
Czym jest “Personal Knowledge Management”? Jak podejść do budowania swojej własnej bazy wiedzy? O tym wszystkim w dzisiejszym artykule Wojtka Zdziebkowskiego – członka newslettera “Na Szlaku Big Data”.
Jeśli szukasz sposobu, aby gromadzona wiedza nie była marnowana, to jesteś w znakomitym miejscu!
O co w ogóle chodzi z PKM?!
Personal Knowledge Management – bo takie jest rozwinięcie tego skrótu – to system zbierania, organizowania i przetwarzania informacji. Założeniem jest stworzenie swojej osobistej bazy wiedzy w celu sprawniejszego wyszukiwania i wykorzystania zebranych wcześniej informacji. Ciężko stwierdzić, kiedy narodziło się pojęcie Osobistej Bazy Wiedzy. Jednak dziś w erze komputeryzacji ludzkość jest wręcz bombardowana tysiącami różnych wiadomości, natomiast wiedza nigdy nie była tak łatwo dostępna.
Dziś od materiałów naukowych, artykułów, kursów itd. dzieli nas kilka kliknięć myszką, czasami również większa bądź mniejsza kwota. W takich czasach, proces prostego zbierania oraz przetwarzania informacji, lub narzędzia, żeby ten proces stał się przystępny są na wagę złota. W roku 2014 z nowoczesną wersją PKM wyszedł do świata ekspert od produktywności, Tiago Forte.
Koncepcja promowana przez Tiago nosi nazwę Second Brain (drugi mózg), czyli system rozszerzający nasz fizyczny umysł o dodatkową pojemność. Założeniem jest posiadanie systemu cyfrowego lub analogowego, gdzie będziemy zbierać i organizować informacje, aby móc je w dowolnym momencie bez problemu wykorzystać. Second brain uzupełnia nasz umysł i daje łatwy dostęp do odpowiednio odrobionych informacji, bez strachu, że w najbardziej potrzebnym momencie będziemy mieć pustkę w głowie. W całej zawiłości chodzi głównie o możliwość prostego przetwarzania informacji, a następnie łączenia je w logiczne powiązania w dowolnym momencie.
Prekursorem systemu zarządzania wiedzą był natomiast Niklas Luhmann, autor ponad 70 książek i 400 artykułów. System opracowany przez Luhmanna nosi nazwę Zettelkasten i pomógł twórcy, nie tyle robić dobre notatki, co przyswoić całą zgromadzoną wiedzę. W końcu to jest chyba najważniejsze? Nie ilość zgromadzonej wiedzy, ale możliwość swobodnego korzystania z niej.
Niklas Luhmann notował wszystkie swoje idee i pomysły na pojedynczych kartkach papieru i nadawał im identyfikatory. Każda notatka poza swoim identyfikatorem miała też identyfikator wszystkich notatek spokrewnionych. A te grupy połączonych notatek trzymane były blisko siebie, żeby zawsze mieć do nich dostęp. Czasy Luhmanna były jeszcze mocno analogowe, w sieci można zobaczyć nagranie, na którym autor prezentuje swój system zettelkasten, wygląda to co najmniej przerażająco… Dzisiaj to wszystko można robić cyfrowo, bez setek szafek i milionów kartek, więc może warto z tego skorzystać.

Niklas Luhmann wraz ze swoim archiwum Zettelkasten.
Źródło: https://bilder.deutschlandfunk.de
Czy Zettelkasten to to samo co second brain? Nie, ale są to bardzo powiązane tematy. Zettelkasten ma swoje konkretne zasady, a Second Brain to pojęcie bardziej ogólne i elastyczne, ale też jakieś zasady posiada, o nich jednak później.
Gdzie podział się mój system?
Robię notatki zbieram informacje i ciekawe materiały, po co mi w ogóle system?
To teraz się zastanów:
- ile razy wracałeś do swoich notatek?
- Czy wiesz, gdzie co zapisałeś?
- A ile masz otwartych kart w przeglądarce z czymś ciekawym na potem?
