Przypominam jeszcze, jeśli nie jesteś członkiem newslettera, po zaciągnięciu się na nasz okręt dostajesz na wejściu prawie 140 stron ebooka o Big Data! Nie zwlekaj;-)
W poprzednim wideo poznaliśmy to czym jest Hadoop. Dzisiaj pociągniemy temat, ale już dużo bardziej praktycznie. Zależało mi bardzo na tym, żeby pokazać jak ta praktyka ma się do rzeczywistości. Pokazałem więc między innymi jak architektura którą omawiałem w poprzednim wideo, ma się do mojego klastra z którego korzystam na co dzień.
Przede wszystkim jednak – wskazałem w jaki sposób popracować z plikami wykorzystując do tego HDFS Shell.
Zapraszam do oglądania!
Jak działa HDFS? Sama praktyka
Poniżej wideo o którym mówię. Poprzednie wprowadzające do Hadoopa – można obejrzeć pod tym linkiem.
Tutaj pobierzesz maszynę wirtualną, która będzie pomocna przy ćwiczeniach Hadoopa.
Zachęcam do subskrypcji kanału na YouTube!
Dzięki temu nie przegapisz żadnego wideo z serii jesiennej!
Wideo obejrzysz tutaj:
Przypominam jeszcze, jeśli nie jesteś członkiem newslettera, po zaciągnięciu się na nasz okręt dostajesz na wejściu prawie 140 stron ebooka o Big Data! Nie zwlekaj;-)
Niedawno zacząłem nową serię – serię jesienną, gdzie zgłębiamy podstawy technologii Big Data. Będziemy kroczek po kroczku poznawać absolutne podstawy. Celem jest “zahaczka” dla każdego, kto chce ruszyć z tematem, ale nie ma pomysłu jak to zrobić:-).
Drugie wideo to rozpoczęta miniseria o Hadoopie. Konkretnie:
Co to jest Hadoop
Jakie komponenty zawiera Hadoop
Jak działa Hadoop
Jak powstał – czemu jest tak bardzo ważny?
Jaka jest architektura HDFS?
Zachęcam do subskrypcji kanału na YouTube!
Dzięki temu nie przegapisz żadnego wideo z serii jesiennej!
Wideo obejrzysz tutaj:
Przypominam jeszcze, jeśli nie jesteś członkiem newslettera, po zaciągnięciu się na nasz okręt dostajesz na wejściu prawie 140 stron ebooka o Big Data! Nie zwlekaj;-)
O tym, że Apache Ozone jest mniej podobny do HDFSa niż można przypuszczać, pisałem w artykule o budowie. Ponieważ postanowiłem stworzyć system do gromadzenia i analizy danych giełdowych, musiałem też zbudować nowy eksperymentalny klaster (czy może lepiej: klasterek;-)). Uznałem, że to znakomita okazja, żeby przetestować dość nowy, dojrzewający niczym włoska szynka system do gromadzenia danych: Apache Ozone.
W tym artykule znajdziesz kilka moich obserwacji oraz – co ważniejsze – lekcji. Będą z pewnością przydatne, jeśli także chcesz spróbować swoich sił i zbadać ten teren. Będą przydatne, ponieważ dokumentacja jest wybrakowana i nie odpowiada na wiele pytań, a społeczność… cóż, jeszcze właściwie nie istnieje. Bierz kubek mocnej jak wiedźmiński eliksir kawy – i zanurzmy się w przygodę!
Apache Ozone: obserwacje i informacje
Zacznijmy od mniej istotnej części, czyli moich subiektywnych przemyśleń na temat Apache Ozone. Poniżej 3 najistotniejsze z nich.
Ozone to nie HDFS. To nawet nie system plików (FS). Opisywałem to już w artykule na temat tego jak Ozone jest zbudowany (o architekturze). Podchodząc do “kontynuacji HDFSa” oczekiwałem podobnego systemu plików, jednak zapewne z nieco inną architekturą. Przeliczyłem się mocno. Ozone bowiem to nie File System, a Object Store. Skutkuje to przede wszystkim bardzo płaską strukturą. Nie zrobimy więc rozbudowanych, hierarchicznych struktur, jak miało to miejsce w HDFSie.
