Twój partner w świecie Big Data/AI – raporty, analizy, przemyślenia
Techniczne
Znajdujesz się w raju dla ekspertów Big Data/AI;-). Poznasz tu materiały, w których poruszane są kwestie stricte techniczne. Zagwozdki dotyczące konkretnych technologii, optymalizacja wydajności, dobre praktyki, case studies – wszystko co pomaga nam stawać się lepszymi inżynierami BD.
Ostatnio zdałem sobie sprawę, że kiedy jadę autem, marnuję czas. Zamiast słuchać bzdetów w aucie, mogę po prostu podzielić się z Wami czymś sensownym. No więc pierwszy eksperyment! Zapiąłem smartfona i popłynąłem z tematem “jak ogarnąć architekturę systemu Big Data?”. Wszak często to naprawdę złożone tematy, trudna i skomplikowana architektura. Wiele komponentów i mechanizmów.
Architektura Big Data to oczywiście złożona kwestia i nie da się w 8 minut wyczerpać tematu. Mam jednak nadzieję, że wyjaśniłem sensownie to o co mi chodziło;-).
Jak ugryźć złożoność? Architektura Big Data z lotu ptaka
Poniżej wklejam wideo i zapraszam do subskrybowania kanału RDF na YouTube;-)
Kolejne wideo poradnikowe dotyczy Sparka. Pokazuję, w jaki sposób od A do Z uruchomić aplikację (job) sparkową na serwerze (na klastrze). Kod jest już gotowy i znajdziesz go w repozytorium;-). Jeśli zechcesz zagłębić się w kwestie techniczne, tutaj znajdziesz artykuł na temat spark submit.
How to index data in Solr with Apache Spark?
Poniżej wklejam wideo i zapraszam do subskrybowania kanału RDF na YouTube;-)
Po EKSTREMALNYM sukcesie poradnikowego wideo na temat tworzenia kolekcji w Solr (prawie 50 wyświetleń w pierwszych dniach. SZOK. Hollywood stuka puka do drzwi!), pociągnąłem temat. Ciągle poradnikowo, ciągle Solr. Tym razem jednak zaindeksujemy więcej dokumentów niż tradycyjnie robi się to w tutorialach. I zrobimy to znacznie przyjemniej, niż robi się to zwykle w tutorialach;-). Czas zaprzęgnąć Sparka do indeksacji danych w Solr!
How to index data in Solr with Apache Spark?
Poniżej wklejam wideo i zapraszam do subskrybowania kanału RDF na YouTube;-)
Iii stało się! Wreszcie przemogłem się (i znalazłem czas w szkoleniowym młynie) żeby nagrać pierwsze RDFowe wideo. Liczę że od tej pory sukcesywnie będziemy przesuwali się także i na tym polu;-). Treści wideo będą przeróżne, ale na pierwszy ogień idzie typowy poradnik “how-to”.
Inauguracje weźmie na siebie Solr, a konkretnie tworzenie kolekcji. Jest to temat zdecydowanie nieprosty, a przede wszystkim – nieintuicyjny do bólu. Szczególnie, jeśli ktoś wie jak to się robi w Elastic Search. Smacznego!
How to create solr collection?
Poniżej wklejam wideo i zapraszam do subskrybowania kanału RDF na YouTube;-)
USA kojarzą nam się z potęgą zarówno technologiczną jak i militarną. Nie bez powodu. To tutaj zrodziła się branża Big Data. To ten kraj ma najpotężniejszą armię na świecie. Pytanie jednak, czy zawsze te dwie rzeczy idą w parze? Dziś poznamy jeden z przykładów tego jak Big Data i sztuczna inteligencja (AI) wykorzystywane są w amerykańskiej armii. Bierzmy więc kubek żołnierskiej czarnej kawy w dłoń i przejdźmy przez drugi odcinek z serii “Big Data na wojnie”!
Drony, dominacja USA i… absurdy rodem z parodii państwowości
Hegemonia zobowiązuje
USA to nie jest “normalny kraj”. Nie, nie mam na myśli tego, że to stan umysłu. Nie należy jednak porównywać jakiegokolwiek państwa do Amerykanów z jednego prostego powodu: Stany Zjednoczone rządzą światem. To imperium, które ustawiło pod siebie cały glob. Teraz co prawda ulega to pewnym zmianom, ale to rozmowa na inny artykuł. Na innym blogu;-).
Skutkuje to nie tylko profitami, ale i zobowiązaniami. Podstawowym zobowiązaniem jest to, że Amerykanie muszą militarnie “obstawiać” cały świat. Oznacza to nie tylko obecność sił zbrojnych na określonych terenach, ale także stały monitoring miejsc, w których Hegemon ma swoje interesy. W siłach zbrojnych Stanów Zjednoczonych służy ok. 1.3 mln żołnierzy nie licząc rezerwistów oraz Gwardii Narodowej (mniej więcej odpowiednik naszych Wojsko Obrony Terytorialnej). Każdy żołnierz kosztuje swoje i jego wyszkolenie oraz – co jasne – życie, jest na wagę złota.
Z tego powodu wojska amerykańskie od dłuższego czasu prowadzą wiele bardzo intensywnych prac badawczych (których skutkiem jest m.in. Internet) mających na celu rozwój nowoczesnych technologii czy robotyzację pola walki. Jednym ze skutków takich prac są drony. To samoloty bezzałogowe, które nie tylko są tańsze w produkcji od myśliwców i prostsze w użyciu. Co najważniejsze – pilot drona nie jest bezpośrednio narażony, siedzi w ciepłym i przyjemnym zakątku, sterując przez komputer swoją maszyną.
Monitoring najważniejszych miejsc na świecie
To właśnie drony są wykorzystywane do uderzenia z powietrza. Pełnią jednak także inną rolę – zwiadowczą. Dzięki nim można “podglądać” w bardzo solidnej jakości wiele miejsc na Ziemi. Poza stałym monitoringiem, zapisy z latających czujników stanowią znakomity materiał do analizy wstecznej. Jeśli dochodzi do jakiegoś ataku terrorystycznego czy podejrzanych ruchów, można bez problemu odszukać nagranie z tamtego momentu i przeanalizować minuta po minucie, sekunda po sekundzie.
Także Polska może pochwalić się sukcesami na rynku dronowym. Widoczny na zdjęciu FlyEye to polski samolot bezzałogowy służący celom zwiadowczym. Niezwykle popularny na wojnie za naszą wschodnią granicą – w służbie armii Ukraińskiej oczywiście.
Pentagon wydał dziesiątki miliardów dolarów na tego typu systemu obserwacji. Dzięki temu, jeśli ktokolwiek podłożył bombę, można po prostu przewinąć wideo do tyłu i sprawdzić kto to był, dokąd poszedł itd. Tego typu system obserwacji to fascynujący pomysł, dający gigantyczne możliwości analityczne. Skoro więc mamy całą flotę dronów uzbrojonych w czujniki, nadających do nas obrazy wideo, co jest oczywistym kolejnym krokiem? Warto wskazać, że pojedyncze drony z tego typu czujnikami gromadzą wiele terabajtów danych… dziennie.
W związku z powyższym nie będzie chyba zbyt kontrowersyjne stwierdzenie, że oczywistym jest zbudowanie systemu który tego typu dane kataloguje i automatycznie analizuje prawda?
Biurokratyczne absurdy także za oceanem
Otóż, jak się okazuje – niekoniecznie. Żaden inteligentny system nie powstał. Co prawda był pewien storage, w którym umieszczano nagrane wideo. Znakomita większość jednak… nigdy nie była przeanalizowana. Jak to się mogło stać? Otóż, rozwiązaniem według DoD (Departamentu Obrony – ang. Department of Defense)wcale nie było zbudowanie inteligentnego systemu analitycznego, ale… utworzenie odpowiednio dużego sztabu ludzi. Ludzi, którzy siedzieli przez 24h na dobę (praca zmianowa), patrzyli w ekran i… liczyli. Liczyli auta, ludzi, budynki itd. Następnie sprawnie tego typu dane przepisywali do… excela lub powerpointa i wysyłali dalej.
Brzmi absurdalnie? Takie właśnie jest! I dzieje się to w Stanach Zjednoczonych Ameryki. Nie w małej firmie pod Białymstokiem, ale w najpotężniejszym kraju na świecie, o ugruntowanej państwowości
Project Maven, czyli jak wynieść organizację na wyższy poziom
Aby powyższy stan rzeczy zakończyć, podjęta została decyzja o zbudowaniu “Project Maven”. To repozytorium, które miało stać się systemem do inteligentnej analizy materiałów z czujników bezzałogowców. To jednak nie jest jedyna rola Mavena. Projekt ten miał w zamierzeniu stać się przyczółkiem dla metodycznego wykorzystania Big Data oraz sztucznej inteligencji (AI) w armii amerykańskiej. Chociaż USA są synonimem postępu i nowoczesności, w wojsku ciągle wiele elementów działało jak podczas II Wojny Światowej. Wpuszczenie systemów przetwarzania dużych danych miało to zmienić.
Maven skupia się na analizie danych wideo z różnych platform dronowych:
Scan Eagle
MQ-1C Gray Eagle
MQ-9 Reaper.