Ja niechlubnie się przyznam, że prawie 70, ale dopiero pracuję nad moim second brain. To jest właśnie problem, którego może na pierwszy rzut oka się nie dostrzega. Dziesiątki kart na potem, setki porozrzucanych notatek w różnych miejscach czy tysiące pozaginanych rogów kartek albo podkreśleń w książkach. Tylko dlatego, że coś wydaje Ci się ciekawe podejmujesz pierwszy krok, czyli zaznaczasz i zostawiasz na potem.
W końcu po długim czasie przychodzi “potem”. Raz na pół roku nudzisz się tak bardzo, że zabierasz się za porządki. Bierzesz w rękę pierwszą kartkę, odpalasz jedną z otwartych zakładek i patrzysz myśląc nieśmiało “po co ja to napisałem/otwarłem, eee niepotrzebne”. W ten sposób wyrzucasz do kosza kilka kartek i zamykasz parę otwartych kart, a przy okazji te minuty a może godziny, które w skali roku wyrzucasz do kosza. Nie potrafisz sobie przypomnieć, jaki miałeś pomysł na to wszystko wtedy, kiedy zdecydowałeś się zostawić te informacje na potem.
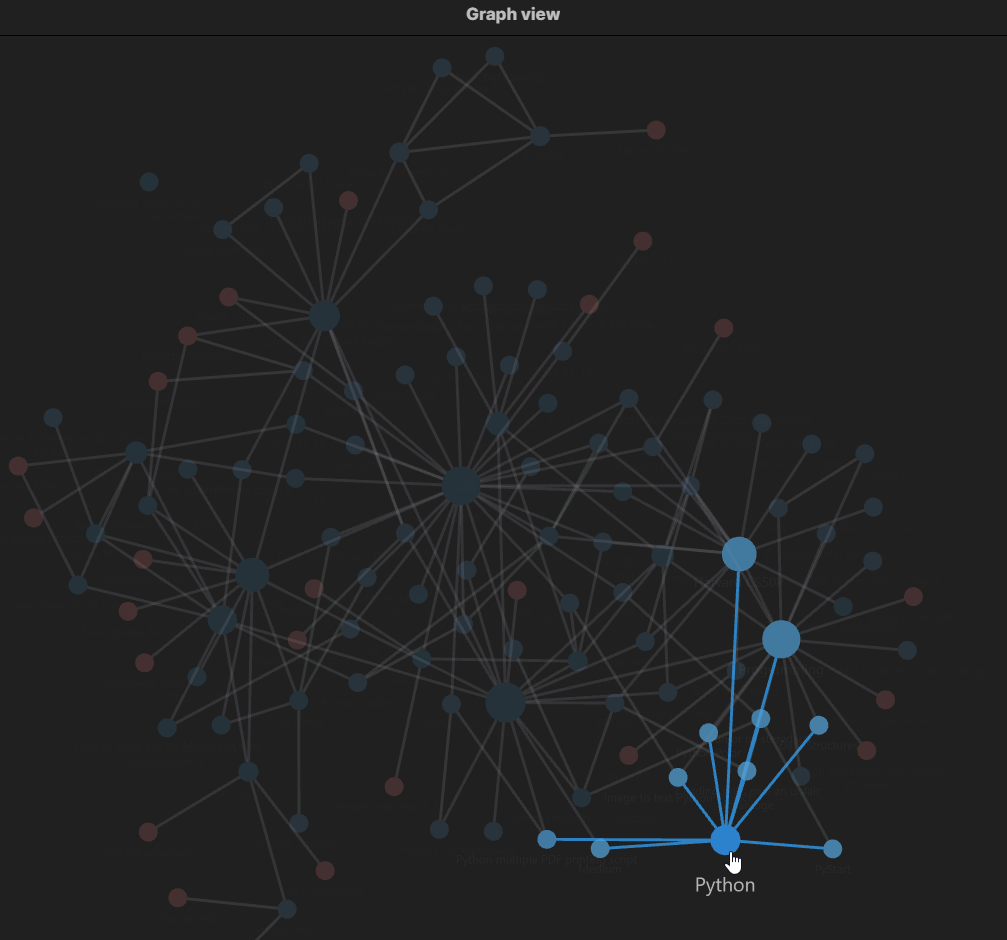
A co, jeśli masz system? Zaznaczasz to co Cię interesuje, otwierasz zeszyt, telefon, komputer cokolwiek. Odpalasz odpowiednią aplikacje albo chwytasz za długopis. Masz system, więc wiesz, jak powinna wyglądać struktura konkretnej notatki. Ba, masz nawet szablon i to nie jeden! Pierwszy na ciekawostki, kolejny na rzeczy zabawne, inny na rzeczy, których chcesz się nauczyć. A może tylko jeden? Może tak, to zależy od Ciebie, bo to Twój system.