Ozone ma bardzo, bardzo niewielką społeczność. Co rodzi mocne komplikacje. No właśnie. To jest naprawdę problematyczna część. Warto wziąć poprawkę na termin w jakim to piszę. Apache Ozone jest dostępny w repozytorium głównym Mavena od listopada ubiegłego roku. Wersja GA została (jeśli się nie mylę) udostępniona dopiero w zeszłym roku. To wszystko sprawia, że technologia jest jeszcze mało dojrzała – przynajmniej w obszarze społeczności. Jest to bardzo ciekawy moment dla osób z pionierskim zacięciem;-). Praktycznie żaden błąd na który się natknąłem, nie był nigdzie w Internecie opisany. Rzecz bardzo rzadko spotykana. Chociaż ciekawa!
Warto od samego początku poznać architekturę. Ja przyznam, że miałem dwa podejścia do Ozona. Za pierwszym razem poległem. Było to spowodowane moją gorącą krwią i chęcią jak najszybszego przetestowania w boju nowej technologii. To błąd! Naprawdę warto przeznaczyć trochę czasu, żeby wgryźć się najpierw w to jak zbudowany jest Apache Ozone. Jeśli tego nie zrobimy, bardzo ciężko będzie rozwiązywać problemy, których trochę po drodze na pewno będzie. Jak już napisałem punkt wyżej – Ozone nie ma właściwie społeczności, więc najpewniej większość opisanych błędów spotkasz… w tym artykule. Aby je rozwiązać po prostu warto wiedzieć jak to wszystko działa:-).
Apache Ozone: problemy, które rozwiązałem
Instalując Apache Ozone napotkałem kilka problemów, które rozwiązałem, a którymi chcę się podzielić. Liczę, że ustrzeże Cię to przed wyrywaniem sobie włosów z głowy z powodu frustracji.
Wszystkie serwisy działają, ale plik nie chce się przekopiować z lokalnego systemu plików na Ozone. Podczas kopiowania (polecenie “ozone sh key put /vol1/bucket1/ikeikze2.pdf ikeikze2.pdf”) pojawia się następujący błąd:
Co to oznacza? Nie wiadomo. Wiadomo jedynie, że – mówiąc z angielska – “something is no yes”. W tym celu udajemy się do logów. Tu nie chcę zgrywać ozonowego mędrca, więc powiem po prostu: popróbuj. Problem może być w paru logach, ale z całą pewnością ja bym zaczął od logów datanode. Logi znajdują się w folderze “logs”, w folderze z zainstalowanym Ozonem (tam gdzie jest też folder bin, etc i inne).
Zacznijmy od komunikatu błędu, który można dostać po przejrzeniu logów ze Storage Container Manager (SCM).
ERROR org.apache.hadoop.hdds.scm.SCMCommonPlacementPolicy: Unable to find enough nodes that meet the space requirement of 1073741824 bytes for metada
ta and 5368709120 bytes for data in healthy node set. Required 3. Found 1.
Rozwiązanie: Należy zmienić liczbę replik, ponieważ nie mamy wystarczająco dużo datanodów w klastrze, aby je przechowywać (nie mogą być trzymane na tej samej maszynie). Aby to zrobić należy wyłączyć wszystkie procesy Ozone, a następnie zmienić plik ozone-site.xml. Konkretnie zmieniamy liczbę replik. Poniżej rozwiązanie, które na pewno zadziała, ale niekoniecznie jest bezpieczne – zmieniamy liczbę replik na 1, w związku z czym nie wymaga on wielu nodów do przechowywania replik.
W tym miejscu pokazane jest jak należy stawiać Apache Ozone. Jak widać są dwie ścieżki i tylko jedna z nich nadaje się do czegokolwiek.
W pierwszej stawiamy każdy serwis osobno: Storage Container Manager, Ozone Manager oraz Datanody. Jest to chociazby o tyle problematyczne, że jeśli mamy tych datanodów dużo, to trzeba by wchodzić na każdy z nich osobno.
