanału RDF na YouTube;-)
Plany Rządu dotyczące utworzenia Megabazy danych o obywatelach spotkały się z głębokim sceptycyzmem. To dobrze. Czy nie jest to jednak krok w dobrą stronę? Co zrobić, żeby takim był? O tym w dzisiejszym artykule. Zapraszam od razu do subskrypcji oraz obserwowania na LinkedIn;-). Poprzedni materiał dotyczył cięższych tematów (wojna). Dziś więc nieco odsapniemy. Zatem kubek z naszym caffe latte w dłoń – i ruszamy!
Rządowa Megabaza – Wątpliwości
Dla tych, którzy nie wiedzą dokładnie o jaką “Megabazę” chodzi – odsyłam do artykułu w którym to wyjaśniałem. W skrócie jednak: Rząd planuje połączyć wiele z dostępnych już rejestrów gromadzących dane o obywatelach (np. GUS, dane medyczne itd.). W efekcie powstałaby Megabaza, która zawierałaby ogromną ilość danych o każdym z nas. Warto nadmienić, że – w teorii – baza ta służyłaby jedynie do dokonywania analiz, a dane byłyby pseudonimizowane.
No właśnie – w teorii. Problem polega jednak na tym, że wokół Megabazy powstało dość dużo niejasności. Od razu też zgromadziło się jeszcze więcej głosów sprzeciwu wobec powstania takiego rejestru. Chodziło o kilka kluczowych problemów:
Megabaza ma powstać na drodze zwykłego rozporządzenia. Mowa tu także o informacjach chronionych tajemnicą – lekarską czy statystyczną.
Co prawda cele mają być stricte analityczne, jednak są one określone na tyle ogólnie, że istnieje tu pole do nadużyć.
Dane w przeprowadzonych analizach mają być pseudonimizowane. To jest zaś proces odwracalny (np. szyfrowanie symetryczne z kluczem tajnym). Jeśli będę miał klucz – dojdę do tego kto, gdzie, jak i z kim.
Wojciech Klicki z Fundacji Panoptykon mówi:
“Przy tak dużym zakresie danych, dostrzegam kolosalny potencjał do nadużyć. Nie ma żadnych gwarancji, że baza ta nie zostanie wykorzystana do celów stricte politycznych, wręcz do inżynierii politycznej”
Czy taki diabeł straszny?
Postarajmy się wygasić na chwilę emocje związane ze słowem “inwigilacja”. Zastanówmy się na chłodno, czy faktycznie pomysł jest tak straszny jak mówią o nim krytycy. Swoją drogą – warto też zwrócić uwagę kim są owi krytycy. To m.in. przytaczana wyżej w cytacie Fundacja Panoptykon. Jest to organizacja aktywnie lobbująca za skrajnym ograniczaniem możliwości polskich służb specjalnych. Opowiada się za daleko idącym ograniczaniem Państwa w dostępie do jakichkolwiek informacji dotyczących obywateli. Warto więc mieć na uwadze, że nie jest to głos wyważony. Spróbujmy jednak spojrzeć na argumenty, które opowiadają się po stronie budowania tego typu systemów.
Przede wszystkim – wbrew klikbajtowym tytułom, ciężko mówić tu o “orwellu” czy o “kolejnym poziomie inwigilacji”. Nie dajemy państwu dostępu do żadnych nowych danych. Dajemy jedynie możliwość, aby dane te były w sposób wygodny i skuteczny zintegrowane. Sytuacja w której przekazujemy jakiejś organizacji różne dane i boimy się, że będzie miała do nich odpowiedni dostęp przypomina domaganie się, aby organizacja ta działała w sposób niewydolny. Jeśli zgodziliśmy sie już, że któreś z informacji o nas samych mają trafiać do państwowych rejestrów – to one już tam są. Nie starajmy się znaleźć sposobów, aby nie mogły być one użyte. Prędzej domagajmy się ograniczenia w zbieraniu (jeśli ma to sens).
Co możemy zyskać, stawiając na Big Data w administracji publicznej?
Kolejna sprawa – nieco bardziej ogólna. Gromadzenie dużych danych zgodnie z najlepszymi branżowymi przykładami może dać nam ogromne atuty. W tym konkretnym przypadku mówimy o możliwościach analitycznych. Jednym z przykładów (choć w nieco innej dziedzinie) może być wykrywanie podejrzanych firm, które warto skontrolować. Nie tylko pozwoliłoby to zawczasu zlokalizować oszustów. Być może znacznie ważniejszą zaletą byłoby to, że bardzo mocno ograniczylibyśmy liczbę kontroli w firmach, które są uczciwe.
Inny przykład opisywałem w tym artykule. Przy odpowiednich danych będziemy w stanie bardzo dokładnie obliczać inflację. Nie tylko ogólnokrajową. Także regionalną, a nawet… osobistą, dla każdego.z osobna. To byłby ruch, który dałby niewyobrażalne wcześniej możliwości kształtowania polityki gospodarczej rządu. Czasy mamy takie, że wszystko zmienia się w tempie błyskawicy. Nie możemy nie myśleć o stworzeniu narzędzi reagowania na te zmiany. Narzędzia te muszą dysponować (bardzo dużymi) danymi i opierać się na nich.
Stawiając na Big Data możemy znacznie lepiej zrozumieć społeczeństwo. Możemy usprawnić naszą administrację – tyczy się to także szeroko pojętej “cyfryzacji”. Wszyscy widzimy to na przykładzie e-recept. Pamiętajmy, że cyfryzacja musi wiązać się z gromadzeniem tych danych, a następnie zarządzaniem nimi. Albo będziemy uciekać od tego, albo możemy zabrać się do sprawy “na serio”.
Budowanie kompetencji Big Data w administracji może przynieść także gigantyczne przewagi w obszarze służb specjalnych – wywiadowczych i kontrwywiadowczych. Widzimy za naszą wschodnią granicą jak tego typu możliwości sprawdzają się w przypadku wojny. Nas szczególnie powinny tego typu tematy interesować. Nie możemy chować głowy w piasek i zachowywać się, jakbyśmy byli Szwajcarią czy Niderlandami.
Czy naprawdę jest tak kolorowo?
Powyżej przytoczyłem kilka słów wsparcia wobec tego typu projektów. Niestety, trzeba też jasno powiedzieć, że wiążą się one z wieloma wątpliwościami. Są to między innymi właśnie wymienione powyżej nadużycia ze strony władz. Te niejednokrotnie pokazały, że służby specjalne mogą być wykorzystywane bardzo instrumentalnie, w interesie partyjnym. I to niezależnie od barw partyjnych.
Aby zmniejszyć tego typu spekulacje i obawy, władza powinna zacząć kierować się najwyższymi standardami i możliwie wysoką przejrzystością. Tam gdzie to możliwe – trzeba wskazać jak dokładnie odbywać się będzie zbieranie i analiza danych. Tam, gdzie tego typu operacje powinny pozostać za kurtyną, warto wyjaśnić obywatelom dlaczego konkretnie tak powinno być.
Z całą pewnością za takimi zmianami musi iść najlepsza możliwa komunikacja. Nie propaganda, ale zrozumiała komunikacja, po brzegi wypełniona szacunkiem do obywatela i jego inteligencji oraz potrzeby prywatności. Niestety, dzisiaj bardzo często jest dokładnie odwrotnie. Na potrzeby zbudowania nowoczesnej, opartej o dane administracji, warto rozmawiać i edukować także opozycję, zapraszać ekspertów. To musi wyjść poza nasze plemienne walki.
Inną sprawą jest bezpieczeństwo. Dane zgromadzone w jednym miejscu łatwiej jest wykraść. Oczywiście skorumpowany i zepsuty agent kontrwywiadu dojdzie do dowolnych danych niezależnie od tego gdzie są przechowywane. Warto jednak – idąc w stronę cyfryzacji i “ubigdatowienia” naszej administracji – położyć nacisk na trzymanie się najwyższych standardów bezpieczeństwa i zdobycie najlepszych fachowców. Lub współprace z nimi. Pamiętajmy, że drogą do lepszej administracji może (i moim zdaniem powinna) być współpraca z sektorem prywatnym.
Podsumowanie – rachunek zysków i strat
Słowem kończącym chciałbym powiedzieć o jednej rzeczy. Żyjemy w epoce, która jest naznaczona przez dwie rzeczy: dane oraz brak prywatności. Nie możemy od tego uciekać. Możemy co najwyżej wykorzystać to gdzie jesteśmy do zbudowania swojej przewagi.
Czy lepiej jest, gdy zachowujemy prywatność? Oczywiście. A czy lepiej jest mieć państwo, które jest w stanie sprawnie reagować na zmieniające się warunki i które zapewnia nam wysoką jakość usług? Także oczywiście.
Nie musimy wybierać. Możemy szukać rozwiązania, które jest “pomiędzy”. Z góry decydując się, że spora część naszej prywatności ucieknie. Bez hipokryzji przyznając także, że sami oddajemy ją w ręce wielkich korporacji. Kiedy umówimy się, że częściowo oddamy ją także w ręce państwa – oczekując w zamian efektów – możemy wyjść przed peleton. Jesteśmy w stanie, musimy tylko zbudować odpowiednie kompetencje i zachować spokój oraz wzajemną życzliwość, gdy budujemy wspólne miejsce do życia.
UWAGA! Już niedługo ukaże się pierwszy polski ebook o Big Data. Całkowicie za darmo dla subskrybentów bloga RDF. Zapisując się na newsletter TERAZ – masz niepowtarzalną okazję dostawać kolejne wersje książki i zgłaszać swoje poprawki, a nawet stać się jednym z autorów. Więcej tutaj.
Wojna dla większości z nas to czołgi, żołnierze z karabinami i naloty. Dla tych ciut “nowocześniejszych” to także drony i satelitarne rozpoznanie. Prawda jednak jest taka, że współczesna wojna zaczyna się znacznie, znacznie wcześniej – na długo przed pierwszym wystrzałem. To wojna informacyjna, która poprzedza konflikt gorący. Co ważne – wojna informacyjna nie kończy się w momencie pierwszego uderzenia rakiet. Co jeszcze ważniejsze – ona nie kończy się nawet wraz z ogłoszeniem rozejmu. To podstawowy front, dzięki któremu zdobywa się cele polityczne i kształtuje świadomość. I tutaj – niespodzianka! – Big Data odgrywa bardzo ważną rolę. Zrób sobie solidną kawę i zapraszam na trzeci odcinek z serii “Big Data na wojnie”!