Więc otwierasz swój template i cyk, tytuł, źródło, kategoria, na koniec treść tego co cię zainteresowało. Może skopiowana do dalszej obróbki, a może już zredagowana. Trwało to chwile, ale teraz posiadasz notatkę z przypisaniem do kategorii, ze źródłem, do którego możesz wrócić, może z połączeniem do jakiejś konkretnej grupy notatek. Co Ci to daje? Jeśli będziesz potrzebował jakiejś informacji najpierw otworzysz swoją bazę wiedzy. Masz tam już zapisane zagadnienie, którego szukasz.
Najprawdopodobniej, taki jest cel, jest to już wiedza obrobiona przez Ciebie. Nie musisz przebijać się przez ściany artykułów ani pozycje wyszukiwarki. Już posiadasz to co potrzebujesz i możesz to łatwo znaleźć, na pewno dużo łatwiej niż w dziesiątkach otwartych kart na potem, albo stosie notatek. I co dalej? Bierzesz to co chcesz i idziesz z tym w świat!
Czas na zasady…
Wspominałem, że koncepcja second brain ma swoje zasady. Może jeszcze tego nie wiesz, ale wszystkie zdążyłeś już poznać. W wersji oryginalnej noszą zgrabny skrót CODE, czyli:
- capture – Zbierasz informacje
- organize – Przetwarzasz je i organizujesz, w swojej bazie chcesz tylko to co jest najważniejsze, żadnych śmieci
- distill – Przychodzi potrzeba, więc szukasz i wyciągasz oczekiwaną informację
- express – Cytując zdanie z poprzedniego akapitu: “Bierzesz to co chcesz i idziesz z tym w świat!”. Czyli masz już informację, której potrzebowałeś i ją wykorzystujesz.
To są właśnie główne zasady osobistej bazy wiedzy.
Zaprojektuj swoją mapę!
Na koniec tej części przybliżymy sobie dwie dodatkowe koncepcje pozwalające lepiej organizować swoje notatki. Chodzi o metodę PARA i MOC.
PARA jest metodą organizacji bazy wiedzy opracowaną przez wspomnianego wcześniej prekursora koncepcji second brain – Tiago Forte, polega na podziale notatek na cztery kategorie:
- Projekty (projects) – listy zadań powiązane z celami i terminami.
- Obszary odpowiedzialności (area of responsibilities) – obszary twoich odpowiedzialności np. rodzicielstwo, finanse, gotowanie
- Źródła (resources) – notatki związane z zainteresowaniami
- Archiwum (archive) – wszystkie nieużywane rzeczy z poprzednich kategorii
Istotą metody PARA jest proste, szybkie i uniwersalne kategoryzowanie notatek. Ponadto autor forsuje podejście projektowe do każdego zadania lub problemu jaki napotkasz. Na czym to polega? Na rozbiciu każdego zadania na jak najmniejsze mierzalne kroki, aby unikać zabierania się do przedsięwzięć, które nas przytłoczą.
Dla przykładu chcesz się nauczyć angielskiego. Jak do tego podejdziesz? Możesz wziąć listę zadań i wpisać punkt: nauczę się angielskiego. Kiedy będziesz wiedzieć, że cel został zrealizowany? Może dasz sobie spokój po tygodniu, kiedy nauczysz się przedstawiać, bo stwierdzisz, że to jest to co chciałeś umieć. Może wrócisz do niego za dziesięć lat będąc na granicy perfekcji, mając świadomość, że ciągle możesz iść krok dalej.