Na szczęście istnieje też opcja uruchamiania wszystkiego jednym skryptem. W tym celu należy uruchomić plik start-ozone.sh znajdujący się w folderze sbin.
Jednak aby to zrobić, należy najpierw uzupełnić konfigurację. Zmiany są dwie:
Należy dodać kilka zmiennych do pliku ozone-env.sh w folderze “[folder_domowy_ozone]/etc/hadoop“.
Nalezy utworzyć plik workers wewnątrz tego samego folderu co [1].
Zmienne: tu należy dodać kilka zmiennych wskazujących na użytkowników ozona. Sprawa jest niejasna, bo Ozone przeplata trochę nomenklaturę z HDFS. Ja dodałem obie opcje i jest ok.
Po tym wszystkim możemy uruchomić skrypt start-ozone.sh
OM wyłącza się po uruchomieniu klastra
Po uruchomieniu klastra (sbin/start-ozone.sh) Ozone Manager zwyczajnie pada. Kiedy zajrzymy w logi, znajdziemy taki oto zapis:
Ratis group Dir on disk 14dd99c6-de01-483f-ac90-873d71fb5a44 does not match with RaftGroupIDbf265839-605b-3f16-9796-c5ba1605619e generated from service id omServiceIdDefault. Looks like there is a change to ozone.om.service.ids value after the cluster is setup
Były także inne logi, natomiast wiele wskazywało na Ratisa oraz omServiceIdDefault a także ozone.om.service.ids. Jeśli mamy następujący problem, oznacza to, że nasz klaster próbuje automatycznie włączyć tryb HA na Ozon Manager. Ponieważ mi na takim trybie nie zależy (mój klaster jest naprawdę mały i nie miałoby to większego sensu), wprost wyłączyłem HA. Aby to zrobić, należy zmodyfikować ustawienia.
Plik ozone-site.xml (znajdujący się w [katalog ozona]/etc/hadoop/ozone-site.xml)
Oczywiście po zaktualizowaniu ozone-site.xml plik powinien być rozesłany na wszystkie nody, a następnie klaster powinien zostać uruchomiony ponownie. Jeśli chcesz skorzystać z trybu HA, wszystkie (chyba;-)) informacje znajdziesz tutaj.
Przy requestach zwykłego użytkownika (nie-roota) wyskakuje błąd o brak dostępów do logów
A więc wszystko już poszło do przodu, spróbowaliśmy z roota (lub innego użytkownika, którym instalowaliśmy Ozone na klastrze) i wszystko było ok. Przynajmniej do czasu, aż zechcemy spróbować podziałać na innym użytkowniku. Wtedy dostajemy taki oto błąd:
java.io.FileNotFoundException: /ozone/ozone-1.2.1/logs/ozone-shell.log (Permission denied)
at java.io.FileOutputStream.open0(Native Method)
at java.io.FileOutputStream.open(FileOutputStream.java:270)
at java.io.FileOutputStream.<init>(FileOutputStream.java:213)
at java.io.FileOutputStream.<init>(FileOutputStream.java:133)
at org.apache.log4j.FileAppender.setFile(FileAppender.java:294)
at org.apache.log4j.FileAppender.activateOptions(FileAppender.java:165)
at org.apache.log4j.DailyRollingFileAppender.activateOptions(DailyRollingFileAppender.java:223)
(...)
log4j:ERROR Either File or DatePattern options are not set for appender [FILE].
Pocieszające jest to, że błąd ten nie oznacza, że polecenie do Ozone nie zostało wykonane. Oznacza jedynie, że nie mamy uprawnień do pliku z logami Ozone Shell. Żeby powiedzieć dokładniej, nie mamy dostępu do zapisu na tym pliku.