Mgła wojny informacyjnej
Wchodzisz na Twittera i widzisz ciąg postów. Część dotyka kwestii ekonomicznych, w niektórych to politycy nawzajem przekrzykują się który z nich napsuł więcej. Klasyka. W końcu trafiasz na podrzuconą wiadomość jednego z użytkowników. Widzisz go pierwszy raz, ale sama wiadomość przyciąga wzrok – wszystko w kontekście agresji rosyjskiej i pomocy Polaków względem Ukraińców.
“Czas na przerwę. Poziom spierdolenia większości na fali romantycznego uniesienia w walce o interesy cwaniaków i idiotów przekroczył granice samodzielnie myślącego człowieka”.
Przekonuj Cię to? Może zbyt wulgarne? Więc może raczej to?
“Większość przybyszów z Ukrainy ucieka przed reżymem Żełeńskiego. Wojna to tylko okazja. To nie jest ich wina! Trzeba podejść ze zrozumieniem.”
Wydaje się wciąż zbyt mocne? A może jesteś patriotą/patriotką? W takim razie zaciekawi Cię biało-czerwona grafika i post zmuszający do przemyśleń.
“Biało czerwona – oto jedyna flaga jaką kocham i respektuję! I jedyna, którą znajdziecie w mojej klapie“
Każdy z tych postów jest inny. Każdy ma inne wyważenie, każdy uderza w inny obszar potencjalnych wątpliwości. Prawdopodobnie część z nich Cię odrzuciła, być może tylko jednego nie odrzucisz. I to już coś.
Wojna dezinformacyjna nie jest prosta i siermiężna. Wywołuje wątpliwości na wielu poziomach. Adresowana jest do różnych osób. Każdy z nas ma inną wrażliwość i inne doświadczenia życiowe. W wojnie informacyjnej grunt, żeby wykorzystać odpowiednie narzędzia do odpowiednich osób.
Będąc “w środku” całego zamieszania, nie widzimy prawidłowego kształtu wojny informacyjnej. Widzimy jedynie jeden post, drugi, trzeci. Do tego komentarz, grafikę i film. Każdy z tych bodźców odbieramy niejako osobno. Taką właśnie sytuację możemy nazwać nowoczesną odmianą Mgły Wojny – pojęcia, które klasyk wojskowości i geopolityki Carl von Clausewitz wprowadził w… 1832 roku.
Tak nawiasem – wpisy powyżej nie są prawdziwe. Ale każdy z nich pod podobną postacią faktycznie był opublikowany. Zmieniłem, aby nie wskazywać na konkretne osoby. Dociekliwi jednak znajdą ich prawdziwych autorów bez problemu;-).
Budowa mediów społecznościowych
Być może to zabrzmi spiskowo, ale to jakie treści widzisz na tablicy Twittera, to nie przypadek. Na szczęście to żaden spisek – to czysta matematyka. Aby to mniej więcej zrozumieć, pomyślmy o tym jak zbudowane są media społecznościowe i jak działają.
Mały “disclaimer”
W tym rozdziale stosuję bardzo dużo daleko idących uproszczeń:
Będę często mówił “media społecznościowe” a potem opisywał budowę Twittera. Chociaż każde medium jest zbudowane inaczej, ogólna architektura jest dość podobna. Twitter natomiast jest najprostszy, a do tego w kwestiach polityczno-społecznych, wykorzystywany jest bardzo mocno.
Będę opisywał media społecznościowe jako graf. Ich faktyczna budowa jest oczywiście znacznie bardziej skomplikowana.
Opiszę algorytmy. Tak naprawdę nie przedstawię żadnego algorytmu wprost. Po pierwsze, byłoby to absolutnie niezjadliwe w takim artykule. Po drugie – algorytmy te nie są jawne i publiczne (nie znam ich). Musimy się domyślać, ale ogólne mechanizmy nie są wcale takie znowu bardzo niejasne.
Mam nadzieję, że to nie przeszkodzi w niczym.
Jeden wielki graf
Media społecznościowe <uproszczenie> to jeden wielki graf </uproszczenie>. Ba – nasze społeczeństwo to jeden, naprawdę ogromny, graf. A tak naprawdę wiele bardzo różnych, ogromnych grafów.
Ale zaraz… czym w ogóle jest graf? Wyobraź sobie, że budujesz drzewo genealogiczne swojej rodziny. Dla uproszczenia – na papierze;-). Wypiszesz więc członków rodziny – najczęściej jako zdjęcia w kółkach, oraz pokrewieństwa – jako kreseczki między nimi. To właśnie jest dość specyficzny graf. Dokładnie to DAG, czyli graf skierowany, acykliczny, a jeszcze dokładniej – to drzewo. Nie jest to jednak istotne, natomiast aby poszerzyć swoje matematyczne pojęcie na ten temat, można zerknąć choćby do Wikipedii;-).
Typowy graf matematyczny (źródło: wikipedia)
Tak więc w grafie mamy dwie podstawowe rzeczy:
Węzły/wierzchołki (nodes) – w przypadku naszego drzewa genealogicznego będą to ludzie.
Połączenia/ścieżki/krawędzie (connections/links/edges) – połączenia między węzłami. Ma to byś skonstruowane w taki sposób, że krawędzie zawsze łączą się z dwoma wierzchołkami.
Jak media społecznościowe nas “ugrafiawiają”?
Bardzo podobną konstrukcję można zaobserwować w mediach społecznościowych. Weźmy najprostszą płaszczyznę na tapet:
Konta użytkowników są wierzchołkami grafu
Jeśli dane konto kogoś obserwuje – tworzymy połączenie (krawędź) od jednego do drugiego konta.
Grafów jednak może być więcej. Chociażby w kontekście komentowania postów czy kliknięć “serduszek”. W niczym jednak taka mnogość nie przeszkadza. Co więcej – grafy te można na siebie n nakładać, aby wychwytywać te najmocniejsze połączenia.
Słynne algorytmy mediów społecznościowych
Niejednokrotnie słyszeliśmy o kontrowersyjnych “algorytmach Facebooka”. Mają one premiować treści kontrowersyjne, wzbudzające podziały. O co w tym wszystkim chodzi? Otóż – na naszej tablicy nie pojawiają się jedynie wpisy osób które obserwujemy. Co więcej – nawet jeśli tych osób, to też jedynie wybrane. Jak to się dzieje? Tu wchodzimy w sferę domysłów. Natomiast – mediom społecznościowym zależy na utrzymaniu naszej uwagi jak najdłużej. W związku z tym musi wybrać te posty, które nam się wyświetlą i które utrzymają naszą uwagę możliwie długo. Jeśli się da – dobrze byłoby nas wciągnąć w jakąś dyskusję.
Frances Haugen (po prawej) to sygnalistka. Była pracownica Facebooka ujawniła ogromną ilość dokumentów wewnętrznych, które mają wskazywać, jakoby premiowane miały być treści kontrowersyjne, polaryzacyjne.
Właśnie dlatego wybierane są tweety, które… są popularne. To dość proste założenie. Jeśli coś nabiera sporą popularność- jest szansa, że spodoba się także innym użytkownikom. Liczą się więc wyświetlenia, ale przede wszystkim wszelkie reakcje – polubienia, podanie dalej, komentarz. Dodatkowo mechanizmy wiedzą ile czasu spędzamy nad danym postem/zdjęciem – to także zapewne ma znaczenie.
Co więcej – sama treść także może mieć znaczenie. Dzięki algorytmom Machine Learning, Facebook wie o tym czy dana treść będzie pozytywna czy negatywna. Wzbudzająca emocje, czy raczej “sucha”. Tu nie chodzi o samo proste badanie sentymentu – w założeniu są tu dużo, dużo większe możliwości.
Piszę tu nie bez powodu o Facebooku. W 2021 r. za sprawą byłej pracownicy Korporacji, Frances Haugen, świat poznał dziesiątki tysięcy wewnętrznych dokumentów tego medium. “Facebook Papers” – jak zostały nazwane dokumenty – pokazują, że premiowane są najbardziej kontrowersyjne, polaryzacyjne treści.
“Gniew i nienawiść jest najłatwiejszym sposobem na wzrost na Facebooku”
Frances Haugen
Walka z dezinformacją – Rozpoznanie niewidocznych wzorców
Wykorzystanie mechanizmów do szerzenia dezinformacji
Czas dobrnąć do brzegu, na którym zrozumiemy dlaczego to wszystko jest tak bardzo istotne. Choć oczywiście zaledwie liznęliśmy wątek budowy mediów społecznościowych – mamy już ogólne pojęcie w temacie. Jeśli widzimy strukturę oraz skomplikowane algorytmy, prosty wniosek jest taki, że możemy się… pod nie podczepić. Nie musimy Mieć gigantycznych zasięgów aby mieć wpływ. “Wystarczy” odpowiednio zbudowana siatka, która generuje specyficzne treści i w przemyślany sposób je dystrybuuje.
Tak zbudowana maszynka może podawać rozmaite rodzaje tweetów (jak pokazałem powyżej). Ponieważ jest to siatka, utworzenie w sztuczny sposób popularności nie musi być trudne. Stworzenie polaryzacyjnych treści też nie. Tak zredagowane wpisy automatycznie wykryje maszynka Twittera i pokaże innym, którzy mogą być zainteresowani. W ten sposób cała siatka powiększa się o osoby nie będące trollami, które często nieświadomie szerzą propagandę. Takie osoby nie mają oczywiście świadomości tego co robią, ponieważ widzą jedynie jednostkowy tweet, są owładnięte “mgłą wojny informacyjnej”.
Jan C z Data Hunters: “Rosyjskie trole w natarciu. Wygląda, że tak samo im blisko do propagowania niedlasegregacjisanitarnej jak i niewspieramukrainy #dezinformacja #osint #UkraineWar #Poland”
Działania kontr-dezinformacyjne. Rozpędzanie “mgły wojny”
Oczywiście za tym wszystkim stoją potężne mechanizmy operowania na ogromnych zbiorach danych. Osoby projektujące rozgrywki w ramach wojny informacyjnej wykorzystują je inteligentnie. Mają ogląd “z góry”, w przeciwieństwie do “ofiar”, które spowite są mgłą wojny.
Na szczęście jest nadzieja. Można – wykorzystując narzędzia Big Data – wyfrunąć do góry i z lotu ptaka spojrzeć na całość. Dzięki temu możemy odrobinę pominąć mgłę wojny i zacząć szukać wzorców i całych siatek, które daną dezinformację szerzą.
Jak za pomocą narzędzi Big Data wykryć siatki?