Drugim sposobem jest rozbicie nauki angielskiego na mniejsze zadania, najlepiej z terminami, aby móc monitorować swój postęp. Czyli bierzesz kartkę, notes lub otwierasz aplikacje w telefonie i piszesz: nauczę się Present Simple w dwa tygodnie, następnie nauczę się 20 słów do końca miesiąca i do końca przyszłego miesiąca nauczę się Present Continuous. Główną zaletą drugiego podejścia jest to, że masz przed sobą małe mierzalne kroki i widzisz swój postęp w realizacji celu. Dodatkowo rozbijając zadanie na mniejsze kroki, tworzysz sobie prosty plan działania. Dzięki temu wiesz, co jest jeszcze przed Tobą, a co już za Tobą.
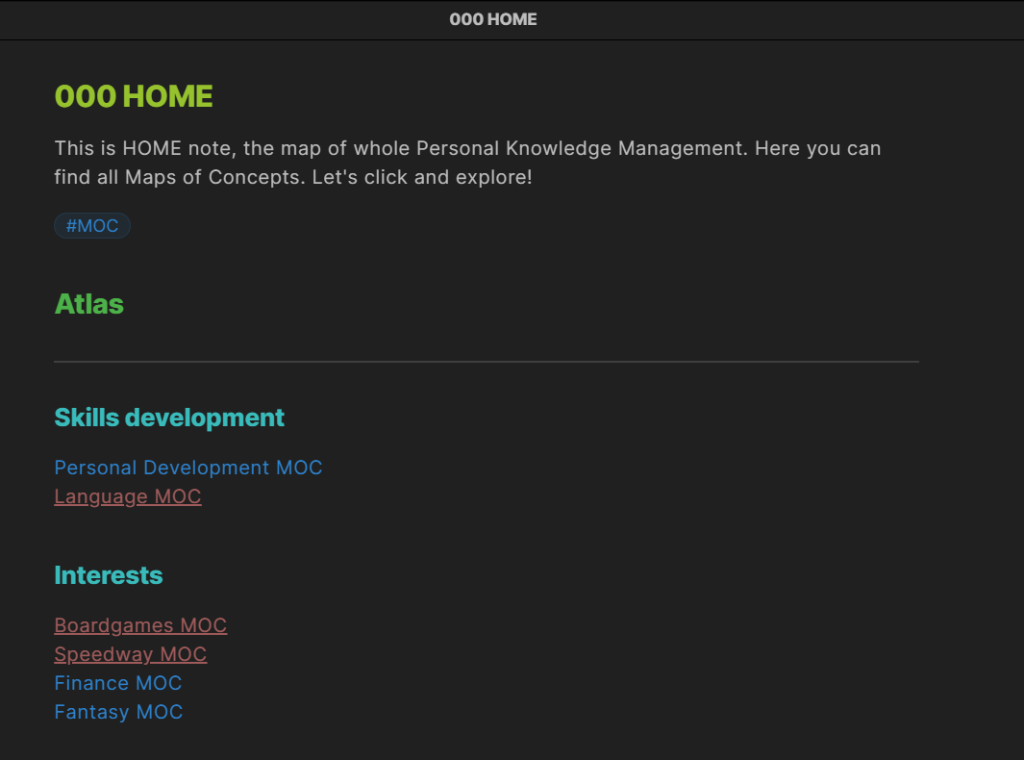
Kolejną i osobiście moją ulubioną formą tworzenia notatek jest tak zwany Map of content w skrócie MOC. Mówi się, że są trzy typy twórców notatek: Bibliotekarz, Architekt i Ogrodnik. Bibliotekarz to osoba zbierająca różne informacje. Architekt jest to osoba, która wszystko planuje. Natomiast Ogrodnik jest to osoba dbająca, aby jej notatki się rozrastały.
Właśnie notatkowi ogrodnicy stworzyli koncepcje MOC, która jest prosta, przejrzysta i pozwala na nieograniczony rozrost Twoich notatek, co może, ale nie musi być zgubne. Także staraj się zawsze zachować zdrowy rozsądek. Jak już wspomniałem koncepcja ta jest prosta, a nawet bardzo prosta. Jednak uważam, że nadaje się głównie do stosowania cyfrowo, a nie analogowo. Najważniejszym elementem “mapy kontentu” jest, jak sama nazwa mówi – mapa.