Podstawowym celem Projektu miała być automatyczna identyfikacja obiektów rejestrowanych przez kamery Dronów. Co warte podkreślenia – w tworzenie całego systemu zaangażowane były podmioty prywatne. Jedną z firm tworzących repozytorium było Google. Ciężko o bardziej trafną decyzję – to od tej firmy zaczęła się “prawdziwa Big Data” i spod jej skrzydeł wyszły niezwykle istotne technologie, będące właściwie fundamentem branży. W związku z ujawnieniem wewnątrz Google współpracy z Pentagonem, wybuchł protest pracowników. Ci rządali wycofania się z procesu, tłumacząc to niezgodnością z linią etyczną firmy i ich hasłem przewodnim “Don’t be evil” (nie bądź zły). To jednak zupełnie na marginesie.
Projekt Maven miał rozwiązać jeszcze jeden problem: biurokrację. Dotychczas jedynie ludzkie oko (i oczywiście mózg) były wyznacznikami tego czy cel widziany przez bezzałogowiec jest wrogiem, czy nie. W związku z tragicznymi pomyłkami, procedury dotyczące możliwości podjęcia ostrzału bardzo mocno spowolniły czas między obserwacją, a ogniem. Znakomicie wyuczone mechanizmy mają na celu przyspieszenie całego procesu.
Jak mógłby wyglądać “Project Maven”?
Na końcu proponuję zabawę. Skoro jesteśmy na blogu stricte poświęconym Big Data – spróbujmy zastanowić się jak mogłoby wyglądać Maven pod kątem technicznym, a przynajmniej architektonicznym – w najbardziej ogólnym rozumieniu tego słowa. Nie próbujemy domyślić się jak było to robione w Pentagonie, ale jak analogiczny system mógłby być zbudowany u nas, na potrzeby Wojska Polskiego.
Nasza specyfika jest oczywiście zupełnie inna. Nie musimy obserwować połowy świata. Załóżmy jednak, że chcemy bardzo precyzyjnie monitorować całą granicę wschodnią i otrzymywać alerty, jeśli coś niewłaściwego się tam dzieje. Ponieważ nasza granica jest dość długa, przygotujemy system który automatycznie powiadamia o podejrzanych ruchach oraz pozwala przeszukiwać informacje o aktualnym stanie oraz stanie z określonego momentu w historii.
Przykładowy slajd wysłany do zatwierdzenia w procesie uczenia oryginalnego projektu Maven.
Zastanówmy się więc jak to może wyglądać.
Storage – tak nazwijmy ogólną część, w której składujemy dane.
Moduł do uczenia
System alertów
Moduł do analizy
Jaka infrastruktura?
Zacznijmy od bardzo ważnej kwestii! Konkretnie od powiedzenia sobie wprost: taki system absolutnie nie może być zbudowany z wykorzystaniem rozwiązań chmurowych. Być może to kontrowersyjna teza, ale obecnie najwięksi dostawcy to firmy zagraniczne. W przypadku tego typu produktu podstawową cechą musi być bezpieczeństwo. Nie owijając w bawełnę – nie tylko bezpieczeństwo przed włamaniami rosyjskich hakerów. To są dane, które po prostu nie mogą być zależne od zagranicznej infrastruktury (nawet jeśli jest położona na terenie Polski). Rozumiem, że wiele osób może mieć odmienne zdanie, szanuję to, ale się z nim nie zgadzam. Zakładam więc budowę systemu na własnej infrastrukturze (on-premise).
Nic nie stoi jednak na przeszkodzie, abyś Ty rozpisał/a podobną architekturę dla rozwiązań chmurowych;-). Napisz i wyślij, a ja z pewnością opublikuję.
Storage
W tym miejscu musimy się zastanowić w jaki sposób składować dane. To tutaj będą trafiać w pierwszym kroku, ale nie tylko. Oczywiście taki moduł może składać się z więcej niż jednej technologii do składowania danych!
Co dokładnie moglibyśmy tutaj umieścić? Zacznijmy od pierwszej przestrzeni, gdzie lądować miałyby surowe dane. Proponuję tutaj jedną z dwóch technologii:
W takim miejscu możemy przede wszystkim składować wszystkie możliwe pliki wideo, które będą przesyłane przez drony. Następnie pliki te byłyby odczytywane i zapisywane do którejś bazy danych w formie metadanych (np. jakie obiekty są w jakim momencie nagrania, co to za samolot itd). Może to być HBase (który współgra zarówno z HDFS jak i z Ozone).
Moduł do uczenia
Oczywiście w “naszym Mavenie” musimy mieć modele, dzięki którym będziemy mogli rozpoznawać konkretne obiekty, ludzi, broń itd. Aby to zrobić, musimy utworzyć moduł uczący. W jego ramach możemy zrobić tak jak w amerykańskim odpowiedniku – najpierw trzeba przejrzeć bardzo bardzo wiele materiałów, a następnie otagować co tam się znajduje, jak to wygląda itd. W kolejnym etapie utworzymy klasyczny zbiór uczący i testowy, a następnie wytrenujemy konkretne modele dzięki uczeniu nadzorowanemu (co możemy zrobić dzięki otagowanym materiałom).
Jakie technologie możemy tutaj zastosować? Możemy pójść w stronę wykorzystania bibliotek pythonowych – i wtedy próbować swoich sił z TensorFlow. Możemy także popracować z Apache Spark ML i deep learning, który oferują na coraz lepszym poziomie jego twórcy.
System Alertów
Następny moduł który powinniśmy omówić to system alertów. Chodzi o to, aby nasi żołnierze z Wojsk Obrony Cyberprzestrzeni nie ślęczeli przed widokami przekazywanymi z każdego z dronów, ale by byli powiadamiani o potencjalnych anomaliach zawczasu przez zautomatyzowany system.
Tutaj moja propozycja jest prosta:
Kafka, na którą trafiają obrazy wideo
Consumer przygotowany przez Spark Structured Streaming, który przetwarza te obrazy z wykorzystaniem wcześniejszych modeli i rozbiera je na części pierwsze (podobnie jak to się dzieje w punkcie pierwszym – Storage). Następnie, w formie lżejszych informacji (metadane) przesyła na kolejny endpoind kafki.
Consumer znów przygotowany przez Spark Structured Streaming, ale nasłuchujący na drugim endpoincie – z metadanymi. Jeśli informacje, które się tam pojawią są podejrzane, wysyłany jest alert do przygotowanej aplikacji, przed którą siedzą nasi żołnierze WOC.
Moduł do analizy
Ostatnim elementem który został nam do ogrania jest moduł do analizy. tutaj pomijamy system streamingowy i niejako zataczamy koło, trafiając do naszego Storage. Z tego miejsca musimy zbudować job, który pozwoli nam sprawnie indeksować dane z bazy danych do technologii full-text search. Oto co proponuję:
Spark, który wyciąga dane z HBase i umieszcza je (być może w odpowiednio okrojonej formie) w Elasticsearch
Elasticsearch, który przechowuje dane.
Kibana, która pozwala nam analizować dane umieszczone w Elasticsearch.
Podsumowanie
Oczywiście powyższe zalecenia to raczej intelektualna zabawa, nie poważna analiza i architektura. Służy jednak pobudzeniu myślenia o tym jak można patrzeć na systemy oraz wskazać, że nie są one poza naszym zasięgiem.
Podsumujmy: Amerykanie także mają swoje miejsca wstydu, które wyglądają jakby były rodem z II Wojny Światowej. Rozwiązaniem części z nich, oraz zalążkiem Big Data w Pentagonie, miał (ma) być “Project Maven” który byłby pewnym repozytorium materiałów dronowych. W jego ramach odbywałoby się uczenie i analiza obiektów widzianych przez bezzałogowce.
Jak pokazałem, my także możemy rozwijać nasze siły zbrojne w kontekście Big Data oraz AI. Mam nadzieję, że tak się dzieje – jednym z symptomów zmian jest utworzenie Wojsk Obrony Cyberprzestrzeni. Oby nie były to puste etaty, bo fachowców mamy w Polsce wspaniałych.
Daj znać w komentarzu jak się podobało. Zapraszam też na profil RDF na LinkedIn oraz do newslettera. Pozostańmy w kontakcie!
UWAGA! Już niedługo ukaże się pierwszy polski ebook o Big Data. Całkowicie za darmo dla subskrybentów bloga RDF. Zapisując się na newsletter TERAZ – masz niepowtarzalną okazję dostawać kolejne wersje książki i zgłaszać swoje poprawki, a nawet stać się jednym z autorów. Więcej tutaj.
Dokonując transformacji w Sparku, bardzo często korzystamy z gotowych, wbudowanych rozwiązań. Łączenie tabel, explodowanie tablic na osobne wiersze czy wstawianie stałej wartości – te i wiele innych operacji zawarte są jako domyślne funkcje. Może się jednak okazać, że to nie wystarczy. Wtedy z pomocą w Sparku przychodzi mechanizm UDF (User Defined Function).
Dzisiaj o tym jak krok po kroku stworzyć UDFa, który może być wyorzystany w wygodny sposób wszędzie w projekcie. Do dzieła! Całą serię “zrozumieć sparka” poznasz tutaj.
Co to jest UDF w Sparku?