Chciałbym bardzo w tym miejscu podzielić się swoim własnym doświadczeniem. Miałem okazję i zaszczyt pracować z jednym z narzędzi, które obecnie jest testowane, w grupie kilku badaczy. TTM – robocza nazwa – pozwala na pobieranie z Twittera danych i poddawanie ich odpowiedniej analizie grafowej. Następnie, dzięki narzędziu Graphistry można zwizualizować sobie wynik odpowiedniej analizy. Więcej na ten temat można przeczytać na blogu Data Hunters.
W podlinkowanym artykule można przeczytać dokładnie zdarzenia od których wyszliśmy z naszą analizą. Tutaj chciałbym wyselekcjonować kilka kroków, które moim zdaniem wspaniale pozwalają wykorzystać automatyzację i możliwości przeczesywania setek tysięcy, czy nawet milionów kont Twitterowych. Co ważne: nie jest (i nie powinien być) to proces w pełni automatyczny. Aspekt ludzki zawsze będzie tutaj istotny. Odpowiednie mechanizmy mogą jednak umożliwić dotarcie do tego co istotne.
Oto potencjalny schemat, podobny do tego który my stosowaliśmy:
Wyszukiwanie ogólnych wzorców – pierwszy krok to zlecenie wykonania analizy przez mechanizm. To bardziej sztuka niż rzemiosło. Musimy zastanowić się które zachowania mogą nas odrobine naprowadzić na ludzi szerzących dezinformację. Możemy więc poszukiwać po ludziach którzy wykorzystują odpowiednie hashtagi, którzy wchodzili w interakcje z innymi kontami czy takimi, którzy udostępnili konkretne tweety. Nie należy ograniczać się w tym punkcie jedynie do naszej tematyki. Bardzo popularnym wzorcem była transformacja kont “anty-covidowych”. Można też sprawdzać najbardziej wulgarne hashtagi antyrządowe itd.
Selekcja i statystyki powtarzających się dużych wierzchołków – po wielu przeprowadzonych analizach, część kont zaczyna się powtarzać w wielu kontekstach. Warto więc “odłożyć je na bok” i sprawdzić także inne dane na ich temat. Mogą to być statystyki publikowanych tweetów, czas aktywności (konto które jest aktywne 20-24 h na dobę, jest podejrzane z natury) itd.
Weryfikacja ręczna – na sam koniec najmniej przyjemna część. Po wielkiej obróbce z pierwszego punktu i częściowym obcięciu w drugim – czas po prostu przejrzeć te konta ręcznie. Może bowiem być tak, że wszelkie poszlaki wskazują na konta, których absolutnie nie można zaliczyć do trolli. Część natomiast można i warto:-).
Dokładniejszy opis tego jak działaliśmy znajduje się w podlinkowanym artykule. Natomiast powiem jedno: dzięki takiej analizie nie tylko znaleźliśmy konta, które były nieoczywiste. Także odkryliśmy zmianę taktyki, która polegała na zmniejszeniu liczby hashtagów. Co – dla mnie osobiście – najciekawsze, znaleźliśmy przygotowywaną od dawna siatkę, która stroniła od bycia ogromnymi ośrodkami. Utrzymywała się za to w trudnym do wykrycia obszarze średniej wielkości.
Podsumowanie
Wojna informacyjna jest współcześnie ogromną częścią rywalizacji międzynarodowej. Musimy zdawać sobie sprawę, że działania te są prowadzone tam, gdzie jesteśmy my. W tym artykule opisałem na czym polega mgła wojny informacyjnej. Jak w nią wpadamy i… jak wykorzystując narzędzia Big Data można z dezinformacją walczyć.
W kontekście osobistego przeciwdziałania i obrony – uważam, że najważniejsze to zachować zdrowy sceptycyzm do wszystkiego co wywołuje duże emocje. Jednocześnie z zachowaniem dużej dozy szacunku do każdego z kim rozmawiamy. Jeśli to osiągniemy – dezinformacja będzie przynosić znacznie mniejsze owoce.
Daj znać w komentarzu jak się podobało. Zapraszam też na profil RDF na LinkedIn oraz do newslettera. Pozostańmy w kontakcie!
UWAGA! Już niedługo ukaże się pierwszy polski ebook o Big Data. Całkowicie za darmo dla subskrybentów bloga RDF. Zapisując się na newsletter TERAZ – masz niepowtarzalną okazję dostawać kolejne wersje książki i zgłaszać swoje poprawki, a nawet stać się jednym z autorów. Więcej tutaj.
“Zwykłym rozporządzeniem planuje się w Polsce utworzenie gigantycznej bazy danych, łączącej informacje z prawie wszystkich możliwych rejestrów” pisze “Dziennik Gazeta Prawna”. Tytuł: “Orwell po polsku. Rząd pracuje nad megabazą. >>Potencjał do nadużyć<<“. W tym artykule opiszę jak taka “Megabaza” miałaby być zbudowana. W kolejnych – czy to dobry pomysł oraz… jak można by taki system zbudować. Zapraszam!
Czym miałaby być “megabaza”?
Żyjemy w świecie gospodarki cyfrowej. Nie tylko firmy, ale i administracja państwowa zbierają od nas dane. Te są bardziej lub mniej wrażliwe. W formie elektronicznej państwo ma więc dostęp do numeru dowodu osobistego, danych medycznych, informacji związanych ze stanem cywilnym i wielu, wielu innych. W tym momencie jednak istnieje ogromna liczba “małych” baz danych. Każda z nich odpowiada za inne informacje o nas i podlega innym jednostkom (np. jedne ministerstwu finansów, inne zdrowia itd.).
Rodzi to wiele problemów ze sprawnością funkcjonowania państwa oraz możliwościami wykorzystania danych, które ono posiada. Możemy intuicyjnie denerwować się, że w wielu miejscach podajemy te same dane, albo że jedna instytucja nie może funkcjonować sprawnie i skutecznie tylko dlatego, że nie ma dostępu do danych zgromadzonych przez inną. Trochę tak, jakby w małej firmie pomagającej w poprawie zdrowia rehabilitanci od kręgosłupa nie mieli dostępu do danych pacjentów od działu dietetyków.
Częściowo tego typu problemy ma zmienić planowana Megabaza (powinniśmy ująć w cudzysłów, ale nazwijmy już ją tak na potrzeby artykułu). Będzie ona spajać informacje z bardzo wielu państwowych miejsc w ramach jednego ogromnego centrum danych.
Czym NIE BĘDZIE Megabaza?
Warto jednak podkreślić, że planowana Megabaza nie będzie tym, o czym możemy w pierwszym momencie pomyśleć. Nie będzie miejscem szybkiego dostępu do połączonych danych każdego z nas. Możemy sobie wyobrazić sytuację, w której urzędnik ministerstwa finansów z ciekawości sprawdzi nie tylko dane firmy, w której będzie przeprowadzał kontrolę, ale i wyznanie, dane dotyczące dzieci i żony Prezesa owej firmy. Tego nie będzie.
Oto dlaczego. Megabaza nie będzie służyła do szybkiego przeglądania naszych danych. Będzie to raczej miejsce zbiorczego przechowywania informacji w celach analiz. Jak pisze portal DGP:
“Założenie jest takie, że dany podmiot publiczny zgłasza potrzebę przeprowadzenia konkretnych analiz. Minister cyfryzacji występuje do administratorów odpowiednich rejestrów, a ci przekazują mu dane po pseudonimizacji. W teorii po przeprowadzeniu analiz mają być one wykasowane. “
Czym różni się pseudonimizacja od anonimizacji?
Pada powyżej pojęcie “pseudonimizacji”. Podobnie brzmiąca jest również “anonimizacja”. Czym różnią się od siebie i dlaczego to istotne w tym kontekście? Sprawa jest bardzo prosta:
Anonimizacja to proces “ukrycia” danych w taki sposób, żeby nie dało się ich w żaden sposób poznać, ani do nich wrócić. Można anonimizować dane nie tylko przy pomocy nowoczesnych technik i technologii. “Analogowym” sposobem anonimizacji może być na przykład zakreślenie czarnym markerem nazwiska (a potem wykonanie kserokopii, aby zlikwidować prześwitywanie). Jeśli mówimy o cyfrowym zapisie, można usunąć konkretne dane, wylosować dowolny ciąg znaków lub – jeśli musimy zachować możliwość odwołania się do tych samych rekordów, można wykorzystać funkcję skrótu w określony sposób.
Pseudonimizacja – proces, który ma na celu to samo co anonimizacja, czyli ukrycie konkretnych danych (np. PESEL). Różni się jednak tą zasadniczą rzeczą, że pseudonimizację można odwrócić. Najbardziej popularnym sposobem jest po prostu szyfrowanie danych z kluczem tajnym (np. szyfrem AES). Dzięki temu, mając klucz, zawsze możemy dane odszyfrować.
Jedną z rzeczy które można spotkać szeroko w Internecie jest wymienienie funkcji skrótu jako metody pseudonimizacji. Być może się mylę (jeśli tak – nawróć mnie w komentarzu!), ale nie mogę się z tym zgodzić. Funkcje skrótu dążą do tego żeby nie dało się na podstawie konkretnego skrótu dotrzeć do pierwotnej wiadomości. Spełniają więc wymogi anonimizacji, nie pseudonimizacji. Oczywiście temat nie jest jednoznaczny i są określone warunki w których można by “odgadnąć” zahashowane wartości, ale sam mechanizm moim zdaniem jest anonimizacyjny.
W naszej Megabazie wyniki analiz mają być pseudonimizowane i w takiej formie wysyłane do zlecających analizę. To właśnie wzbudza pewne obawy ekspertów oraz aktywistów działających na rzecz przejrzystości działań władzy.
“Na dodatek nie wiem, jak wyglądać ma pseudonimizacja danych, która jest przecież procesem odwracalnym. Jeśli dane mają służyć do celów analitycznych, to oczywiste jest dla mnie, że powinny przechodzić proces pełnej anonimizacji “
Powyższy cytat pochodzi z wypowiedzi Wojciecha Klickiego z Fundacji Panoptykon. Tutaj wyjątkowo muszę się zgodzić. Chociaż fundacja Panoptykon jest organizacją kontrowersyjną, działającą wielokrotnie w sposób, który uważam za co najmniej niewłaściwy, w tym przypadku obawy są uzasadnione. Być może pseudonimizacja ma sens. Jeśli jednak tak jest, władze powinny dołożyć starań, aby to uzasadnić.
Z jakich źródeł będzie czerpać Megabaza?