W założeniu każdy obszar zainteresowań powinien mieć swoją mapę, czyli taką notatkę tytułową. W tej mapie znajdziemy wszystkie powiązane z konkretnym tematem materiały. Dla przykładu interesuje nas gotowanie, więc tworzymy MOC Gotowanie. Każdą tworzoną notatkę z tematu gotowania linkujemy pośrednio lub bezpośrednio z naszą główną notatką MOC Gotowanie. Teraz pewnie myślisz “o gościu odkrył co to jest folder”.
Nic bardziej mylnego, całą przewagą mapy nad folderem jest to, że notatka nie musi być przypisana tylko do jednej mapy. Może być przypisana do każdej mapy, z którą coś ją łączy. Tworzymy notatkę o garnkach ze stali nierdzewnej i wrzucamy ją do naszej mapy MOC Gotowanie. Jesteśmy jednak wielkimi fanami materiałoznawstwa i posiadamy też mapę MOC Materiały. Tam też ląduje link do naszej notatki.
Dlatego też lepiej sprawdzi się forma cyfrowa niż analogowa, bo nie będziemy przecież kserowali notatki, żeby umieścić ją w dwóch mapach. W wielu aplikacjach do robienia notatek znajdziemy już opcję linkowania. Ponadto dobrą praktyką jest stworzenie czegoś w rodzaju mapy map, jakkolwiek to brzmi. Czyli tworzymy główną notatkę np. HOME i linkujemy do niej wszystkie nasze mapy. Dzięki temu nawigacja po naszej bazie jest prostsza i bardziej intuicyjna.
Obie koncepcje w większym lub mniejszym stopniu można ze sobą łączyć. Najważniejsze jest jednak tworzenie użytecznych notatek, dlatego idź i twórz! Nie bój się eksperymentować, łączyć w całość różne metody i tworzyć swoje własne zasady. Twoje notatki powinny służyć przede wszystkim Tobie z przyszłości.
Już niedługo ciąg dalszy…
Zostań na dłużej z Riotech Data Factory! Dołącz do newslettera “Na Szlaku Big Data”, żeby kompleksowo eksplorować świat wielkich danych. Jak widać, Big Data to nie tylko programowanie, ale także umiejętności “miękkie”, takie jak efektywna nauka, czy katologowanie swojej własnej wiedzy!
Już niebawem ciąg dalszy artykułów o bazie wiedzy. Dołącz do newslettera, aby nie przegapić!
Źródła i przydatne linki:
https://fortelabs.com/blog/the-4-levels-of-personal-knowledge-management/
https://www.buildingasecondbrain.com/foundation
https://fortelabs.com/blog/basboverview/
https://obsidian.rocks/maps-of-content-effortless-organization-for-notes/


![“Fundament Apache Spark” już dostępny! Jak wygląda pierwszy polski kurs o Sparku? [Wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2023/01/ikona.png "“Fundament Apache Spark” już dostępny! Jak wygląda pierwszy polski kurs o Sparku? [Wideo]")
![Boże Narodzenie w liczbach – jacy jesteśmy na święta? (Big Data Po Polsku) [Audio]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/12/YouTube-podcast9.jpeg "Boże Narodzenie w liczbach – jacy jesteśmy na święta? (Big Data Po Polsku) [Audio]")
![Społeczeństwo danych – jak zmieniają nas technologie XXI w? (Big Data Po Polsku) [Audio]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/11/YouTube-podcast8.jpeg "Społeczeństwo danych – jak zmieniają nas technologie XXI w? (Big Data Po Polsku) [Audio]")
![Jak wygląda praca Inżyniera Big Data? [wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/11/yt.jpeg "Jak wygląda praca Inżyniera Big Data? [wideo]")
![Jak zostać ekspertem? (Big Data Po Polsku) [Audio]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/11/YouTube-podcast7.jpeg "Jak zostać ekspertem? (Big Data Po Polsku) [Audio]")
![Nie zaczynaj od chmury! O przewagach rozwiązań on-premise. (Big Data Po Polsku) [Audio]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/10/YouTube-podcast6.jpeg "Nie zaczynaj od chmury! O przewagach rozwiązań on-premise. (Big Data Po Polsku) [Audio]")