Wczuj się w sytuację. Tworzysz joba sparkowego, który obsługuje dane firmowe dotyczące pracowników. Chcesz przyznawać premie tym najlepszym, najwierniejszym i najbardziej pracowitym i zyskownym. Po zebraniu potrzebnych informacji w jednym DataFrame, będziemy chcieli utworzyć kolumnę “bonus” która zawiera prostą informację: kwotę premii na koniec roku.
Aby to wyliczyć, został utworzony wcześniej wzór. Wykorzystując informacje dotyczące stanowiska, zyskowności projektu, oceny współpracowników, przepracowanych godzin i kilku innych rzeczy. Oczywiście nie ma możliwości, żeby wyliczyć to przy pomocy zwykłych funkcji. Z drugiej jednak strony, jeśli mielibyśmy jednostkowo wszystkie potrzebne dane – nie ma problemu, aby taki wzór zakodować.
Temu właśnie służą sparkowe UDFs, czyli User Defined Functions. To funkcje, których działanie sami możemy napisać i które pozwolą nam na modyfikację Datasetów w sposób znacznie bardziej customowy. Można je utworzyć na kilka różnych sposobów, ale ja dzisiaj chciałbym przedstawić Ci swój ulubiony.
A ulubiony dlatego, ponieważ:
Jest elegancko zorganizowany
Daje możliwość wielokrotnego wykorzystywania UDFa w całym projekcie, przy jednokrotnej inicjalizacji go.
Jak zbudować UDF w Apache Spark? Instrukcja krok po kroku.
Instrukcja tworzenia UDFa jest dość prosta i można ją streścić do 3 kroków:
Stwórz klasę UDFa (rozszerzającą UDFX – np. UDF1, jeśli mamy do podania jedną kolumnę).
ZarejestrujUDFa.
Wywołaj UDFa podczas dodawania kolumny.
Scenariusz
Zobrazujmy to pewnym przykładem. Mamy do dyspozycji dataframe z danymi o ludziach. Chcemy sprawdzić zagrożenie chorobami na podstawie informacji o nich. Dla zobrazowania – poniżej wygenerowany przeze mnie Dataframe. Taki sobie prosty zestaw:-).
Efekt który chcemy osiągnąć? te same dane, ale z kolumną oznaczającą zagrożenie: 1- niskie, 2-wysokie, 3-bardzo wysokie. Oczywiście bardzo tu banalizujemy, w rzeczywistości to nie będzie takie proste!
Załóżmy jednak, że mamy zakodować następujący mechanizm: zbieramy punkty zagrożenia.
Bycie palaczem daje +20 do zagrożenia,
Wiek ma przedziały: do 30 lat (+0); do 60 lat (+10); do 80 lat (+20); powyżej (+40)
Aktywności fizyczne: jeśli są, to każda z nich daje -10 (czyli zabiera 10 pkt).
Tak, wiem – to nawet nie banalne, a prostackie. Rozumiem, zebrałem już baty od siebie samego na etapie wymyślania tego wiekopomnego dzieła. Idźmy więc dalej! Grunt, żeby był tutaj jakiś dość skomplikowany mechanizm (w każdym razie bardziej skomplikowany od takiego który łatwo możemy “ograć” funkcjami sparkowymi).
Krok 1 – Stwórz klasę UDFa
Disclaimer: zakładam, że piszemy w Scali (w Javie robi się to bardzo podobnie).
Oczywiście można też zrobić samą metodę. Ba! Można to “opękać” lambdą. Jednak, jak już napisałem, ten sposób rodzi największy porządek i jest moim ulubionym;-). Utwórz najpierw pakiet który nazwiesz “transformations”, “udfs” czy jakkolwiek będzie dla Ciebie wygodnie. Grunt żeby trzymać wszystkie te klasy w jednym miejscu;-).
Wewnątrz pakietu utwórz klasę (scalową) o nazwie HealtFhormulaUDF. Ponieważ będziemy przyjmowali 3 wartości wejściowe (będące wartościami kolumn smoker, age i activities), rozszerzymy interfejs UDF3<T1, T2, T3, R>. Oznacza to, że musimy podczas definicji klasy podać 3 typy wartości wejściowych oraz jeden typ tego co będzie zwracane.
Następnie tworzymy metodę call(T1 t1, T2 t2, T3 t3), która będzie wykonywać realną robotę. To w niej zaimplementujemy nasz mechanizm. Musi ona zwracać ten sam typ, który podaliśmy na końcu deklaracji klasy oraz przyjmować argumenty, które odpowiadają typami temu, co podaliśmy na początku deklaracji. Gdy już to mamy, wewnątrz należy zaimplementować mechanizm, który na podstawie wartości wejściowych wyliczy nam nasze ryzyko zachorowania. Wiem, brzmi to wszystko odrobinę skomplikowanie, ale już pokazuję o co chodzi. Spójrz na skończony przykład poniżej.
package udfs
import org.apache.spark.sql.api.java.UDF3
class HealthFormulaUDF extends UDF3[String, Int, String, Int]{
override def call(smoker: String, age: Int, activities: String): Int = {
val activitiesInArray: Array[String] = activities.split(",")
val agePoints: Int = ageCalculator(age)
val smokePoints: Int = if(smoker.toLowerCase.equals("t")) 20 else 0
val activitiesPoints = activitiesInArray.size * 10
agePoints + smokePoints - activitiesPoints
}
def ageCalculator(age: Int): Int ={
age match {
case x if(x < 30) => 0
case x if(x >= 30 && x < 60) => 10
case x if(x >= 60 && x < 80) => 20
case _ => 40
}
}
}
Dodałem sobie jeszcze pomocniczą funkcję “ageCalculator()”, żeby nie upychać wszystkiego w metodzie call().
Zarejestruj UDF
Drugi krok to rejestracja UDF. Robimy to, aby potem w każdym miejscu projektu móc wykorzystać utworzony przez nas mechanizm. Właśnie z tego powodu polecam dokonać rejestracji zaraz za inicjalizacją Spark Session, a nie gdzieś w środku programu. Pozwoli to nabrać pewności, że ktokolwiek nie będzie w przyszłości wykorzystywał tego konkretnego UDFa, zrobi to po rejestracji, a nie przed. Poza tym utrzymamy porządek – będzie jedno miejsce na rejestrowanie UDFów, nie zaś przypadkowo tam gdzie komuś akurat się zachciało.
Aby zarejestrować musimy najpierw zainicjalizować obiekt UDFa. Robimy to w najprostszy możliwy sposób. Następnie dokonujemy rejestracji poprzez funkcję sparkSession.udf.register(). Musimy tam przekazać 3 argumenty:
Nazwę UDFa, do której będziemy się odnosić potem, przy wywoływaniu
Obiekt UDFa
Typ danych, jaki zwraca konkretny UDF (w naszym przypadku Integer). UWAGA! Typy te nie są prostymi typami Scalowymi. To typy sparkowe, które pochodzą z klasy DataTypes.
Poniżej zamieszczam całość, razem z inicjalizacją sparkSession aby było wiadomo w którym momencie t uczynić;-).
val sparkSession = SparkSession.builder()
.appName("spark3-test")
.master("local")
.getOrCreate()
val healthFormulaUDF: HealthFormulaUDF = new HealthFormulaUDF()
sparkSession.udf.register("healthFormulaUDF", healthFormulaUDF, DataTypes.IntegerType)
W tym momencie UDF jest już zarejestrowany i można go wywoływać gdziekolwiek w całym projekcie.
Wywołaj UDF
Ostatni krok to wywołanie UDFa. To będzie bardzo proste, ale musimy zaimportować callUDF z pakietu org.apache.spark.sql.functions (można też zaimportować wszystkie funkcje;-)).
Ponieważ chcemy utworzyć nową kolumnę z liczbą punktów, skorzystamy z funkcji withColumn(). Całość poniżej.
val peopleWithDiseasePoints: Dataset[Row] = peopleDF.withColumn("diseasePoints",
callUDF("healthFormulaUDF", col("smoker"), col("age"), col("activities")))
Efekt jest jak poniżej. Im mniej punktów w “diseasePoints” tym lepiej. Cóż, chyba nie mam się czym przejmować, mam -20 pkt!
Podsumowanie
W tym artykule dowiedzieliśmy się czym w Apache Spark jest UDF. Zasadniczo całość można sprowadzić do 3 prostych kroków:
Stwórz klasę UDFa (rozszerzającą UDFX – np. UDF1, jeśli mamy do podania jedną kolumnę).
ZarejestrujUDFa.
Wywołaj UDFa podczas dodawania kolumny.
To był materiał z serii “Zrozumieć Sparka”. Nie pierwszy i definitywnie nie ostatni! Jeśli jesteś wyjątkowo głodny/a Sparka – daj znać szefowi. Przekonaj go, żeby zapisał Ciebie i Twoich kolegów/koleżanki na szkolenie ze Sparka. Omawiamy całą budowę od podstaw, pracujemy dużo i intensywnie na ciekawych danych, a wszystko robimy w miłej, sympatycznej atmosferze;-) – Zajrzyj tutaj!