Nie jest to więc błąd stricte “Ozonowy”. Jest za to stricte linuxowy – należy nadać użytkownikowi odpowiednie uprawnienia. Można to zrobić na kilka różnych sposobów. Jeśli Twój klaster, podobnie jak mój, jest jedynie klastrem eksperymentalnym, możesz śmiało nadać uprawnienia zapisu “innym użytkownikom” pliku. Wchodzimy do folderu z logami i wpisujemy następującą komendę:
chmod a+rw ozone-shell.log
Podsumowanie
Apache Ozone to naprawdę ciekawa i – mam nadzieję – przyszłościowa technologia. Musi jednak jeszcze trochę wody w Wiśle upłynąć, aby zyskała popularność oraz dojrzałość HDFSa. Zachęcam jednak do eksperymentowania i dzielenia się tutaj wrażeniami;-)
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Razem możemy więcej!
Apache Ozone to następca HDFS – przynajmniej w marketingowym przekazie. W rzeczywistości sprawa jest nieco bardziej złożona i proste analogie mogą być złudne. Jako, że jestem w trakcie budowy systemu do analizy spółek giełdowych, buduję także nowy, eksperymentalny klaster (czy może – klasterek;-)). Uznałem to za idealny moment, żeby przetestować, bądź co bądź nową technologię, jaką jest Apache Ozone. W kolejnym artykule podzielę się swoimi obserwacjami oraz problemami które rozwiązałem. Zacznijmy jednak najpierw od poznania podstaw, czyli architektury Apache Ozone. Zapraszam!
Czym (nie) jest Apache Ozone?
Jeśli Ozone to następca HDFSa, a HDFS to system plików, to Apache Ozone jest systemem plików prawda? Nie. I to jest pierwsza różnica, którą należy dostrzec. HDFS był bliźniaczo podobny (w interfejsie i ogólnej budowie użytkowej, nie architekturze) do standardowego systemu plików dostępnego na linuxie. Mieliśmy użytkowników, foldery, a w nich pliki, ewentualnie foldery, w których mogły być pliki. Albo foldery. I tak w kółko.
Apache Ozone to rozproszony, skalowalny object store (/storage). Na temat podejścia object storage można przeczytać tutaj. Podstawową jednak różnicą jest to, że Ozone ma strukturę płaską, a nie hierarchiczną. Również, podobnie jak HDFS, dzieli pliki na bloki, także posiada swoje repliki, jednak nie możemy zawierać zagnieżdżonych folderów.
Podstawowa budowa Apache Ozone
Ozone oczywiście jest systemem rozproszonym – działa na wielu nodach (serwerach/komputerach).
Oto podstawowy opis struktury:
Volumes – podobne do kont użytkowników lub katalogów domowych. Tylko admin może je utworzyć.
Buckets – podobne do folderów. Bucket może posiadać dowolną liczbę keys, ale nie może posiadać innych bucketów.
Keys – podobne do plików.
Ozone zbudowany jest z kilku podstawowych komponentów/serwisów:
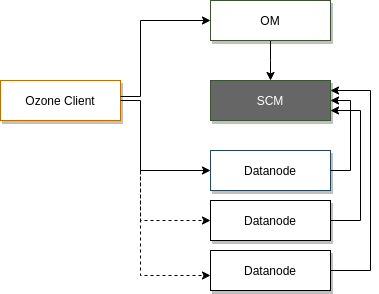
Ozone Manager (OM) – odpowiedzialny za namespacy. Odpowiedzialny za wszystkie operacje na volumes, buckets i keys. Każdy volume to osobny root dla niezależnego namespace’u pod OM (to różni go od HDFSa).
Storage Container Manager (SCM) – Działa jako block manager. Ozone Manage requestuje blocki do SCM, do których klientów można zapisać dane.
Data Nodes – działa w ramach Data Nodes HDFSowych lub w uruchamia samodzielnie własne deamony (jeśli działa bez HDFSa)
Ozone oddziela zarządzanie przestrzenią nazw (namespace management) oraz zarządzanie przestrzenią bloków (block space management). To pomaga bardzo mocno skalować się Ozonowi. Ozone Manager odpowiada za zarządzanie namespacem, natomiast SCM za zarządzanie block spacem.
Ozone Manager
Volumes i buckets są częścią namespace i są zarządzane przez OM. Każdy volume to osobny root dla niezależnego namespace’a pod OM. To jedna z podstawowych różnic między Apache Ozone i HDFS. Ten drugi ma jeden root od którego wszystko wychodzi.