Napisaliśmy już trochę na temat tego czym będzie a czym nie będzie Megabaza. Z jakich jednak dokładnie źródeł będzie korzystać? Poniżej lista instytucji:
Rejestr PESEL
Krajowa Ewidencja Podatników
Rejestr Stanu Cywilnego
Rejestr Dowodów Osobistych
Rejestr Ministra Właściwego do Spraw Pracy
Rejestr ZUS i KRUS
Rejestry dotyczące świadczeń rodzinnych czy osób uprawnionych do alimentów
Rejestry GUS
Rejestry NFZ
System informacji o ochronie zdrowia
Rejestry oświatowe
Podsumowanie
Słowem podsumowania: Rząd planuje zbudowanie wielkiej Megabazy, która będzie spajać wiele zbiorów dostępnych dla administracji. Warto podkreślić jednak, że nie będzie to baza, do której każdy urzędnik będzie miał szybki, swobodny dostęp. Będzie to repozytorium, które ma usprawnić państwową analitykę.
W tym artykule przyjrzeliśmy się pobieżnie temu czym ma być rządowa Megabaza i z jakich źródeł ma się składać. W kolejnym artykule opiszę obawy oraz szanse, które dałoby zbudowanie tego typu systemu. Na samym końcu – rozrysuję jak można takie repozytorium skonstruować.
UWAGA! Już niedługo ukaże się pierwszy polski ebook o Big Data. Całkowicie za darmo dla subskrybentów bloga RDF. Zapisując się na newsletter TERAZ – masz niepowtarzalną okazję dostawać kolejne wersje książki i zgłaszać swoje poprawki, a nawet stać się jednym z autorów. Więcej tutaj.
USA kojarzą nam się z potęgą zarówno technologiczną jak i militarną. Nie bez powodu. To tutaj zrodziła się branża Big Data. To ten kraj ma najpotężniejszą armię na świecie. Pytanie jednak, czy zawsze te dwie rzeczy idą w parze? Dziś poznamy jeden z przykładów tego jak Big Data i sztuczna inteligencja (AI) wykorzystywane są w amerykańskiej armii. Bierzmy więc kubek żołnierskiej czarnej kawy w dłoń i przejdźmy przez drugi odcinek z serii “Big Data na wojnie”!
Drony, dominacja USA i… absurdy rodem z parodii państwowości
Hegemonia zobowiązuje
USA to nie jest “normalny kraj”. Nie, nie mam na myśli tego, że to stan umysłu. Nie należy jednak porównywać jakiegokolwiek państwa do Amerykanów z jednego prostego powodu: Stany Zjednoczone rządzą światem. To imperium, które ustawiło pod siebie cały glob. Teraz co prawda ulega to pewnym zmianom, ale to rozmowa na inny artykuł. Na innym blogu;-).
Skutkuje to nie tylko profitami, ale i zobowiązaniami. Podstawowym zobowiązaniem jest to, że Amerykanie muszą militarnie “obstawiać” cały świat. Oznacza to nie tylko obecność sił zbrojnych na określonych terenach, ale także stały monitoring miejsc, w których Hegemon ma swoje interesy. W siłach zbrojnych Stanów Zjednoczonych służy ok. 1.3 mln żołnierzy nie licząc rezerwistów oraz Gwardii Narodowej (mniej więcej odpowiednik naszych Wojsko Obrony Terytorialnej). Każdy żołnierz kosztuje swoje i jego wyszkolenie oraz – co jasne – życie, jest na wagę złota.
Z tego powodu wojska amerykańskie od dłuższego czasu prowadzą wiele bardzo intensywnych prac badawczych (których skutkiem jest m.in. Internet) mających na celu rozwój nowoczesnych technologii czy robotyzację pola walki. Jednym ze skutków takich prac są drony. To samoloty bezzałogowe, które nie tylko są tańsze w produkcji od myśliwców i prostsze w użyciu. Co najważniejsze – pilot drona nie jest bezpośrednio narażony, siedzi w ciepłym i przyjemnym zakątku, sterując przez komputer swoją maszyną.
Monitoring najważniejszych miejsc na świecie
To właśnie drony są wykorzystywane do uderzenia z powietrza. Pełnią jednak także inną rolę – zwiadowczą. Dzięki nim można “podglądać” w bardzo solidnej jakości wiele miejsc na Ziemi. Poza stałym monitoringiem, zapisy z latających czujników stanowią znakomity materiał do analizy wstecznej. Jeśli dochodzi do jakiegoś ataku terrorystycznego czy podejrzanych ruchów, można bez problemu odszukać nagranie z tamtego momentu i przeanalizować minuta po minucie, sekunda po sekundzie.
Także Polska może pochwalić się sukcesami na rynku dronowym. Widoczny na zdjęciu FlyEye to polski samolot bezzałogowy służący celom zwiadowczym. Niezwykle popularny na wojnie za naszą wschodnią granicą – w służbie armii Ukraińskiej oczywiście.
Pentagon wydał dziesiątki miliardów dolarów na tego typu systemu obserwacji. Dzięki temu, jeśli ktokolwiek podłożył bombę, można po prostu przewinąć wideo do tyłu i sprawdzić kto to był, dokąd poszedł itd. Tego typu system obserwacji to fascynujący pomysł, dający gigantyczne możliwości analityczne. Skoro więc mamy całą flotę dronów uzbrojonych w czujniki, nadających do nas obrazy wideo, co jest oczywistym kolejnym krokiem? Warto wskazać, że pojedyncze drony z tego typu czujnikami gromadzą wiele terabajtów danych… dziennie.
W związku z powyższym nie będzie chyba zbyt kontrowersyjne stwierdzenie, że oczywistym jest zbudowanie systemu który tego typu dane kataloguje i automatycznie analizuje prawda?
Biurokratyczne absurdy także za oceanem
Otóż, jak się okazuje – niekoniecznie. Żaden inteligentny system nie powstał. Co prawda był pewien storage, w którym umieszczano nagrane wideo. Znakomita większość jednak… nigdy nie była przeanalizowana. Jak to się mogło stać? Otóż, rozwiązaniem według DoD (Departamentu Obrony – ang. Department of Defense)wcale nie było zbudowanie inteligentnego systemu analitycznego, ale… utworzenie odpowiednio dużego sztabu ludzi. Ludzi, którzy siedzieli przez 24h na dobę (praca zmianowa), patrzyli w ekran i… liczyli. Liczyli auta, ludzi, budynki itd. Następnie sprawnie tego typu dane przepisywali do… excela lub powerpointa i wysyłali dalej.
Brzmi absurdalnie? Takie właśnie jest! I dzieje się to w Stanach Zjednoczonych Ameryki. Nie w małej firmie pod Białymstokiem, ale w najpotężniejszym kraju na świecie, o ugruntowanej państwowości
Project Maven, czyli jak wynieść organizację na wyższy poziom
Aby powyższy stan rzeczy zakończyć, podjęta została decyzja o zbudowaniu “Project Maven”. To repozytorium, które miało stać się systemem do inteligentnej analizy materiałów z czujników bezzałogowców. To jednak nie jest jedyna rola Mavena. Projekt ten miał w zamierzeniu stać się przyczółkiem dla metodycznego wykorzystania Big Data oraz sztucznej inteligencji (AI) w armii amerykańskiej. Chociaż USA są synonimem postępu i nowoczesności, w wojsku ciągle wiele elementów działało jak podczas II Wojny Światowej. Wpuszczenie systemów przetwarzania dużych danych miało to zmienić.
Maven skupia się na analizie danych wideo z różnych platform dronowych:
Scan Eagle
MQ-1C Gray Eagle
MQ-9 Reaper.
Podstawowym celem Projektu miała być automatyczna identyfikacja obiektów rejestrowanych przez kamery Dronów. Co warte podkreślenia – w tworzenie całego systemu zaangażowane były podmioty prywatne. Jedną z firm tworzących repozytorium było Google. Ciężko o bardziej trafną decyzję – to od tej firmy zaczęła się “prawdziwa Big Data” i spod jej skrzydeł wyszły niezwykle istotne technologie, będące właściwie fundamentem branży. W związku z ujawnieniem wewnątrz Google współpracy z Pentagonem, wybuchł protest pracowników. Ci rządali wycofania się z procesu, tłumacząc to niezgodnością z linią etyczną firmy i ich hasłem przewodnim “Don’t be evil” (nie bądź zły). To jednak zupełnie na marginesie.
Projekt Maven miał rozwiązać jeszcze jeden problem: biurokrację. Dotychczas jedynie ludzkie oko (i oczywiście mózg) były wyznacznikami tego czy cel widziany przez bezzałogowiec jest wrogiem, czy nie. W związku z tragicznymi pomyłkami, procedury dotyczące możliwości podjęcia ostrzału bardzo mocno spowolniły czas między obserwacją, a ogniem. Znakomicie wyuczone mechanizmy mają na celu przyspieszenie całego procesu.
Jak mógłby wyglądać “Project Maven”?
Na końcu proponuję zabawę. Skoro jesteśmy na blogu stricte poświęconym Big Data – spróbujmy zastanowić się jak mogłoby wyglądać Maven pod kątem technicznym, a przynajmniej architektonicznym – w najbardziej ogólnym rozumieniu tego słowa. Nie próbujemy domyślić się jak było to robione w Pentagonie, ale jak analogiczny system mógłby być zbudowany u nas, na potrzeby Wojska Polskiego.
Nasza specyfika jest oczywiście zupełnie inna. Nie musimy obserwować połowy świata. Załóżmy jednak, że chcemy bardzo precyzyjnie monitorować całą granicę wschodnią i otrzymywać alerty, jeśli coś niewłaściwego się tam dzieje. Ponieważ nasza granica jest dość długa, przygotujemy system który automatycznie powiadamia o podejrzanych ruchach oraz pozwala przeszukiwać informacje o aktualnym stanie oraz stanie z określonego momentu w historii.
Przykładowy slajd wysłany do zatwierdzenia w procesie uczenia oryginalnego projektu Maven.
Zastanówmy się więc jak to może wyglądać.
Storage – tak nazwijmy ogólną część, w której składujemy dane.
Moduł do uczenia
System alertów
Moduł do analizy
Jaka infrastruktura?
Zacznijmy od bardzo ważnej kwestii! Konkretnie od powiedzenia sobie wprost: taki system absolutnie nie może być zbudowany z wykorzystaniem rozwiązań chmurowych. Być może to kontrowersyjna teza, ale obecnie najwięksi dostawcy to firmy zagraniczne. W przypadku tego typu produktu podstawową cechą musi być bezpieczeństwo. Nie owijając w bawełnę – nie tylko bezpieczeństwo przed włamaniami rosyjskich hakerów. To są dane, które po prostu nie mogą być zależne od zagranicznej infrastruktury (nawet jeśli jest położona na terenie Polski). Rozumiem, że wiele osób może mieć odmienne zdanie, szanuję to, ale się z nim nie zgadzam. Zakładam więc budowę systemu na własnej infrastrukturze (on-premise).