A jeśli chcesz pozostać z nami w kontakcie – zapisz się na newsletter lub obserwuj RDF na LinkedIn. Koniecznie, zrób to i razem twórzmy polską społeczność Big Data!
Właśnie skończyłem kolejne szkolenie (nie byle jakie, bo to było 2-miesięczne, kompleksowe – serio, hardcore). Uświadomiło mi ono jedną bardzo konkretną rzecz w kontekście naszego zrozumienia systemów Big Data. Chciałem się nią podzielić. Artykuł przede wszystkim do technicznych, ale… nie tylko. Zdecydowanie nie tylko.
Złożoność – nasz główny wróg
Podchodząc do systemu przetwarzania bardzo dużych ilości danych, mamy jednego podstawowego wroga. Staje przed nami niczym behemot już na poziomie koncepcji. Jest to… stopień złożoności problemu. Przyznajmy szczerze – nie lubimy złożonych problemów. Ani w życiu prywatnym, ani zawodowym. Aby rozwiązać taki problem, należy wytężyć mózgownicę do takich granic, które u niektórych powodują niemały ból.
Szczególnie daje się to we znaki, gdy ktoś przeszedł do Big Data z “tradycyjnej IT”. Jeśli robiłeś wcześniej aplikacje webowe, możesz doznać szoku. I nie mówię nawet o tym, że dotychczas wszystkie Twoje problemy zawarte były w jednym pliku z logami, podczas gdy tutaj nawet pojedyncza technologia ma kilka serwisów, a każdy z nich swoje własne logi.
Po prostu złożoność jest inna. Robiąc aplikację webową (zostańmy przy tym), mam jasne wytyczne, standardy i zwykle prostą ścieżkę, którą uruchamia (najczęściej) użytkownik. Wejdziemy pod odpowiedni adres? W takim razie musimy wysłać zapytanie do bazy danych, dokonać kilku obliczeń i wyrenderować stronę końcową.
Gorzej, jeśli trzeba zbudować cały skomplikowany system, a wejście (rozumiane jako input)… cóż, wejścia czasami nie ma. Albo jest ich bardzo, bardzo wiele. Albo – co gorsza – jest wejście, wyglądające bardzo “tradycyjnie”(np. request użytkownika).
Jak zaprojektować system – problem złudnego “wejścia” (inputu)
Przypuśćmy taką prostą sytuację. Robimy aplikację-wyszukiwarkę filmów związanych z danymi miastami. W efekcie wpiszemy nazwę miasta, a otrzymujemy listę miast, które w ten czy inny sposób dotyczą go (czy to w kontekście tematyki czy lokalizacji).
Bardzo łatwo w takiej sytuacji zacząć całe projektowanie wychodząc od użytkownika i mając przeświadczenie, że to on musi uruchamiać całą machinę. No świetnie, zatem wcielmy się w taką rolę. Użytkownik wpisuje nazwę miasta i… i co? Czy mam teraz starać się wyszukiwać po internecie wszystkich możliwych informacji? Byłoby to całkiem, całkiem długotrwałym procesem.
No dobrze, więc może zacząć zbierać oraz przetwarzać dane, osobno? Pomysł dobry. Jednak i tutaj można łatwo wpaść w pułapkę wąskiego myślenia. Ciągle mamy z tyłu głowy użytkownika, więc zaczynają powstawać dziwne pomysły, na uruchamianie przetwarzania po wykonanym requeście, w trakcie itd. Ciągle mamy tą manierę, że staramy się wychodzić od jednego punktu i przejść przez wszystkie elementy systemu. To trochę tak, jakbyśmy starali się złapać bardzo dużo drewnianych klocków na raz. Nie ma szans – wypadnie. Kto próbował ekspresowo posprzątać po zabawach swoich dzieci u Dziadków, wie o co chodzi.
Słowo klucz: decentralizacja
Prowadząc szkolenie, gdzieś w połowie zorientowałem się, że coś jest nie tak. Zbadałem temat i zauważyłem, że kursanci bardzo dziwnie podeszli do budowy modułów. Chodziło konkretnie o te podstawowe rzeczy, jakimi jest wejście i wyjście aplikacji (input i output) oraz zarządzanie całością. Zasadniczo cały projekt opierał się oczywiście o bardzo wiele mniejszych modułów. Niektóre pobierały dane z internetu, inne te dane czyściły i przetwarzały. Jeszcze inny moduł – streamingowy – służył do kontaktu użytkownika z systemem.
W pewnym momencie, po raz kolejny dostałem pytanie, które brzmiało mniej więcej tak: “No, skoro mamy mnóstwo małych modułów, to chyba musimy też gdzieś zbudować skrypt, który to wszystko uruchamia prawda?“. Uznałem, że czas na radykalną zmianę myślenia, przerwanie “starego” paradygmatu i zrozumienia o co chodzi w systemach do przetwarzania i obsługi dużych danych.
Myśl po nowemu – czyli jak poprawnie patrzeć na systemy Big Data?
Oczywiście nie ma jednej złotej zasady, dzięki której zrozumiemy “filozofię Big Data”. Jest jednak coś, czego zrozumienie może być przełomem. Pozwoli wygrać ze złożonością, pozwoli zrozumieć duży, skomplikowany system. Pomoże – wreszcie – przestać siwieć (albo, jak w moim przypadku jest – łysieć) z frustracji.
Otóż, chodzi o magiczne słowo: decentralizacja. Nie, mowa nie o technologii blockchain;-). Chodzi o umiejętność spojrzenie na cały system metodą “od ogółu do szczegółu” i zrozumienie poszczególnych elementów (modułów lub powiązań między nimi). Spójrzmy na kilka kwestii, które to tłumaczą.
Każdy wielki system zbudowany jest z wielu mniejszych (co nie znaczy małych) modułów. Na etapie rozumienia całości, nie musimy wgłębiać się w technikalia czy implementację. Wystarczy nam ogólna wiedza o tym co dany moduł przyjmuje, a co zwraca (jakie jest jego zadanie). Dodatkowo jeśli wiemy z jakimi modułami łączy się (bezpośrednio, lub na poziomie logicznym) to już w ogóle bardzo dużo.
Każdy moduł ma swoje zadanie. Niekoniecznie musi być zależne od innych modułów! Przykładowo, jeśli potrzeba nam w systemie pogody, to potrzeba nam pogody. Nie musimy wiązać tego z modułem, który pobiera filmy, albo składuje requesty od użytkownika. W momencie rozumienia modułu od pogody, musimy zbudować mechanizmy pobierające pogodę. Jak to zrobimy? Z wykorzystanie pythona, javy? A może Nifi?
Każdy moduł może być uruchamiany niezależnie od użytkownika. I tutaj musimy znać miejsce takiego podsystemu w systemie.
Jeśli jest niezależny od czegokolwiek – wystarczy prosty skrypt oraz jakiś scheduler, typu Airflow czy Oozie. Pogodę możemy pobierać co godzinę niezależnie od wszystkiego.
Jeśli jest zależny, musimy wiedzieć w jaki sposób jest zależny. Znów najprawdopodobniej użyjemy schedulera, ale pewnie uzależnimy go od wyników innych modułów (jeśli dane nie zostały pobrane, nie ma sensu uruchamiać czyszczenia).
Może się okazać, że moduł naprawdę jest w ścisłym kontakcie z użytkownikiem. W takiej sytuacji, po prostu musimy to dobrze umieścić.
Gdy pracujemy z danym modułem, możemy się zagłębić w szczegóły, a jednocześnie “zapomnieć” o reszcie systemu. Gdy – znów – zaciągamy dane pogodowe, nie musimy myśleć o tym jak one potem zostaną wykorzystane. Dzięki temu usuwamy element, który nas przytłacza. Aby to zrobić – to istotne – powinniśmy wcześniej dobrze zaprojektować całość, łącznie z szczegółowo opisanym wyjściem (output’em). Jakie dokładnie dane pogodowe muszę zwrócić? Gdzie je zapisać? Do jakiej tabeli? Z jaką strukturą? To wszystko powinno być spisane na etapie projektowania, przed implementacją.
Podsumowanie
Tak więc, wracając do problemu ze szkolenia – nie, nie musimy mieć żadnego skryptu, który uruchamia moduły jeden po drugim. Wręcz byłoby to zabiciem idei. Moduły za to powinniśmy uruchamiać w którymś z wyspecjalizowanych schedulerów (polecam Airflow). Dzięki nim możemy przeznaczyć do regularnego startu konkretny moduł, albo połączyć go z innymi. Do tego możemy obsłużyć różne wyniki (np. wysłać email, jeśli coś pójdzie nie tak), przejrzeć logi itd.
Zdaję sobie sprawę, że to co przedstawiłem powyżej, dla wielu jest banałem. Jest jednak taki etap (na początku), gdy trzeba “przeskoczyć” na inne myślenie. I warto zacząć właśnie od kwestii decentralizacji.
Między innymi takich rzeczy, poza stricte technicznymi, uczę na naszych RDFowych szkoleniach. Przejrzyj te, które możemy dla Was zrobić, a potem przekonaj szefa, że solidnie wykwalifikowany zespół, to lepsze wyniki firmy;-).
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Razem możemy więcej!