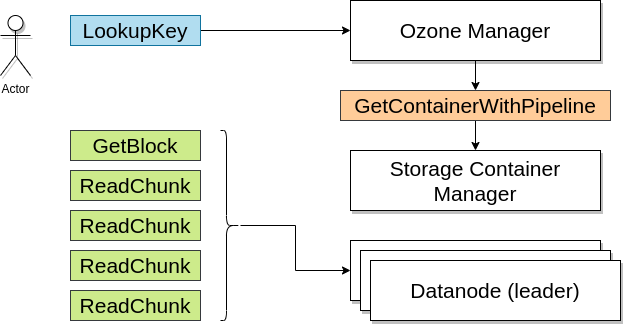
Jak wygląda zapis do Ozone?
Aby zapisać key do Ozone, client przekazuje do OM, że chce zapisać konkretny key w konkretnym bucket, w konkretnym volume. Jak tylko OM ustali, że możesz zapisać plik w tym buckecie,OM zaalokuje block dla zapisu danych.
Aby zaalokować blok, OM wysyła request do SCM. To on tak naprawdę zarządza Data Nodami. SCM wybiera 3 data nody (najprawdopodobniej na repliki) gdzie klient może zapisać dane. SCM alokuje blok i zwraca block ID do Ozone Managera.
Ozone Manager zapisuje informacje na temat tego bloku w swoich metadanych i zwraca blok oraz token bloku (uprawnienie bezpieczeństwa do zapisu danych na bloku) do klienta.
Klient używa tokena by udowodnić, że może zapisać dane na bloku oraz zapisuje dane na data node.
Gdy tylko zapis jest ukończony na data node, klient aktualizuje informacje o bloku w OM.
Jak wygląda odczyt danych (kluczy/keys) z Ozone?
Klient wysyła request listy bloków do Ozone Manager.
OM zwraca listę bloków i tokenów bloków, dzięki czemu klient może odczytać dane z data nodes.
Klient łączy się z data node i przedstawia tokeny, po czym odczytuje dane z data nodów.
Storage Container Manager
SCM jest głównym nodem, który zarządza przestrzenią bloków (block space). Podstawowe zadanie to tworzenie i zarządzanie kontenerami. O kontenerach za chwilkę, niemniej pokrótce, są to podstawowe jednostki replikacji.
Tak jak napisałem, Storage Container Manager odpowiada za zarządzanie danymi, a więc utrzymuje kontakt z Data Nodami, gra rolę Block Managera, Replica Managera, ale także Certificate Authority. Wbrew intuicji, to SCM (a nie OM) jest odpowiedzialny za tworzenie klastra Ozone. Gdy wywołujemy komendę init, SCM tworzy cluster identity oraz root certificates potrzebne do CA. SCM zarządza cyklem życia Data Node.
SCM do menedżer bloków (block manager). Alokuje bloki i przydziela je do Data Nodów. Warto zawuażyć, że klienci pracują z blokami bezpośrednio (co jest akurat trochę podobne do HDFSa).
SCM utrzymuje kontakt z Data Nodami. Jeśli któryś z nich padnie, wie o tym. Jeśli tak się stanie, podejmuje działania aby naprawić liczbę replik, aby ciągle było ich tyle samo.
SCM Certificate Authority jest odpowiedzialne za wydawanie certyfikatów tożsamości (identity certificates) dla każdej usługi w klastrze.
SCM nawiązuje regularny kontakt z kontenerami poprzez raporty, które te składają. Ponieważ są znacznie większymi jednostkami niż bloki, raportów jest wiele wiele mniej niż w HDFS. Warto natomiast pamiętać, że my, jako klienci, nie komunikujemy się bezpośrednio z SCM.