Nic nie stoi jednak na przeszkodzie, abyś Ty rozpisał/a podobną architekturę dla rozwiązań chmurowych;-). Napisz i wyślij, a ja z pewnością opublikuję.
Storage
W tym miejscu musimy się zastanowić w jaki sposób składować dane. To tutaj będą trafiać w pierwszym kroku, ale nie tylko. Oczywiście taki moduł może składać się z więcej niż jednej technologii do składowania danych!
Co dokładnie moglibyśmy tutaj umieścić? Zacznijmy od pierwszej przestrzeni, gdzie lądować miałyby surowe dane. Proponuję tutaj jedną z dwóch technologii:
W takim miejscu możemy przede wszystkim składować wszystkie możliwe pliki wideo, które będą przesyłane przez drony. Następnie pliki te byłyby odczytywane i zapisywane do którejś bazy danych w formie metadanych (np. jakie obiekty są w jakim momencie nagrania, co to za samolot itd). Może to być HBase (który współgra zarówno z HDFS jak i z Ozone).
Moduł do uczenia
Oczywiście w “naszym Mavenie” musimy mieć modele, dzięki którym będziemy mogli rozpoznawać konkretne obiekty, ludzi, broń itd. Aby to zrobić, musimy utworzyć moduł uczący. W jego ramach możemy zrobić tak jak w amerykańskim odpowiedniku – najpierw trzeba przejrzeć bardzo bardzo wiele materiałów, a następnie otagować co tam się znajduje, jak to wygląda itd. W kolejnym etapie utworzymy klasyczny zbiór uczący i testowy, a następnie wytrenujemy konkretne modele dzięki uczeniu nadzorowanemu (co możemy zrobić dzięki otagowanym materiałom).
Jakie technologie możemy tutaj zastosować? Możemy pójść w stronę wykorzystania bibliotek pythonowych – i wtedy próbować swoich sił z TensorFlow. Możemy także popracować z Apache Spark ML i deep learning, który oferują na coraz lepszym poziomie jego twórcy.
System Alertów
Następny moduł który powinniśmy omówić to system alertów. Chodzi o to, aby nasi żołnierze z Wojsk Obrony Cyberprzestrzeni nie ślęczeli przed widokami przekazywanymi z każdego z dronów, ale by byli powiadamiani o potencjalnych anomaliach zawczasu przez zautomatyzowany system.
Tutaj moja propozycja jest prosta:
Kafka, na którą trafiają obrazy wideo
Consumer przygotowany przez Spark Structured Streaming, który przetwarza te obrazy z wykorzystaniem wcześniejszych modeli i rozbiera je na części pierwsze (podobnie jak to się dzieje w punkcie pierwszym – Storage). Następnie, w formie lżejszych informacji (metadane) przesyła na kolejny endpoind kafki.
Consumer znów przygotowany przez Spark Structured Streaming, ale nasłuchujący na drugim endpoincie – z metadanymi. Jeśli informacje, które się tam pojawią są podejrzane, wysyłany jest alert do przygotowanej aplikacji, przed którą siedzą nasi żołnierze WOC.
Moduł do analizy
Ostatnim elementem który został nam do ogrania jest moduł do analizy. tutaj pomijamy system streamingowy i niejako zataczamy koło, trafiając do naszego Storage. Z tego miejsca musimy zbudować job, który pozwoli nam sprawnie indeksować dane z bazy danych do technologii full-text search. Oto co proponuję:
Spark, który wyciąga dane z HBase i umieszcza je (być może w odpowiednio okrojonej formie) w Elasticsearch
Elasticsearch, który przechowuje dane.
Kibana, która pozwala nam analizować dane umieszczone w Elasticsearch.
Podsumowanie
Oczywiście powyższe zalecenia to raczej intelektualna zabawa, nie poważna analiza i architektura. Służy jednak pobudzeniu myślenia o tym jak można patrzeć na systemy oraz wskazać, że nie są one poza naszym zasięgiem.
Podsumujmy: Amerykanie także mają swoje miejsca wstydu, które wyglądają jakby były rodem z II Wojny Światowej. Rozwiązaniem części z nich, oraz zalążkiem Big Data w Pentagonie, miał (ma) być “Project Maven” który byłby pewnym repozytorium materiałów dronowych. W jego ramach odbywałoby się uczenie i analiza obiektów widzianych przez bezzałogowce.
Jak pokazałem, my także możemy rozwijać nasze siły zbrojne w kontekście Big Data oraz AI. Mam nadzieję, że tak się dzieje – jednym z symptomów zmian jest utworzenie Wojsk Obrony Cyberprzestrzeni. Oby nie były to puste etaty, bo fachowców mamy w Polsce wspaniałych.
Daj znać w komentarzu jak się podobało. Zapraszam też na profil RDF na LinkedIn oraz do newslettera. Pozostańmy w kontakcie!
UWAGA! Już niedługo ukaże się pierwszy polski ebook o Big Data. Całkowicie za darmo dla subskrybentów bloga RDF. Zapisując się na newsletter TERAZ – masz niepowtarzalną okazję dostawać kolejne wersje książki i zgłaszać swoje poprawki, a nawet stać się jednym z autorów. Więcej tutaj.
Końcówka lutego 2022 roku. Rosja atakuje Ukrainę, a jednym z narzędzi rozbrajania przeciwnika jest Buk. Ten samobieżny system kierowanych rakiet ziemia-powietrze skutecznie może wykańczać flotę powietrzną lub bronić wojsko przed rakietami manewrującymi. Na szczęście Ukraina posiada w swoim arsenale tureckie drony Bayraktar. Na publicznie dostępnym wideo widać obraz komputerowego monitora z przekazem real-time lecącego nad rosyjskimi wojskami samolotu bezzałogowego. Sterujący zdalnie żołnierz bez problemu namierza system Buk i wciska przycisk. Po chwili na ekranie widać już tylko unoszące się tumany dymu i pyłu w miejscu uderzenia.
Nie byłoby to możliwe, gdyby nie rozbudowana praca na danych. W tym artykule chciałbym poruszyć problematykę konfliktów międzynarodowych właśnie z punktu widzenia zarządzania danymi i tego jaką rolę one odgrywają w całym zamieszaniu.
Dlaczego warto poznać kształt współczesnych konfliktów?
W tym miejscu był całkiem długawy wstęp. Nie rozwodząc się jednak zbytnio: jako ludzie mieszkający w kraju z takim położeniem, musimy “znać się na wojnie”. Świadomość zagrożenia i zdobywanie wiedzy na temat kształtu współczesnego pola walki nie jest niczym zdrożnym. Przeciwnie – świadczy o dojrzałości. Przygotowując się do walki (w każdy możliwy sposób), zmniejszamy prawdopodobieństwo jej wystąpienia.
Ja (na szczęście) nie jestem ekspertem od geopolityki. Postaram się jednak zbadać i podzielić tym jaką rolę na wojnie pełnią dane, elektronika i wysokie technologie, w tym Big Data. Dzisiejszy artykuł będzie zaledwie zajawką – żeby nie przegapić kolejnych, zapisz się na newsletter;-)
Współczesne pole bitwy wygląda zupełnie inaczej niż 100 lat temu. Nie jest to jednak wojna robotów, jaką możemy znać z filmów czy gier.
Zanim zacznie się wojna…
Działania poniżej progu wojny
Zanim działania przybiorą typowo wojenny, kinetyczny charakter, do gry wchodzą działania “poniżej progu wojny”. Choć nie jest to nic nowego pod słońcem, współcześnie działania zakrojone są na bardzo szeroką skalę i są znacznie prostsze do przeprowadzenia niż kiedyś. Celów jest wiele: od dezintegracji społeczeństwa (jesteśmy podzieleni, nie wiemy także kto jest po jakiej stronie ani gdzie jest prawda) aż po wzbudzenie braku zaufania do państwa i przywódców. Dzieje się to oczywiście na bardzo wielu poziomach – jest wprowadzanie na wysokie stanowiska półinteligentów i ludzi skorumpowanych. Są cyberataki, które podważają zaufanie do skuteczności państwa i wiele, wiele innych.
Media społecznościowe idealnym narzędziem szerzenia dezinformacji
Z naszej perspektywy warto jednak zwrócić uwagę na jeden aspekt – są nim media społecznościowe, które wyglądają, jakby wręcz były zaprojektowane po to, aby prowadzić działania “poniżej progu wojny”, co często upraszczane jest do miana “dezinformacji”. Jest to narzędzie bardzo istotne z samego faktu z jak wieloma informacjami zderzamy się, gdy przewiniemy tablicę. Choć nie analizujemy ich szczegółowo, nasz mózg nie radzi sobie z przyswojeniem takiej ilości informacji. W efekcie tego stara się tą skomplikowaną rzeczywistość bardzo uprościć, co czynu niejako automatycznie.
Zauważmy pewną ciekawą rzecz: wiele z informacji które spotykamy (niezależnie od konkretnego medium) nie pochodzi od autorów wybranych przez nas. Nawet jeśli, to nie są to treści wybrane w jakiś prosty sposób – na przykład chronologicznie.
Jakie treści zatem dostajemy?
Takie, które najprawdopodobniej polubimy (na co wskazują algorytmy uczące się, należące do konkretnego medium)
Te, które wzbudzają największe emocje
Takie, które są popularne
Te, których autorów oznaczyliśmy wprost, że chcemy widzieć każdy ich post.
Treści promowane, których autorzy dość precyzyjnie “wycelowali” swoją treść w nas.
Sposoby szerzenia dezinformacji dzięki konstrukcji mediów społecznościowych
Warto jednak zwrócić uwagę, że niekoniecznie musimy znać wcześniej konta, których posty widzimy. Można więc tak skonstruować przekaz, aby docierał do jak najszerszego odbiorcy i infekował go odpowiednimi treściami. W tym celu budowane są odpowiednie “farmy trolli” – całe złożone społeczności, które nawiązują relacje, dyskutują i udostępniają posty. Dzięki temu określone wypowiedzi są popularne, wychwytywane przez algorytmy i docierają dalej.
Jednoznaczne określenie bota nie jest proste. Analizator Twittera mojego autorstwa uznał za bota… Donalda Trumpa, ówczesnego Prezydenta USA. Stało się tak prawdopodobnie z wielu powodów. Jednym z nich mogła być legendarna właściwie aktywność na Twitterze byłego przywódcy ameryki.