O tym, że Apache Ozone jest mniej podobny do HDFSa niż można przypuszczać, pisałem w artykule o budowie. Ponieważ postanowiłem stworzyć system do gromadzenia i analizy danych giełdowych, musiałem też zbudować nowy eksperymentalny klaster (czy może lepiej: klasterek;-)). Uznałem, że to znakomita okazja, żeby przetestować dość nowy, dojrzewający niczym włoska szynka system do gromadzenia danych: Apache Ozone.
W tym artykule znajdziesz kilka moich obserwacji oraz – co ważniejsze – lekcji. Będą z pewnością przydatne, jeśli także chcesz spróbować swoich sił i zbadać ten teren. Będą przydatne, ponieważ dokumentacja jest wybrakowana i nie odpowiada na wiele pytań, a społeczność… cóż, jeszcze właściwie nie istnieje. Bierz kubek mocnej jak wiedźmiński eliksir kawy – i zanurzmy się w przygodę!
Apache Ozone: obserwacje i informacje
Zacznijmy od mniej istotnej części, czyli moich subiektywnych przemyśleń na temat Apache Ozone. Poniżej 3 najistotniejsze z nich.
Ozone to nie HDFS. To nawet nie system plików (FS). Opisywałem to już w artykule na temat tego jak Ozone jest zbudowany (o architekturze). Podchodząc do “kontynuacji HDFSa” oczekiwałem podobnego systemu plików, jednak zapewne z nieco inną architekturą. Przeliczyłem się mocno. Ozone bowiem to nie File System, a Object Store. Skutkuje to przede wszystkim bardzo płaską strukturą. Nie zrobimy więc rozbudowanych, hierarchicznych struktur, jak miało to miejsce w HDFSie.
Ozone ma bardzo, bardzo niewielką społeczność. Co rodzi mocne komplikacje. No właśnie. To jest naprawdę problematyczna część. Warto wziąć poprawkę na termin w jakim to piszę. Apache Ozone jest dostępny w repozytorium głównym Mavena od listopada ubiegłego roku. Wersja GA została (jeśli się nie mylę) udostępniona dopiero w zeszłym roku. To wszystko sprawia, że technologia jest jeszcze mało dojrzała – przynajmniej w obszarze społeczności. Jest to bardzo ciekawy moment dla osób z pionierskim zacięciem;-). Praktycznie żaden błąd na który się natknąłem, nie był nigdzie w Internecie opisany. Rzecz bardzo rzadko spotykana. Chociaż ciekawa!
Warto od samego początku poznać architekturę. Ja przyznam, że miałem dwa podejścia do Ozona. Za pierwszym razem poległem. Było to spowodowane moją gorącą krwią i chęcią jak najszybszego przetestowania w boju nowej technologii. To błąd! Naprawdę warto przeznaczyć trochę czasu, żeby wgryźć się najpierw w to jak zbudowany jest Apache Ozone. Jeśli tego nie zrobimy, bardzo ciężko będzie rozwiązywać problemy, których trochę po drodze na pewno będzie. Jak już napisałem punkt wyżej – Ozone nie ma właściwie społeczności, więc najpewniej większość opisanych błędów spotkasz… w tym artykule. Aby je rozwiązać po prostu warto wiedzieć jak to wszystko działa:-).
Apache Ozone: problemy, które rozwiązałem
Instalując Apache Ozone napotkałem kilka problemów, które rozwiązałem, a którymi chcę się podzielić. Liczę, że ustrzeże Cię to przed wyrywaniem sobie włosów z głowy z powodu frustracji.
Wszystkie serwisy działają, ale plik nie chce się przekopiować z lokalnego systemu plików na Ozone. Podczas kopiowania (polecenie “ozone sh key put /vol1/bucket1/ikeikze2.pdf ikeikze2.pdf”) pojawia się następujący błąd:
Co to oznacza? Nie wiadomo. Wiadomo jedynie, że – mówiąc z angielska – “something is no yes”. W tym celu udajemy się do logów. Tu nie chcę zgrywać ozonowego mędrca, więc powiem po prostu: popróbuj. Problem może być w paru logach, ale z całą pewnością ja bym zaczął od logów datanode. Logi znajdują się w folderze “logs”, w folderze z zainstalowanym Ozonem (tam gdzie jest też folder bin, etc i inne).
Zacznijmy od komunikatu błędu, który można dostać po przejrzeniu logów ze Storage Container Manager (SCM).
ERROR org.apache.hadoop.hdds.scm.SCMCommonPlacementPolicy: Unable to find enough nodes that meet the space requirement of 1073741824 bytes for metada
ta and 5368709120 bytes for data in healthy node set. Required 3. Found 1.
Rozwiązanie: Należy zmienić liczbę replik, ponieważ nie mamy wystarczająco dużo datanodów w klastrze, aby je przechowywać (nie mogą być trzymane na tej samej maszynie). Aby to zrobić należy wyłączyć wszystkie procesy Ozone, a następnie zmienić plik ozone-site.xml. Konkretnie zmieniamy liczbę replik. Poniżej rozwiązanie, które na pewno zadziała, ale niekoniecznie jest bezpieczne – zmieniamy liczbę replik na 1, w związku z czym nie wymaga on wielu nodów do przechowywania replik.
W tym miejscu pokazane jest jak należy stawiać Apache Ozone. Jak widać są dwie ścieżki i tylko jedna z nich nadaje się do czegokolwiek.
W pierwszej stawiamy każdy serwis osobno: Storage Container Manager, Ozone Manager oraz Datanody. Jest to chociazby o tyle problematyczne, że jeśli mamy tych datanodów dużo, to trzeba by wchodzić na każdy z nich osobno.
Na szczęście istnieje też opcja uruchamiania wszystkiego jednym skryptem. W tym celu należy uruchomić plik start-ozone.sh znajdujący się w folderze sbin.
Jednak aby to zrobić, należy najpierw uzupełnić konfigurację. Zmiany są dwie:
Należy dodać kilka zmiennych do pliku ozone-env.sh w folderze “[folder_domowy_ozone]/etc/hadoop“.
Nalezy utworzyć plik workers wewnątrz tego samego folderu co [1].
Zmienne: tu należy dodać kilka zmiennych wskazujących na użytkowników ozona. Sprawa jest niejasna, bo Ozone przeplata trochę nomenklaturę z HDFS. Ja dodałem obie opcje i jest ok.
Po tym wszystkim możemy uruchomić skrypt start-ozone.sh
OM wyłącza się po uruchomieniu klastra
Po uruchomieniu klastra (sbin/start-ozone.sh) Ozone Manager zwyczajnie pada. Kiedy zajrzymy w logi, znajdziemy taki oto zapis:
Ratis group Dir on disk 14dd99c6-de01-483f-ac90-873d71fb5a44 does not match with RaftGroupIDbf265839-605b-3f16-9796-c5ba1605619e generated from service id omServiceIdDefault. Looks like there is a change to ozone.om.service.ids value after the cluster is setup
Były także inne logi, natomiast wiele wskazywało na Ratisa oraz omServiceIdDefault a także ozone.om.service.ids. Jeśli mamy następujący problem, oznacza to, że nasz klaster próbuje automatycznie włączyć tryb HA na Ozon Manager. Ponieważ mi na takim trybie nie zależy (mój klaster jest naprawdę mały i nie miałoby to większego sensu), wprost wyłączyłem HA. Aby to zrobić, należy zmodyfikować ustawienia.
Plik ozone-site.xml (znajdujący się w [katalog ozona]/etc/hadoop/ozone-site.xml)
Oczywiście po zaktualizowaniu ozone-site.xml plik powinien być rozesłany na wszystkie nody, a następnie klaster powinien zostać uruchomiony ponownie. Jeśli chcesz skorzystać z trybu HA, wszystkie (chyba;-)) informacje znajdziesz tutaj.
Przy requestach zwykłego użytkownika (nie-roota) wyskakuje błąd o brak dostępów do logów
A więc wszystko już poszło do przodu, spróbowaliśmy z roota (lub innego użytkownika, którym instalowaliśmy Ozone na klastrze) i wszystko było ok. Przynajmniej do czasu, aż zechcemy spróbować podziałać na innym użytkowniku. Wtedy dostajemy taki oto błąd:
java.io.FileNotFoundException: /ozone/ozone-1.2.1/logs/ozone-shell.log (Permission denied)
at java.io.FileOutputStream.open0(Native Method)
at java.io.FileOutputStream.open(FileOutputStream.java:270)
at java.io.FileOutputStream.<init>(FileOutputStream.java:213)
at java.io.FileOutputStream.<init>(FileOutputStream.java:133)
at org.apache.log4j.FileAppender.setFile(FileAppender.java:294)
at org.apache.log4j.FileAppender.activateOptions(FileAppender.java:165)
at org.apache.log4j.DailyRollingFileAppender.activateOptions(DailyRollingFileAppender.java:223)
(...)
log4j:ERROR Either File or DatePattern options are not set for appender [FILE].
Pocieszające jest to, że błąd ten nie oznacza, że polecenie do Ozone nie zostało wykonane. Oznacza jedynie, że nie mamy uprawnień do pliku z logami Ozone Shell. Żeby powiedzieć dokładniej, nie mamy dostępu do zapisu na tym pliku.