Kontenery i bloki w Ozone(Contrainers and blocks)
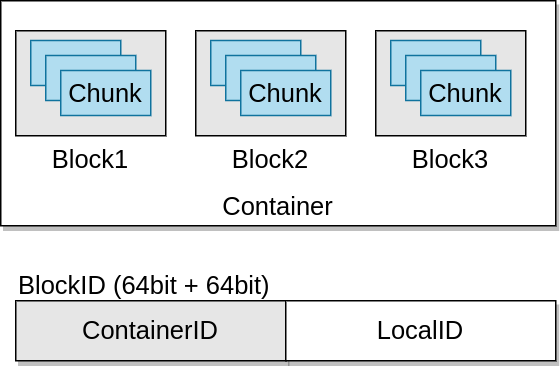
Kontenery (containers) to podstawowe jednostki w Apache Ozone. Zawierają kilka bloków i są całkiem spore (5gb domyślnie).
W konkretnym kontenerze znajdziemy ileś bloków, które są porcją danych. Jednak same bloki nie są replikowane. Informacje o blokch nie są też zarządzane przez SCM – są trzymane tylko informacje o kontenerach i to kontenery podlegają replikacji. Kiedy OM requestuje o zaalokowanie nowego bloku do SCM, ten “namierza” odpowiedni kontener i generuje block id, które zawiera w sobie ContainerIs + LocalId (widoczne na obrazku powyżej). Klient łączy się wtedy z Datanode, który przechowuje dany kontener i to datanode zarządza konkretnym blokiem na podstawie LocalId.
Data Nodes
Data Nody to serwery, na których dzieje się prawdziwa, docelowa magia Ozone. To tutaj składowane są wszystkie dane. Warto pamiętać, że to z nimi bezpośrednio łączy się klient. Zapisuje on dane w postaci bloków. Data node agreguje te dane i zbiera do kontenerów (storage containers). W kontenerach, poza danymi, znajdują się też metadane opisujące je.
Jak to wszystko działa? Kiedy chcemy odczytać plik, uderzamy do OM. Ten zwraca nad listę bloków, która składa się z pary ContainerId:LocalId. To dość chude informacje, ale wystarczą, aby można było udać się do konkretnych kontenerów i wyciągnąć konkretne bloki (LocalId to po prostu unikatowy numer ID w ramach kontenera, czyli w ramach dwóch różnych kontenerów moga być dwa bloki o LocalID=1, natomiast w ramach jednego kontenera nie).
Podsumowanie
Mam szczerą nadzieję, że tym artykułem pomogłem odrobinę zrozumieć architekturę Apache Ozone. Przyznam, że pełnymi garściami czerpałem z dokumentacji. Choć – jestem przekonany – jest to pierwszy polski materiał na temat tej technologii, to z pewnością nie jest ostatni. Jestem w trakcie instalowania Ozone na eksperymentalnym klasterku RDFowym i na bieżąco piszę artykuł o doświadczeniach i błędach, jakie napotkałem. Obserwuj RDF na LinkedIn i zapisz się na newsletter, to nie przegapisz!
Jest rok 2005 – inżynierowie Google publikują przełomowy dokument. “Big Table Paper” opisuje jak zbudowana powinna być baza danych, żeby mogła obsługiwać ogromne ilości danych. Z dokumentu tego natychmiast korzystają dwa ośrodki mające istotny wpływ na rozwój branży. Pierwszy z nich to NSA – amerykańska Agencja Bezpieczeństwa Narodowego, znana powszechnie z olbrzymiego systemu inwigilacji oraz poprzez postać Edwarda Snowdena. Drugi to fundacja Apache wraz ze swoim projektem Hadoop, który jest fundamentem współczesnego Big Data. W NSA powstaje Accumulo, w Apache HBase.
Ta ostatnia baza błyskawicznie zdobywa popularność i pozwala na przechowywanie potężnych ilości danych. Jak działa HBase i jego model? Jak wygląda struktura danych? W kolejnych artykułach weźmiemy pod lupę architekturę oraz różne HBasowe zagwozdki.
HBase – model danych
Zanim przejdziemy do architektury, warto poznać model jaki kryje się za danymi w HBase. Model ten jest bowiem z jednej strony niezbyt intuicyjny, z drugiej sam w sobie bardzo dużo mówi o tym jakie dane powinniśmy trzymać w bazie.