Zbudowanie takich sztucznych kont przeprowadzane jest na wiele sposobów – z różnymi kosztami i różnymi skutkami. Najprostszym sposobem jest zbudowanie farmy botów, czyli automatycznych mechanizmów, które sterują kontami bez ingerencji człowieka. Te najprostsze po prostu masowo podają określone posty, nie mają uzupełnionych profili i generalnie łatwo je poznać. Te bardziej skomplikowane mają zdjęcia, prostą historię a nawet charakter wypowiedzi. Pomiędzy jednymi a drugimi jest oczywiście duże spektrum. Rosja jest państwem, które oficjalnie przyznaje, że ma swoich “etatowych trolli”. Są to ludzie, którzy zarządzają wieloma kontami i w ten sposób budują społeczności znacznie ciężej wykrywane niż zwykłe boty – o ile oczywiście robią to z pewnym kunsztem.
Nie ma w tym artykule miejsca na szerszy opis (będzie osobny artykuł – zapisz się na newsletter poniżej!). Być może najlepszym podsumowaniem będzie: “miej ograniczone zaufanie dla każdego profilu w sieci. Szczególnie jeśli go nie znasz. Nie każdy opiniotwórca ma dobre zamiary”. Pamiętajmy, że media społecznościowe są zbudowane w określony sposób, aby utrzymać naszą uwagę. I to właśnie te mechanizmy wykorzystywane są przez osoby/organizacje, aby szerzyć “za darmo” dezinformację na bardzo wysokim poziomie.
Rozpoznanie (obserwacja)
Drugim ważnym obszarem na współczesnym polu bitwy jest… obserwacja. Tutaj już powoli wkraczamy w “TĄ wojnę”. Przypomnijmy sobie ostatnie miesiące (i szczególnie tygodnie) przed napadem Rosji na Ukrainę. Jak wyglądał ten czas? Media bombardowały nas informacjami na temat tego jak wojska rosyjskie podchodzą pod granicę z Ukrainą. Dowiadywaliśmy się nie tylko gdzie są rozmieszczone, ale także ile ich jest (szacunkowo) oraz co to za siły.
Jednym z “oczu armii” obserwacji są drony obserwacyjne – m.in. Flye Eye konstrukcji i autorstwa polskiej firmy WB.
Rzadko kto zadawał sobie pytanie: “jak to możliwe?”. A przecież, jak się chwilę zastanowić, to właśnie możliwości obserwacyjne są dzisiaj (i nie tylko dzisiaj) kluczem do zrozumienia sytuacji. Dzięki temu praktycznie niemożliwy jest atak z zaskoczenia. Żyjemy ze świadomością, że w dowolnym momencie można spojrzeć w każdy punkt na kuli ziemskiej. Jesteśmy do tego przyzwyczajeni, trochę patrząc na to jak na grę komputerową. Nie dzieje się to jednak w żaden magiczny sposób.
To właśnie możliwości obserwacji decydują o tym co i kiedy będziemy widzieli. Możliwości, które dostarczają bardzo materialne maszyny zbierające i przesyłające dane. Warto podkreślić, że możliwości obserwacji, które nie są wcale dostępne dla każdego. I to z kolei daje poważne przewagi lub braki na współczesnym polu walki.
Satelity
Najbardziej podstawowym sposobem zdobywania zdolności obserwacyjnych są satelity. Te poruszają się na orbitach ziemi w celu obserwacji i przekazu sygnałów na żywo. Warto podkreślić ogromną wagę w znaczeniu geopolitycznym – państwa bez tego typu systemów są ślepe, lub zdane na inne państwa. Tymczasem koszt konstelacji nie jest wielki i zamyka się w kilkuset milionach zł (mowa o podstawowej konstelacji dla Polski).
Drony
Drugim elementem obserwacji o jakim warto powiedzieć są drony. Samoloty bezzałogowe wyposażone w systemy czujników, pozwalają zbierać obraz na żywo. W każdym momencie wiele tego typu maszyn na usługach armii amerykańskiej przeczesuje tereny w bardzo wielu zakątkach Ziemi. Warto tu podkreślić, że Amerykanie mają osobny system, którego celem jest przechowywanie i analiza obrazów z kamer. System ten nazywa się “Project Maven” i na jego temat pojawi się osobny artykuł – zapraszam do newslettera!
Stacje nasłuchowe
Ostatnim narzędziem o którym chciałbym wspomnieć są stacje nasłuchowe. Choć znakomita większość informacji jest utajniona, możemy dziś powiedzieć jasno: system inwigilacji Echelon to Big Datowy majstersztyk. Pozwala zbierać i łączyć ze sobą informacje, które normalnie dostępne nie są, takie jak emaile, telefony czy SMSy. Wszystko dzięki rozmieszczonym na kilku kontynentach stacjom nasłuchowym. Całość jest przechowywana i przetwarzana w ramach jednego wielkiego systemu do analizy, przez zespoły analityczne, które pracują bez przerwy. Również i ten temat z pewnością podejmę w ramach serii artykułów. W ramach ciekawostki powiem, że najprawdopodobniej także w Polsce jest jedna stacja nasłuchowa (choć mniejszej rangi) systemu Echelon.
Stacja nasłuchowa w ramach systemu Echelon niedaleko Pine Gap w Australii.
Broń “inteligentna”
Trzeci element, o którym jedynie wspomnimy, to wszelkiego rodzaju broń i systemy “inteligentne”. Być może to truizm, ale współcześnie nie wystrzeliwujemy już kul z armat, niczym w średniowieczu, licząc że dotrą do celu po odpowiednim nadaniu im prędkości, kierunku i zwrotu (choć i współcześnie istnieją oczywiście pociski balistyczne, posiadające paraboliczny tor lotu – to jednak zupełnie inna liga).
Pociski kierowane (broń samonaprowadzająca)
Współczesne pociski samonaprowadzające po wskazaniu celu i wystrzeleniu, samodzielnie namierzają obiekt w który mają trafić, aż do eksplozji (która następuje np. w wyniku uderzenia w obiekt). To trzecia generacja pocisków kierowanych (w pierwszej to człowiek sterował zdalnie pociskiem, aż ten doleciał do celu). Polega na tzw. systemie “strzel i zapomnij” (ang. F&F –Fire and Forget). Żołnierz namierza cel, po czym wystrzeliwuje pocisk. Ten – już bez kontaktu z człowiekiem – samodzielnie dąży do obiektu w który ma uderzyć, nawet jeśli zmienia się jego położenie.
Taką technologią są m.in. polskie zestawy przeciwrakietowe Piorun. Co warto podkreślić – są one uważane przez wielu ekspertów za najlepsze systemy tego typu na świecie. Zestawy te są naszpikowane po brzegi elektroniką. Operator może określić tam między innymi z jakim celem będzie miał pocisk do czynienia (np. helikopter, pocisk itd). Inną ciekawą cechą są dwa podstawowe rodzaje eksplozji, jakie mogą nastąpić. Pierwsza to oczywiście eksplozja po uderzeniu w cel i wbiciu się w środek obiektu. Drugi natomiast pomysł, to wybuch w momencie, w którym pocisk będzie przelatywał w odległości paru metrów obok celu. Taki efekt może być wykorzystany, gdy celem są mniejsze obiekty, jak na przykład pociski.
Warto podkreślić, że zestaw posiada swój własny radar, który działa nawet na odległość 8-10 km. Gdy cel (np. helikopter) wleci w zasięg radaru, można go namierzyć. Kiedy przemieści się tak, aby być w zasięgu pocisku – ten wystrzeli automatycznie pędząc ku obiektowi. Poniżej zestrzelenie helikoptera rosyjskiego przez siły Ukraińskie – prawdopodobnie właśnie polskimi “Piorunami”.
https://www.youtube.com/watch?v=x237HLRzDH8
Myśliwce, drony
Ostatnim elementem o którym chcę powiedzieć są siły powietrzne, a konkretnie myśliwce i drony. Samoloty bojowe dawno temu przestały być jedynie latającymi maszynami z pilotem, który jedynie steruje maszyną (w prostym rozumieniu tego zwrotu). Najnowocześniejsze myśliwce, F-35, to tak naprawdę latające komputery. Na temat elektroniki F-35 można napisać osobny materiał. Powiedzmy tutaj jednak, że same samoloty są elementem większego systemu. I to właśnie jako element tego systemu są nadzwyczaj niebezpieczne. Podkreślmy jeden fakt: sam hełm dla pilota F-35 kosztuje ok. 400 000 $. Dzieje się tak, ponieważ to nie tylko samo nakrycie głowy, ale przenośny system komputerowy, który drastycznie zwiększa możliwości pilota tego myśliwca. Tak naprawdę to prawdziwa rozszerzona rzeczywistość. Dzięki wielu czujnikom i kamerom zamontowanym w wielu miejscach samolotu, pilot może dzięki wyświetlaczowi hełmu “oderwać się od maszyny”. Chodzi o to, że obracając głową, nie widzi ścian myśliwca, ale przestrzeń wokół siebie. Patrząc na dół, nie widzi nóg, ale przestrzeń pod myśliwcem. Zupełnie, jakby sam leciał w powietrzu! Oczywiście na ekranie ma dostępne także wszelkie dane, które potrzebne są do monitorowania i sterowania maszyną.
No dobrze, to wszystko pilot. Są też jednak samoloty… bez pilotów. Mowa o dronach, czyli samolotach bezzałogowych. I tutaj mamy tak naprawdę ogromny rynek maszyn wszelkiego rodzaju. Od zwykłych cywilnych dronów, które nakręcą nam sympatyczne wideo, po potężne i zabójcze maszyny. Co ciekawe, Polska także ma pewne osiągnięcia na tym polu. “Oczami” naszej armii są bezzałogowce Flye Eye (widoczne na drugim zdjęciu, na górze artykułu). Są to maszyny, które służą do obserwacji. Flye Eye są bardzo lekkie i żeby wystartować, wystarczy… ręka żołnierza. Nie trzeba żadnych maszyn ani torów startowych.
Podczas agresji Rosji na Ukrainę to właśnie drony były jedną z bardziej pożądanych technologii. Powyżej można obejrzeć wideo, w którym Ukraińscy żołnierze zdalnie sterują samolotem niszcząc system Buk – jeden z poważniejszych atutów wojsk rosyjskich. Takie samoloty są o tyle wygodne, że oczywiście nie niosą ze sobą ryzyka śmierci pilotów, znacznie łatwiej przeszkolić załogę (niż do myśliwców), a ich cena także znacznie odbiega od innych samolotów załogowych.