Nie jest to więc błąd stricte “Ozonowy”. Jest za to stricte linuxowy – należy nadać użytkownikowi odpowiednie uprawnienia. Można to zrobić na kilka różnych sposobów. Jeśli Twój klaster, podobnie jak mój, jest jedynie klastrem eksperymentalnym, możesz śmiało nadać uprawnienia zapisu “innym użytkownikom” pliku. Wchodzimy do folderu z logami i wpisujemy następującą komendę:
chmod a+rw ozone-shell.log
Podsumowanie
Apache Ozone to naprawdę ciekawa i – mam nadzieję – przyszłościowa technologia. Musi jednak jeszcze trochę wody w Wiśle upłynąć, aby zyskała popularność oraz dojrzałość HDFSa. Zachęcam jednak do eksperymentowania i dzielenia się tutaj wrażeniami;-)
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Razem możemy więcej!
Apache Ozone to następca HDFS – przynajmniej w marketingowym przekazie. W rzeczywistości sprawa jest nieco bardziej złożona i proste analogie mogą być złudne. Jako, że jestem w trakcie budowy systemu do analizy spółek giełdowych, buduję także nowy, eksperymentalny klaster (czy może – klasterek;-)). Uznałem to za idealny moment, żeby przetestować, bądź co bądź nową technologię, jaką jest Apache Ozone. W kolejnym artykule podzielę się swoimi obserwacjami oraz problemami które rozwiązałem. Zacznijmy jednak najpierw od poznania podstaw, czyli architektury Apache Ozone. Zapraszam!
Czym (nie) jest Apache Ozone?
Jeśli Ozone to następca HDFSa, a HDFS to system plików, to Apache Ozone jest systemem plików prawda? Nie. I to jest pierwsza różnica, którą należy dostrzec. HDFS był bliźniaczo podobny (w interfejsie i ogólnej budowie użytkowej, nie architekturze) do standardowego systemu plików dostępnego na linuxie. Mieliśmy użytkowników, foldery, a w nich pliki, ewentualnie foldery, w których mogły być pliki. Albo foldery. I tak w kółko.
Apache Ozone to rozproszony, skalowalny object store (/storage). Na temat podejścia object storage można przeczytać tutaj. Podstawową jednak różnicą jest to, że Ozone ma strukturę płaską, a nie hierarchiczną. Również, podobnie jak HDFS, dzieli pliki na bloki, także posiada swoje repliki, jednak nie możemy zawierać zagnieżdżonych folderów.
Podstawowa budowa Apache Ozone
Ozone oczywiście jest systemem rozproszonym – działa na wielu nodach (serwerach/komputerach).
Oto podstawowy opis struktury:
Volumes – podobne do kont użytkowników lub katalogów domowych. Tylko admin może je utworzyć.
Buckets – podobne do folderów. Bucket może posiadać dowolną liczbę keys, ale nie może posiadać innych bucketów.
Keys – podobne do plików.
Ozone zbudowany jest z kilku podstawowych komponentów/serwisów:
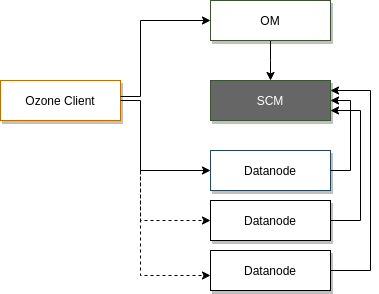
Ozone Manager (OM) – odpowiedzialny za namespacy. Odpowiedzialny za wszystkie operacje na volumes, buckets i keys. Każdy volume to osobny root dla niezależnego namespace’u pod OM (to różni go od HDFSa).
Storage Container Manager (SCM) – Działa jako block manager. Ozone Manage requestuje blocki do SCM, do których klientów można zapisać dane.
Data Nodes – działa w ramach Data Nodes HDFSowych lub w uruchamia samodzielnie własne deamony (jeśli działa bez HDFSa)
Ozone oddziela zarządzanie przestrzenią nazw (namespace management) oraz zarządzanie przestrzenią bloków (block space management). To pomaga bardzo mocno skalować się Ozonowi. Ozone Manager odpowiada za zarządzanie namespacem, natomiast SCM za zarządzanie block spacem.
Ozone Manager
Volumes i buckets są częścią namespace i są zarządzane przez OM. Każdy volume to osobny root dla niezależnego namespace’a pod OM. To jedna z podstawowych różnic między Apache Ozone i HDFS. Ten drugi ma jeden root od którego wszystko wychodzi.
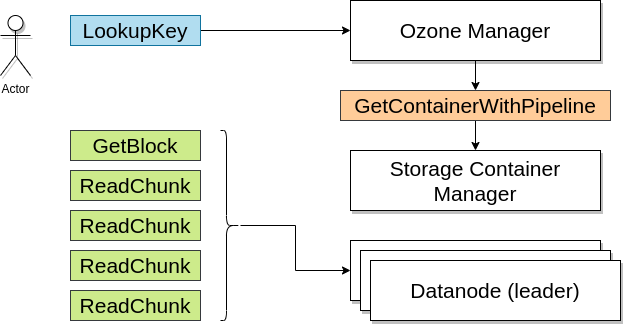
Jak wygląda zapis do Ozone?
Aby zapisać key do Ozone, client przekazuje do OM, że chce zapisać konkretny key w konkretnym bucket, w konkretnym volume. Jak tylko OM ustali, że możesz zapisać plik w tym buckecie,OM zaalokuje block dla zapisu danych.
Aby zaalokować blok, OM wysyła request do SCM. To on tak naprawdę zarządza Data Nodami. SCM wybiera 3 data nody (najprawdopodobniej na repliki) gdzie klient może zapisać dane. SCM alokuje blok i zwraca block ID do Ozone Managera.
Ozone Manager zapisuje informacje na temat tego bloku w swoich metadanych i zwraca blok oraz token bloku (uprawnienie bezpieczeństwa do zapisu danych na bloku) do klienta.
Klient używa tokena by udowodnić, że może zapisać dane na bloku oraz zapisuje dane na data node.
Gdy tylko zapis jest ukończony na data node, klient aktualizuje informacje o bloku w OM.
Jak wygląda odczyt danych (kluczy/keys) z Ozone?
Klient wysyła request listy bloków do Ozone Manager.
OM zwraca listę bloków i tokenów bloków, dzięki czemu klient może odczytać dane z data nodes.
Klient łączy się z data node i przedstawia tokeny, po czym odczytuje dane z data nodów.
Storage Container Manager
SCM jest głównym nodem, który zarządza przestrzenią bloków (block space). Podstawowe zadanie to tworzenie i zarządzanie kontenerami. O kontenerach za chwilkę, niemniej pokrótce, są to podstawowe jednostki replikacji.
Tak jak napisałem, Storage Container Manager odpowiada za zarządzanie danymi, a więc utrzymuje kontakt z Data Nodami, gra rolę Block Managera, Replica Managera, ale także Certificate Authority. Wbrew intuicji, to SCM (a nie OM) jest odpowiedzialny za tworzenie klastra Ozone. Gdy wywołujemy komendę init, SCM tworzy cluster identity oraz root certificates potrzebne do CA. SCM zarządza cyklem życia Data Node.
SCM do menedżer bloków (block manager). Alokuje bloki i przydziela je do Data Nodów. Warto zawuażyć, że klienci pracują z blokami bezpośrednio (co jest akurat trochę podobne do HDFSa).
SCM utrzymuje kontakt z Data Nodami. Jeśli któryś z nich padnie, wie o tym. Jeśli tak się stanie, podejmuje działania aby naprawić liczbę replik, aby ciągle było ich tyle samo.
SCM Certificate Authority jest odpowiedzialne za wydawanie certyfikatów tożsamości (identity certificates) dla każdej usługi w klastrze.
SCM nawiązuje regularny kontakt z kontenerami poprzez raporty, które te składają. Ponieważ są znacznie większymi jednostkami niż bloki, raportów jest wiele wiele mniej niż w HDFS. Warto natomiast pamiętać, że my, jako klienci, nie komunikujemy się bezpośrednio z SCM.
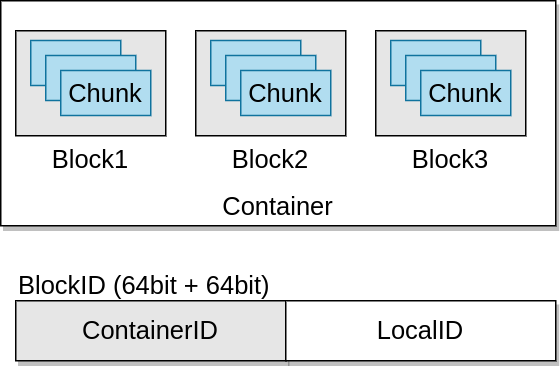
Kontenery i bloki w Ozone(Contrainers and blocks)
Kontenery (containers) to podstawowe jednostki w Apache Ozone. Zawierają kilka bloków i są całkiem spore (5gb domyślnie).