Rodzajów nierelacyjnych baz danych jest całkiem sporo. Gdy będziemy szukać informacji na temat HBase znajdziemy dwa opisy. Po pierwsze – że HBase to baza kolumnowa (column oriented). Po drugie – że to baza typu klucz-wartość (key-value store).
Ogólna budowa struktury HBase
Moim zdaniem znacznie bardziej fortunne byłoby stwierdzenie, że jest to baza zorientowana na column-familie (column familie oriented database) niż kolumnowa. Problem polega na tym, że coś takiego jak column familie oriented w powszechnych metodykach nie istnieje. Najmocniej przemawia jednak do mnie key-value store i to z dwóch powodów.
Po pierwsze – wynika to z Big Table Paper i tak właśnie przedstawia się największa alternatywa HBase, czyli Accumulo. Po drugie – ten model naprawdę ma w swojej strukturze klucz i wartość.
Jak to wygląda w praktyce? Zanim przejdziemy dalej, dwa podstawowe pojęcia:
Namespace – czyli inaczej “baza danych”. Na tej samej instancji możemy mieć bazę związaną ze statusami z Twittera oraz osobną bazę na kwestie finansowe.
Table – czyli swojska tabelka. Tabele są z grubsza tym czym tabelki w innych bazach, czyli pewnym opisem zestawu danych. W “normalnych” bazach tabele mają zawsze kolumny. Tu także, jednak z pewną ważną modyfikacją…
Baza typu klucz-wartość (key-value store)
Zacznijmy od podstawowej rzeczy: wszystkie wiersze w tabeli zbudowane są na zasadzie klucz-wartość. Kluczem jest rowkey, czyli unikatowy w skali tabeli id. Wartością natomiast wszystkie dane zawarte w tym wierszu. Oddaje to dość prosty, poniższy rysunek.
HBase to baza typu klucz-wartość (key-value store).
Żeby zrozumieć dobrze na czym naprawdę polega struktura danych w HBase należy wziąć pod lupę owo “value”. Można spodziewać się, że albo siedzi tam jedna, konkretna wartość (np. liczba, tekst itd), albo że spotkamy tam kolumny. Otóż… pudło! Owszem, kolumny tam znajdziemy, ale niekoniecznie tak bezpośrednio.
W HBase kolumny pogrupowane są w “rodziny”, czyli column-families (cf). Dopiero pod cf znajdują się określone kolumny. I teraz uwaga! Znajdują się, jednak w żaden sposób nie są wymuszone, czy zdefiniowane w strukturze tabeli. Pojedynczy wiersz ma następującą strukturę.
Struktura wierszy tabeli w Apache HBase
Kolumny jednak dodawane są podczas… no właśnie, podczas dodawania konkretnego wiersza. Na etapie schematu (schemy) wymuszone mamy jedynie rowkey oraz column families. Efekt jest taki, że każdy wiersz może mieć inne kolumny (choć muszą mieścić się w ramach tych samych column families). Taka struktura ma oczywiście swoje wady – a konkretnie potencjalny bałagan. Należy bardzo uważać podczas pracy na takich danych, aby nie starać się “na siłę” odwołać do kolumn których może nei być.
Z drugiej strony ma to jednak daleko idące zalety, szczególnie w świecie Big Data. Można wykorzystać HBase jako zbiornik na dane, które są delikatnie ustrukturyzowane. Dane, które mają bardzo ogólną strukturę, a w środku mogą się nieco różnić. To pozwala umieszczać na przykład dane w pierwszym kroku ETL (extract, zaraz po zaciągnięciu ze źródła, z delikatnym “retuszem”).
Poznaj HBase dokładniej i zacznij z niego korzystać
To wszystko! Dzisiejszy artykuł bardzo krótki, jedynie wprowadzający do tematyki HBase. Tak naprawdę stanowi on niezbędną podstawę pod kolejny, na temat architektury HBase. Koniecznie zapisz się na nasz newsletter, aby nie przegapić;-).