Przesłanie na koniec
Mam nadzieję, że artykuł Ci się spodobał. Pamiętajmy, że to początek. W dalszych materiałach chciałbym szerzej opowiedzieć o dezinformacji, amerykańskim systemie Maven czy sieci nasłuchowej Echelon. Wojna to zawsze straszna rzecz, ale przygotowując się do niej, zawsze zmniejszamy ryzyko jej wystąpienia. Ze swojej strony dołożę cegiełkę w kontekście poznania współczesnego pola bitwy od strony technologicznej. Jeśli chcesz pozostać w kontakcie – zostaw maila, a ja raz na tydzień napiszę co w Big Datowym świecie słychać. Polub też nasz profil na LinkedIn.
UWAGA! Już niedługo ukaże się pierwszy polski ebook o Big Data. Całkowicie za darmo dla subskrybentów bloga RDF. Zapisując się na newsletter TERAZ – masz niepowtarzalną okazję dostawać kolejne wersje książki i zgłaszać swoje poprawki, a nawet stać się jednym z autorów. Więcej tutaj.
Do tej pory poświęciłem dwa artykuły na dylemat cloud vs on-premise, czyli pytanie o to czy nasza infrastruktura techniczna powinna być serio nasza i stać u nas w serwerowni (albo – jak mój eksperymentalny klasterek – pod biurkiem;-)). Być może powinna zostać uruchomiona na maszynach wirtualnych wykupionych w ramach usług chmurowych? Nie ma jednej dobrej odpowiedzi na te tematy. Dzisiaj chciałbym jednak skomplikować temat jeszcze bardziej. Porozmawiajmy na temat tego czym jest hybrid cloud! No to Big Coffee w dłoń i ruszamy.
Zanim przejdziemy do pojęcia hybrid cloud, wyjaśnijmy pojęcie które będzie nam potrzebne – czyli private cloud, chmura prywatna. Jest to taki rodzaj usługi chmurowej, który odznacza się daleko idącym wydzieleniem zasobów sprzętowych na potrzeby klienta. Może to być zarówno przechowywane w miejscu jego pracy jak i u dostawcy chmurowego. To ostatnie jednak z zastrzeżeniem, że zasoby sprzętowe powinny realnie być oddzielone od reszty.
Stoi to w opozycji do chmury publicznej (ang. public cloud), gdzie dzielimy de facto zasoby z bardzo wieloma innymi użytkownikami (przy czym bazujemy na utworzonych dla nas maszynach wirtualnych lub kontach w konkretnych serwisach). Takie podejście pozwala zachować większe bezpieczeństwo i spełnić wymogi niektórych regulatorów.
Istnieje jeszcze pojęcie Virtual Private Cloud (VPC), czyli wirtualnej chmury prywatnej. Jest to de facto klasyczna chmura publiczna, która po prostu jest oddzielona logicznie od innych “uczestników” chmury (chodzi o tenantów;-)). Moim zdaniem jednak takie podejście ciężko nazywać “prywatnym” – nie spełnia bowiem podstawowych założeń chmury prywatnej, czyli udostepnienia klientowi zasobów “na wyłączność”, dzięki czemu mógłby osiągnąć większą kontrolę i bezpieczeństwo.
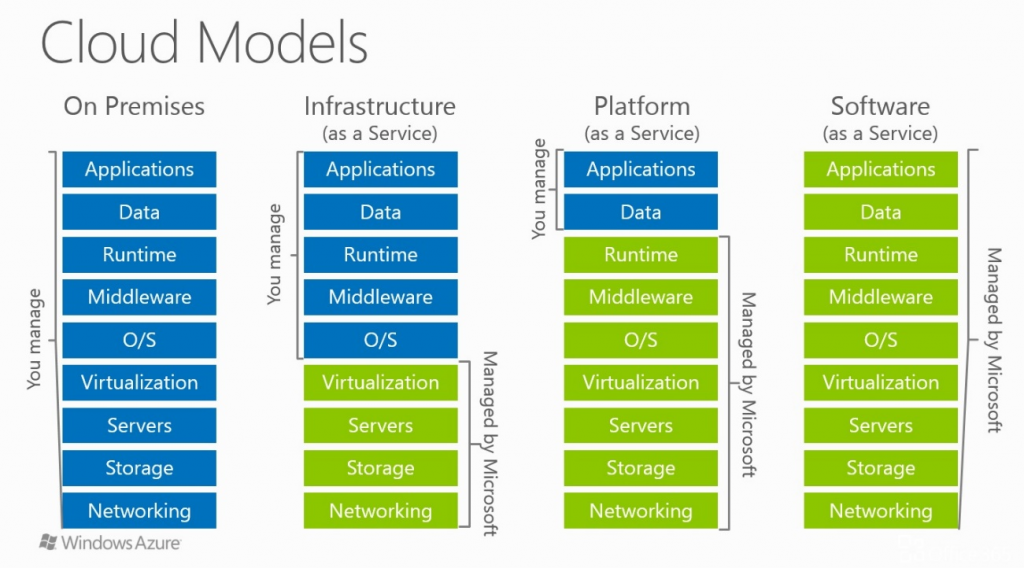
Oczywiście chmura to nie tylko wirtualne maszyny. Powstaje pytanie, jakie usługi może dostarczać dostawca chmurowy w ramach chmuryprywatnej? Odpowiedź poniżej.
Infrastructure as a Service (IaaS) – A więc chmura przejmuje wirtualizację, serwery, storage i networking. Klient natomiast dba o resztę (system operacyjny, middleware, runtime, dane i aplikacje)
Platform as a Service (PaaS) – W tym przypadku po stronie klienta zostają już tylko dane i aplikacje.
Cały podział (razem z on-premise oraz SaaS) poniżej. Grafika pochodzi od Microsoftu i jest używana do opisu Azure.
Hybrid Cloud
Hybryda, jak to hybryda, łączy różne style. W tym przypadku łączymy public cloud z private cloud lub z on-premise. Jeśli używasz kombinacji tych trzech składników w jakiejkolwiek konfiguracji – znaczy, że Twoja infrastruktura jest hybrydowa.
Jakie są zalety rozwiązania hybrydowego? Otóż – przede wszystkim jest to pewna zwinność, elastyczność. Jak już wykazywałem w dwóch artykułach na temat dylematu “cloud vs on-premise” – nie ma jednoznacznie dobrego lub złego rozwiązania. Każde wiąże sięz pewnymi wadami i zaletami. Jeszcze lepiej byłoby stwierdzić, że każde powinno być dostosowane do określonej specyfiki danego problemu. Przykładowo – w rozwiązaniu on-premise problemem może być koszt personelu potrzebnego do serwisowania infrastruktury. Jeśli chodzi o chmurę, w niektorych, szczegolnie wrażliwych przypadkach problemem może być pytanie o to gdzie dokładnie dane są przechowywane (np. wrażliwe dane rządowe).
Decydując się na mix infrastruktury, zachowujemy elastyczność i zwinność. Możemy dostosować wady i zalety rozwiązań tak, aby finalna konstrukcja była idealnie dopasowana do charakterystyki naszego projektu.
Kolejną zaletą hybrid cloud może być także większa efektywność kosztowa. Możemy zauważyć na przykład, że dane chcemy co prawda trzymać na własnych maszynach, jednak przetwarzanie ich może czasami osiągać zawrotne wymagania jeśli chodzi o zasoby. W takiej sytuacji możemy przechowywać je u siebie, natomiast przetwarzać w chmurze, gdzie przydzielanie zasobów może odbywać się niezwykle prosto i dynamicznie.
Podsumowanie
Nie ma jednej prostej odpowiedzi na pytanie “co jest lepsze: chmura czy rozwiązania on-premise?”. Wszystko ma nie tylko swoje wady i zalety, ale i charakterystykę, która musi zostać dopasowana do problemu. Warto jednak pamiętać, że istnieją nie tylko dwie skrajne opcje, ale także rozwiązania hybrydowe. Można dzięki nim manipulować “suwakiem” kosztów, bezpieczeństwa, wygody itd. w inny sposób, niż zastanawiając się jedynie nad podstawowym wyborem.
Z pewnością będziemy kontynuować temat – dziś jedynie zajawka;-). Jeśli nie chcesz przegapić zmian, zapisz się na newsletter i obserwuj nasz profil na LinkedIn. Powodzenia!
Ostatnio miałem okazję rozmawiać z koleżanką, z którą pracuję w jednym projekcie. Być może warto dodać, że jest to projekt medyczno-genetyczny, bo rozmowa zeszła na kwestie etyczne. Zadała niezwykle ważne pytanie: “Czy ludzie pracujący w IT, ale przede wszystkim w Big Data, zdają sobie sprawę z tego w jak ważnej branży pracują? Czy wy myślicie o jakiś aspektach etycznych swojej pracy?”. No cóż – ja myślę od zawsze, kwestia wiary i wychowania. Czy jednak każdy myśli? Zapraszam dzisiaj do innego artykułu niż zwykle. Zaczniemy lekko łatwo i przyjemnie, ale to dopiero początek nowych tematów na blogu RDF;-). Zapraszam serdecznie;-)
Waga Big Data we współczesnym świecie
Dziś Big Data stało się moim zdaniem rdzeniem współczesnego świata. A jeśli jeszcze się nie stało, to zdecydowanie i bezpowrotnie staje się nim. To dzięki Big Data świat idzie do przodu i to dzięki tej branży może się rozwijać.
Ma to jednak swoje mroczne strony. Wszechobecna inwigilacja, przewidywanie każdego aspektu naszego życia, wojna informacyjna (i dezinformacja) na niespotykaną nigdy wcześniej skalę. Uzależnienia całych pokoleń od elektroniki i mediów społecznościowych, oszustwa finansowe, wielkie manipulacje społeczno-polityczne. Mógłbym wymieniać w nieskończoność.
Czy oznacza to, że żyjemy w najbardziej mrocznych czasach w historii? Moim zdaniem nie, choć złe tematy są znacznie, znacznie bardziej “klikalne”. Dobro bardzo często jest ciche, jednak robi ogromną i trwałą robotę. Dzisiaj nieśmiało chciałbym tym artykułem rozpocząć tematykę etyki w Big Data. Zacznijmy od prostego i przyjemnego tematu – a konkretnie kilku przykładów dobrego wykorzystania inteligentnego przetwarzania dużych danych.
3 projekty, które wykorzystują duże dane dla słusznej sprawy
Cloudera co roku wyłania 3 organizacje w ramach swojego konkursu “Data for good”. Oczywiście są to organizacje związane z Clouderą (poprzez korzystanie z ich produktów). Nie zmienia to jednak postaci rzeczy, że mamy tu znakomite przykłady inteligentnego zastosowania obsługi dużych danych do poprawy czegoś w naszym świecie. Zapraszam na krótki opis każdej z organizacji.