W konkretnym kontenerze znajdziemy ileś bloków, które są porcją danych. Jednak same bloki nie są replikowane. Informacje o blokch nie są też zarządzane przez SCM – są trzymane tylko informacje o kontenerach i to kontenery podlegają replikacji. Kiedy OM requestuje o zaalokowanie nowego bloku do SCM, ten “namierza” odpowiedni kontener i generuje block id, które zawiera w sobie ContainerIs + LocalId (widoczne na obrazku powyżej). Klient łączy się wtedy z Datanode, który przechowuje dany kontener i to datanode zarządza konkretnym blokiem na podstawie LocalId.
Data Nodes
Data Nody to serwery, na których dzieje się prawdziwa, docelowa magia Ozone. To tutaj składowane są wszystkie dane. Warto pamiętać, że to z nimi bezpośrednio łączy się klient. Zapisuje on dane w postaci bloków. Data node agreguje te dane i zbiera do kontenerów (storage containers). W kontenerach, poza danymi, znajdują się też metadane opisujące je.
Jak to wszystko działa? Kiedy chcemy odczytać plik, uderzamy do OM. Ten zwraca nad listę bloków, która składa się z pary ContainerId:LocalId. To dość chude informacje, ale wystarczą, aby można było udać się do konkretnych kontenerów i wyciągnąć konkretne bloki (LocalId to po prostu unikatowy numer ID w ramach kontenera, czyli w ramach dwóch różnych kontenerów moga być dwa bloki o LocalID=1, natomiast w ramach jednego kontenera nie).
Podsumowanie
Mam szczerą nadzieję, że tym artykułem pomogłem odrobinę zrozumieć architekturę Apache Ozone. Przyznam, że pełnymi garściami czerpałem z dokumentacji. Choć – jestem przekonany – jest to pierwszy polski materiał na temat tej technologii, to z pewnością nie jest ostatni. Jestem w trakcie instalowania Ozone na eksperymentalnym klasterku RDFowym i na bieżąco piszę artykuł o doświadczeniach i błędach, jakie napotkałem. Obserwuj RDF na LinkedIn i zapisz się na newsletter, to nie przegapisz!
Machine Learning w Sparku? Jak najbardziej! W poprzednim artykule pokazałem efekty prostego mechanizmu do porównywania tekstów, który zbudowałem. Całość jest zrobiona w Apache Spark, co niektórych może dziwić. Dzisiaj chcę się podzielić tym jak dokładnie zbudować taki mechanizm. Kubki w dłoń i lecimy zanurzyć się w kodzie!
Powiem jeszcze, że tutaj pokazuję jak zrobić to w prostej, batchowej wersji. Po prostu uruchomimy cały job sparkowy wraz z tekstem i dostaniemy odpowiedzi. W innym artykule jednak pokażę jak zrobić także joba streamingowego. Dzięki temu stworzymy mechanizm, który będzie nasłuchiwał i naprawdę szybko będzie zwracał wyniki w czasie rzeczywistym (mniej więcej, w zależności od zasobów – czas ocekiwania to kilka, kilkanaście sekund). Jeśli chcesz dowiedzieć się jak to zrobić – nie zapomnij zasubskrybować bloga RDF!
Spark MlLib
Zacznijmy od pewnej rzeczy, żeby nam się nie pomyliło. Spark posiada bibliotekę, która służy do pracy z machine learning. Nazywa się Spark MlLib. Problem polega na tym, że wewnątrz rozdziela się na dwie pod-biblioteki (w scali/javie są to po prostu dwa pakiety):
Spark MlLib – metody, które pozwalają na prace operując bezpośrednio na RDD. Starsza część, jednak nadal wspierana.
Spark Ml – metody, dzięki którym pracujemy na Datasetach/Dataframach. Jest to zdecydowanie nowocześniejszy kawałek biblioteki i to z niego właśnie korzystam.
Ta sama uwaga odnośnie “provided” co w przypadku mavena.
Spark NLP od John Snow Labs
Chociaż Spark posiada ten znakomity moduł SparkMlLib, to niestety brak w nim wielu algorytmów. Zawierają się w tych brakach nasze potrzeby. Na szczęście, luka została wypełniona przez niezależnych twórców. Jednym z takich ośrodków jest John Snow Labs (można znaleźć tutaj). Samą bibliotekę do przetwarzania tekstu, czyli Spark-NLP zaciągniemy bez problemu z głównego repozytorium Mavena
Dodawanie dependencji, jeśli korzystamy z Mavena (plik pom.xml):
Dodawanie dependencji jeśli korystamy z SBT (plik build.sbt):
libraryDependencies += "com.johnsnowlabs.nlp" %% "spark-nlp" % "3.3.4" % Test
Dane
Dane same w sobie pochodzą z 3 różnych źródeł. I jak to bywa w takich sytuacjach – są po prostu inne, pomimo że teoretycznie dotyczą tego samego (tweetów). W związku z tym musimy zrobić to, co zwykle robi się w ramach ETLów: sprowadzić do wspólnej postaci, a następnie połączyć.
Dane zapisane są w plikach CSV. Ponieważ do porównywania będziemy używać tylko teksty, z każdego zostawiamy tą samą kolumnę – text. Poza tą jedną kolumną dorzucimy jednak jeszcze jedną. To kolumna “category”, która będzie zawierać jedną z trzech klas (“covid”, “finance”, “grammys”). Nie będą to oczywiście klasy służące do uczenia, natomiast dzięki nim będziemy mogli sprawdzić potem na ile dobrze nasze wyszukiwania się “wstrzeliły” w oczekiwane grupy tematyczne. Na koniec, gdy już mamy identyczne struktury danych, możemy je połączyć zwykłą funkcją “union”.
Gdy pracujemy z NLP, bazujemy oczywiście na tekście. Niestety, komputer nie rozumie tekstu. A co rozumie komputer? No jasne, liczby. Musimy więc sprowadzić tekst do poziomu liczb. Konkretnie wektorów, a jeszcze konkretniej – embeddingów. Embeddingi to nisko-wymiarowe reprezentacje czegoś wysoko-wymiarowego. W naszym przypadku będzie to tekst. Czym dokładnie są embeddingi, dobrze wyjaśnione jest na tej stronie. Na nasze, uproszczone potrzeby musimy jednak wiedzieć jedno: embeddingi pozwalają zachować kontekst. Oznacza to w dużym skrócie, że słowo “pizza” będzie bliżej słowa “spaghetti” niż słowa “sedan”.
Sprowadzanie do postaci liczbowej może się odbyć jednak dopiero wtedy, gdy odpowiednio przygotujemy tekst. Bardzo często w skład takiego przygotowania wchodzi oczyszczenie ze “śmieciowych znaków” (np. @, !, ” itd) oraz tzw. “stop words”, czyli wyrazów, które są spotykane na tyle często i wszędzie, że nie opłaca się ich rozpatrywać (np. I, and, be). Oczywiście może to rodzić różne problemy – np. jeśli okroimy frazy ze standardowych “stop words”, wyszukanie “To be or not to be” będzie… puste. To jednak już problem na inny czas;-).
Do przygotowania często wprowadza się także tokenizację, czyli podzielenie tekstu na tokeny. Bardzo często to po prostu wyciągnięcie wyrazów do osobnej listy, aby nie pracować na stringu, a na kolekcji wyrazów (stringów). Spotkamy tu także lemmatyzację, stemming (obie techniki dotyczą sprowadzenia różnych słów do odpowiedniej postaci, aby móc je porównywać).
W naszym przypadku jednak nie trzeba będzie robić tego wszystkiego. Jedyne co musimy, to załączyć DocumentAssembler. Jest to klasa, która przygotowuje dane do formatu zjadliwego przez Spark NLP.
Po zastosowaniu dostajemy kolumnę, która ma następującą strukturę:
W naszym kodzie najpierw inicjalizujemy DocumentAssembler, wykorzystamy go nieco później. Przy inicjalizacji podajemy kolumnę wejściową oraz nazwę kolumny wyjściowej:
val docAssembler: DocumentAssembler = new DocumentAssembler().setInputCol("text")
.setOutputCol("document")
Zastosowanie USE oraz budowa Pipeline
Jak już napisałem, my wykorzystamy Universal Sentence Encoder (USE). Dzięki tym embeddingom całe frazy (tweety) będą mogły nabrać konktekstu. Niestety, sam “surowy” Spark MlLib nie zapewnia tego algorytmu. Musimy tu zatem sięgnąć po wspomniany już wcześniej Spark NLP od John Snow Labs (podobnie jak przy DocumentAssembler). Zainicjalizujmy najpierw sam USE.
val use: UniversalSentenceEncoder = UniversalSentenceEncoder.pretrained()
.setInputCols("document")
.setOutputCol("sentenceEmbeddings")
Skoro mamy już obiekty dosAssembler oraz use, możemy utworzyć pipeline. Pipeline w Spark MlLib to zestaw powtarzających się kroków, które możemy razem “spiąć” w całość, a następnie wytrenować, używać. Wyjście jednego kroku jest wejściem kolejnego. Wytrenowany pipeline (funkcja fit) udostępnia nam model, który możemy zapisać, wczytać i korzystać z niego.