Union Bank (Union Bank of Philippines)
Tło całej sprawy to oczywiście COVID, który doprowadził do ciężkiej sytuacji ogromnej rzeszy Filipińczyków. Bardzo wielu z nich musiało coś zrobić, aby przetrwać ciężki czas ledwo wiążąc koniec z końcem. Jednym z podstawowych pomysłów jest pożyczka. Problem? Ponad 70 milionów osób było tam pozbawionych konta bankowego, przez to bank nie miał możliwości prostego sprawdzenia zdolności kredytowej.
Bank Filipiński skorzystał z Cloudera Data Science Workbench. Utworzyli oni ukierunkowany na dane system, który bazując na algorytmach AI pozwolił na szybszą predykcję swoich klientów – ich potencjalnego ryzyka i przydzielanych punktów kredytowych.
W rezultacie wskaźnik akceptacji kredytu wzrósł do 54%. Wzrosły też zyski banku, a co istotniejsze – miliony Filipińczyków mogły przetrwać kryzys. Oczywiście, tak, można zauważyć, że pożyczka nie jest najszczęśliwszym sposobem na utrzymanie się na powierzchni. Można też zwrócić uwagę, że końcem końców chodziło po prostu o zysk.
Tylko, że czasem kredyt to po prostu mniejsze zło. Jeśli zaś chodzi o zysk – cóż. Czy nie jest najlepszą sytuacja, w której zysk oparty jest o świadczenie naprawdę potrzebnych komuś usług?
Keck Medicine of USC
Druga organizacja która otrzymała wyróżnienie w “Data for good” to Keck Medicine of USC. Jest to przedsiębiorstwo medyczne Uniwersytetu Południowej Kalifornii. W tym przypadkiem tło jest chyba jeszcze “cięższe” niż poprzednio. Chodzi mianowicie o uzależnienia od opioidów. Według HHS, w 2019 roku ok 10.1 mln osób (w USA) nadużywało leków opioidowych. W 2018 roku natomiast opioidy były odpowiedzialne za 2/3 zgonów związanych z przedawkowaniem narkotyków.
W Keck Medicine od USC uznali, że spora część uzależnień może wynikać ze złych standardów (lub nie trzymania się dobrych praktyk) przypisywania środków przeciwbólowych przez lekarzy (najczęściej po operacjach lub w przypadku leczenia szczególnie przewlekłych, wyniszczających stanów). W związku z tym utworzony został projekt mający na celu wgląd w praktyki lekarzy. Centralnym punktem był Data Lake, który eliminował potencjalne błędy manualnego zbierania danych. Dodatkowo pozwalał spojrzeć “z lotu ptaka” na dane z całej organizacji.
Dzięki zaawansowanej analityce, naukowcy i lekarze mogą wykrywać najbardziej ryzykowne sytuacje i podjąć odpowiednią reakcję, taką jak edukacja. Dzięki systemowi organizacja może lepiej zadbać o swoich pacjentów, unikając uzależnień zamiast w nie (przypadkowo) wpędzać.
National organisation for rare disorders (National Marrow Donor Program)
Tło to tym razem nowotwory krwi, takie jak białaczka, na które co 10 minut ktoś umiera (tak, wciąż nic wesołego). Wielu z tych ludzi mogłoby żyć, gdyby znaleźli się dawcy na przeszczep szpiku kostnego. Niestety, u 70% osób nie ma odpowiednich osób do przeszczepu wśród najbliższej rodziny.
National Organisation for rare disorders utworzyła National Marrow Donor Program, który ma na celu kojarzenie ze sobą osób potrzebujących i dawców. W ich bazach jest obecnie zarejestrowanych 44 miliony osób. Jak nietrudno się domyślić, sprawne przeszukiwanie bazy to robota dla Big Data. Organizacja razem z Clouderą utworzyła odpowiedni system, dzięki czemu możliwe jest przeszukiwanie milionów rekordów w minutę.
Warto dodać, że na ten moment program pomógł uratować życie ponad 6 600 biorcom szpiku. To absolutnie rewelacyjna wiadomość!
Podsumowanie
Dziś zdecydowanie inny artykuł niż przeważnie. Tak już jest, że Big Data jest medalem, który ma bardzo, bardzo wiele stron. Chciałbym pisać tu o możliwie wielu z nich. Mam nadzieję, że dzisiejszy opis trzech organizacji które robią z danymi coś bardzo, bardzo sensownego, zainspiruje do innego myślenia.
Zostaw komentarz, podaj artykuł dalej i… cóż, koniecznie dołącz do nas na LinkedIn oraz newsletterze. Zostańmy w kontakcie dłużej i razem budujmy polską społeczność Big Data!
Wielokrotnie na tym blogu tłumaczyłem zawiłości Big Data od podstaw (nie oszukujmy się – sam wielokrotnie pisałem to także dla siebie, chcąc usystematyzować wiedzę). Nie tylko technicznie, ale i “z lotu ptaka”, biznesowo. Zawsze żałowałem, że muszę to robić “po łebkach”, w skondensowanej formie, wyrywkowo. Czym innym jest przedstawić jakieś okrojone zagadnienie a czym innym móc wyjaśnić kontekst, zagłębić się, pozwolić sobie na więcej, szerzej, głębiej. Postanowiłem dołączyć do bloga RDF jeden element, który rozwiąże ten problem. I jestem szalenie ciekawy, co o tym sądzisz!
UWAGA! Pierwszy polski ebook o Big Data już dostępny! Zapisz się na listę newslettera i podążaj “Szlakiem Big Data”. Więcej tutaj.
Ebook o Big Data. Po polsku!
No właśnie. Idealnym miejscem aby się zagłębić w temat i przedstawić coś od A do Z jest książka. A najlepiej, żeby była to książka powszechna, dostępna za darmo dla każdego. No więc co? No więc ebook!
Celem ebooka będzie wprowadzenie do branży Big Data. Od historii, filozofii, przez przegląd technologii i architektur. Na słowniczku skończywszy, o. Czy ma wyczerpać temat? Odpowiedź jest oczywista – nie da się go wyczerpać. Ja, po kilku latach naprawdę wytężonej pracy w BD, czuję się… jak kompletny świeżak.
Cel: traktuję Ebooka raczej jako furtkę do świata Big Data. Ja wyjmuję klucz i ją otwieram. Potem Ty dalej już wiesz gdzie iść.
Całość będzie napisana po polsku. RDF powstał po to, żeby szkolić i doradzać tu, w Polsce. Blog jest tego emanacją i podstawowym elementem budowy naszej społeczności Big Data.
Jak będzie zbudowany ebook o Big Data? (Spis Treści)
Przejdźmy do konkretu. Co znajdziesz w ebooku? Pomyślałem o kilku częściach:
Miękkie wprowadzenie do Big Data – czyli opis jak to się wszystko zaczęło (historia) oraz filozofia myślenia w branży. Nie pomijaj tego! Dzięki temu rozdziałowi zobaczysz jak zaczęła toczyć się ta kula śnieżna i… nauczysz się myśleć “po bigdatowemu”.
Opis kluczowych technologii – oczywiście nie będziemy tu robić kursów;-). Poznasz tam zgrubne zestawienie tego jaka technologia służy do jakiego celu. Już bardziej techniczne, ale bez przesady.
Rozważania architektoniczne – wbrew pozorom przyda się nie tylko inżynierom, ale także menedżerom. Do głębszego zrozumienia. Choć, powiedzmy szczerze, Ci ostatni mogą ten rozdział “przelecieć wzrokiem”.
Odwieczny dylemat: cloud czy on-premise? Czyli pytanie o to, czy samodzielnie tworzyć infrastrukturę czy skorzystać z dostawców.
Słowniczek – gdyby coś w trakcie było niezbyt zrozumiałe. Tylko nie zakuwaj za dużo!
Jestem jednak otwarty na różne sugestie. Mogę to zarówno pociąć jak i dobudować.
Zdjęcie bardzo poglądowe;-) Okładkę ebooka o Big Data też zaprojektujemy wspólnie!
UPDATE! 20.07.2022 – premiera ebooka. Dołącz do newslettera, aby otrzymać go za darmo.
Włącz się w tworzenie!
No właśnie – otwarty na sugestie. Twoje. Mam przynajmniej taką nadzieję. Ebook będzie znacznie bardziej wartościowy jeśli dowiem się od Was co was nurtuje, czego nie rozumiecie. A może co było trudne na początkowym etapie rozwoju? Każda uwaga jest cenna.
Jest jednak mały “haczyk”. Chcę, żebyśmy tworzyli jedno naprawdę spójne środowisko. Najlepiej bez pośredników w postaci mediów społecznościowych (w końcu pracuję w Big Data! Wiem jak to działa;-)). W związku z tym cały proces twórczy będzie opierał się o newsletter.
W ramach newslettera będę komunikował znacznie, znacznie więcej niż dotychczas.
Przez newsletter dostaniesz każdy kolejny kawałek skończonego ebooka.
Będziesz mógł odpowiedzieć na konkretny email i zasugerować zmiany. Jestem otwarty na rozmowę, a nawet czekam na nią!
Ebook będzie później dostępny dla każdego newsletterowicza. Pomagając więc tworzyć książkę, w sposób najpełniejszy wspierasz społeczność. Razem możemy zbudować coś, od czego wyjdzie każdy nowy Inżynier Big Data i menedżer BigDato-świadomy (:D).
Aby tak się stało, zapisz się na newsletter już teraz:
Podsumowanie – jak włączyć się w proces twórczy?
No więc, podsumowując: zaczynam (już zacząłem;-)) tworzenie ebooka o Big Data. Pierwszy taki na polskim rynku. Będzie w całości za darmo dla newsletterowiczów RDF. Co więcej – jeśli jesteś (lub zostaniesz) subskrybentem, możesz włączyć się w proces twórczy:
Każdorazowo gdy skończę jakiś większy fragment, wyślę Ci go do sprawdzenia.
Ponadto możesz odpowiadać na emaile i podpowiadać jakie poprawki chcesz wprowadzić. Zarówno te drobne (jeszcze jedna technologia?) jak i te fundamentalne (nowy dział?).
Jestem głęboko przekonany, że razem zbudujemy coś wyjątkowego! Dołącz także do naszego LinkedIn i podaj artykuł znajomym, którzy mogą być zainteresowani;-).
![Jak zaindeksować dane w Solr z użyciem Spark? [wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/07/grafika-blog.png "Jak zaindeksować dane w Solr z użyciem Spark? [wideo]")
![Jak szybko utworzyć kolekcję w Solr? [wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/07/BLOG-yt-Zbuduj-configset-1.png "Jak szybko utworzyć kolekcję w Solr? [wideo]")


")



")




")




")