Nasz pipeline będzie bardzo prosty:
val pipeline: Pipeline = new Pipeline().setStages(Array(docAssembler, use))
val fitPipeline: PipelineModel = pipeline.fit(tweetsDF)
Gdy dysponujemy już wytrenowanym modelem, możemy przetworzyć nasze dane (funkcja transform). Po tym kroku otrzymamy gotowe do użycia wektory. Niestety, USE zagnieżdża je w swojej strukturze – musimy więc je sobie wyciągnąć. Oba kroki przedstawiam poniżej:
val vectorizedTweetsDF: Dataset[Row] = fitPipeline.transform(tweetsDF)
.withColumn("sentenceEmbeddings", org.apache.spark.sql.functions.explode(col("sentenceEmbeddings.embeddings")))
Znakomicie! Mamy już tweety w formie wektorów. Teraz należy jeszcze zwektoryzować tekst użytkownika. Tekst będzie przechowywany w Dataframe z jednym wierszem (właśnie owym tekstem) w zmiennej sampleTextDF. Po wektoryzacji usunę zbędne kolumny i zmienię nazwy tak, aby było wiadomo, że te wektory dotyczą tekstu użytkownika, a nie tweetów (przyda się później, gdy będziemy łączyć ze sobą oba Dataframy).
val vectorizedUserTextDF: Dataset[Row] = fitPipeline.transform(sampleTextDF)
.drop("document")
.withColumn("userEmbeddings", org.apache.spark.sql.functions.explode(col("sentenceEmbeddings.embeddings")))
.drop("sentenceEmbeddings")
Implementacja cosine similarity
Uff – sporo roboty za nami, gratuluję! Mamy już tweety oraz tekst użytkownika w formie wektorów. Czas zatem porównać, aby znaleźć te najbardziej podobne! Tylko pytanie, jak to najlepiej zrobić? Muszę przyznać że trochę czasu zajęło mi szukanie algorytmów, które mogą w tym pomóc. Finalnie wybór padł na cosine similarity. Co ważne – nie jest to żaden super-hiper-ekstra algorytm NLP. To zwykły wzór matematyczny, znany od dawna, który porównuje dwa wektory. Tak – dwa najzwyklejsze, matematyczne wektory. Jego wynik zawiera się między -1 a 1. -1 to skrajnie różne, 1 to identyczne. Nas zatem będą interesować wyniki możliwie blisko 1.
Problem? A no jest. Spark ani scala czy java nie mają zaimplementowanego CS. Tu pokornie powiem, że być może po prostu do tego nie dotarłem. Jeśli znasz gotową bibliotekę do zaimportowania – daj znać w komentarzu! Nie jest to jednak problem prawdziwy, bowiem możemy rozwiązać go raz dwa. Samodzielnie zaimplementujemy cosine similarity w sparku, dzięki UDFom (User Defined Function).
Najpierw zacznijmy od wzoru matematycznego:
Następnie utwórzmy klasę CosineSimilarityUDF, która przyjmuje dwa WrappedArrays (dwa wektory), natomiast zwraca zwykłą liczbę zmiennoprzecinkową Double. Wewnątrz konwertuję tablice na wektory, wykorzystuję własną metodę magnitude i zwracam odległość jednego wektora od drugiego.
Klasa CosineSimilarityUDF
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.sql.api.java.UDF2
import scala.collection.mutable
class CosinSimilarityUDF extends UDF2[mutable.WrappedArray[Float], mutable.WrappedArray[Float], Double]{
override def call(arr1: mutable.WrappedArray[Float], arr2: mutable.WrappedArray[Float]): Double = {
val vec1 = Vectors.dense(arr1.map(_.toDouble).toArray)
val vec2 = Vectors.dense(arr2.map(_.toDouble).toArray)
val mgnt1 = magnitude(vec1)
val mgnt2 = magnitude(vec2)
vec1.dot(vec2)/(mgnt1*mgnt2)
}
def magnitude(vector: Vector): Double={
val values = vector.toArray
Math.sqrt(values.map(i=>i*i).sum)
}
}
Znakomicie – po utworzeniu tego UDFa, możemy śmiało wykorzystać go do obliczenia podobieństw między każdym z tweetów a tekstem użytkownika. Aby to uczynić, najpierw rejestrujemy naszego UDFa. Polecam to co zawsze polecam na szkoleniach ze Sparka – zrobić to zaraz po inicjalizacji SparkSession. Dzięki temu utrzymamy porządek i nie będziemy się martwić, jeśli w przyszłości w projekcie ktoś będzie również chciał użyć UDFa w nieznanym obecnie miejscu (inaczej może dojść do próby użycia UDFa zanim zostanie zarejestrowany).
val cosinSimilarityUDF: CosinSimilarityUDF = new CosinSimilarityUDF()
sparkSession.udf.register("cosinSimilarityUDF", cosinSimilarityUDF, DataTypes.DoubleType)
Wróćmy jednak na sam koniec, do punktu w którym mamy już zwektoryzowane wszystkie teksty. Najpierw sprawimy, że każdy tweet będzie miał dołączony do siebie tekst użytkownika. W tym celu zastosujemy crossjoin (artykuł o sposobach joinów w Sparku znajdziesz tutaj). Następnie użyjemy funkcji withColumn, dzięki której utworzymy nową kolumnę – właśnie z odległością. Wykorzystamy do jej obliczenia oczywiście zarejestrowany wcześniej UDF.
val dataWithUsersPhraseDF: Dataset[Row] = vectorizedTweetsDF.crossJoin(vectorizedUserTextDF)
val afterCosineSimilarityDF: Dataset[Row] = dataWithUsersPhraseDF.withColumn("cosineSimilarity", callUDF("cosinSimilarityUDF", col("sentenceEmbeddings"), col("userEmbeddings"))).cache()
Na sam koniec pokażemy 20 najbliższych tekstów, wraz z kategoriami. Aby uniknąć problemów z potencjalnymi “dziurami”, odfiltrowujemy rekordy, które w cosineSimilarity nie mają liczb. Następnie ustawiamy kolejność na desc, czyli malejącą. Dzięki temu dostaniemy wyniki od najbardziej podobnych do najmniej podobnych.
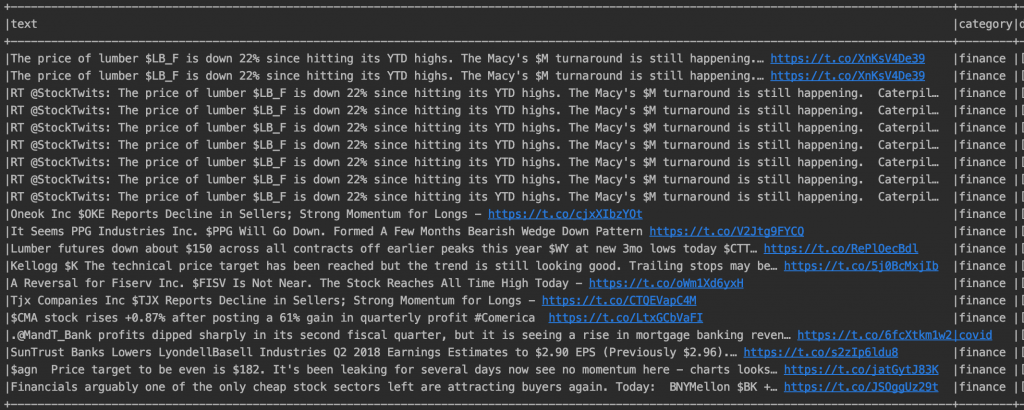
I to koniec! Wynik dla hasła “The price of lumber is down 22% since hitting its YTD highs. The Macy’s $M turnaround is still happening” można zaobserwować poniżej. Więcej wyników – przypominam – można zaobserwować w poprzednim artykule;-).
Wyniki dla mechanizmu text similarity w Apache Spark.
Podsumowanie
Mam nadzieję, że się podobało! Daj znać koniecznie w komentarzu i prześlij ten artykuł dalej. Z pewnością to nie koniec przygody z Machine Learning w Sparku na tym blogu. Zostań koniecznie na dłużej i razem budujmy polskie środowisko Big Data;-). Jeśli chcesz pozostać z nami w kontakcie – zapisz się na newsletter lub obserwuj RDF na LinkedIn.
Pamiętaj także, że prowadzimy szkolenia z Apache Spark. Jakie są? Przede wszystkim bardzo mięsiste i tak bardzo zbliżone do rzeczywistości jak tylko się da. Pracujemy na prawdziwych danych, prawdziwym klastrze. Co więcej – wszystko to robimy w znakomitej atmosferze, a na koniec dostajesz garść materiałów!Kliknij tutaj i podrzuć pomysł swojemu szefowi;-).
![Jak ogarnąć architekturę systemu Big Data? [Wideo] [Big Data w podróży]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/07/zdjecie-blog.png "Jak ogarnąć architekturę systemu Big Data? [Wideo] [Big Data w podróży]")
![Jak uruchomić Spark na klastrze? [wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/07/spark-na-serwerze-blog.png "Jak uruchomić Spark na klastrze? [wideo]")
![Jak zaindeksować dane w Solr z użyciem Spark? [wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/07/grafika-blog.png "Jak zaindeksować dane w Solr z użyciem Spark? [wideo]")
![Jak szybko utworzyć kolekcję w Solr? [wideo]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/07/BLOG-yt-Zbuduj-configset-1.png "Jak szybko utworzyć kolekcję w Solr? [wideo]")
")