Jeśli chcesz poznać HBase od podstaw, pod okiem specjalisty –zapraszam na nasze szkolenie. Nie tylko krok po kroku w usystematyzowany sposób poznasz jak obsługiwać HBase. Zrobisz także dużo ciekawych ćwiczeń na prawdziwej infrastrukturze Big Data, co znacząco przybliży Cię do świata realnego. Przekonaj swojego szefa i rozpocznij swoją przygodę z HBase!
Na dziś to tyle – jeszcze raz zachęcam do newslettera i powodzenia z HBase!
Inflacja po raz pierwszy (od dawna) weszła “pod strzechy” – nie jest już jedynie tematem dyskusji eksperckich. Wręcz przeciwnie – od kilku miesięcy jest bohaterką pierwszych stron gazet w całym kraju – z brukowcami włącznie. Powodem jest znaczne przyspieszenie utraty wartości waluty, co w przypadku naszej historii wzbudza szczególnie nieprzyjemne skojarzenia. Dodatkowo niektórzy zarzucają stronie rządowej, że oficjalna inflacja jest zaburzona.
Chciałbym dzisiaj zaproponować pewne rozwiązanie, które pomogłoby nam w analizie inflacji, a co za tym idzie – w odpowiedniej kontroli nad nią. Wszystko co poniżej to pewna ogólna wizja, która może posłużyć jako inspiracja. Jeśli jest chęć i zapotrzebowanie, bardzo chętnie się w tą wizję zagłębię architektonicznie i inżyniersko. Zachęcam także do kontaktu, jeśli TY jesteś osobą zainteresowaną tematem;-).
Krótka lekcja: jak liczona jest inflacja?
Czym jest inflacja?
Zanim przejdziemy do rozwiązania, zacznijmy od problemu. Czym jest inflacja i jak liczy ją GUS? Przede wszystkim najważniejsze to zrozumieć, że inflacja to spadek wartości pieniądza w czasie. Dzieje się tak w sposób praktyczny poprzez wzrost cen. Za ten sam chleb, wodę – musimy zapłacić więcej. I teraz to najważniejsze: inflacja jest inna dla każdego z nas. Każdy z nas ma bowiem inny portfel.
Jeśli zestawimy samotnego programistę oraz rodzinę wielodzietną, gdzie Tata zarabia jako architekt a Mama jako tłumaczka, ich budżety bedą zupełnie inne. Nawet jeśli zarabiają podobne kwoty, w rodzinie większy udział prawdopodobnie będzie na pieluchy, przedmioty szkolne i parę innych rzeczy. W przypadku młodego singla z solidną pensją, do tego z rozrywkowym podejściem do życia, znacznie większy procent budżetu zajmie alkohol, hotele, imprezy itd. Jeśli ceny alkoholi pójdą w górę o 40%, dla niektórych inflacja będzie nie do zniesienia, dla innych z kolei może nie zostać nawet zauważona.
Jak liczone jest CPI (inflacja konsumencka)?
Aby zaradzić tego typu problemom, GUS wylicza coś takiego jak CPI (Consumer Price Index) – indeks zmiany cen towarów i usług konsumpcyjnych. W skrócie mówimy inflacja CPI, czyli inflacja konsumencka. Warto zaznaczyć tutaj jeszcze, że zupełnie inna może być inflacja odczuwana na poziomie budżetów firm (a właściwie dla różnych firm jest także oczywiście różna).
Nie będziemy się tutaj wgryzać zbyt mocno w to jak dokładnie wylicza się inflację CPI. Skupimy się jedynie na paru najważniejszych rzeczach, które przydadzą nam się do późniejszej odpowiedzi na nasz inflacyjny problem;-). Dla zainteresowanych polecam solidniejsze omówienia:
Na nasze potrzeby powiedzmy sobie bardzo prosto, w jaki sposób GUS liczy CPI. Potrzeba do tego podstawowej rzeczy, czyli koszyka inflacyjnego. Taki koszyk to grupy towarów, które podlegają badaniu. GUS oblicza to na podstawie ankiet wysyłanych przez 30 000 osób. Już tutaj powstaje pewien problem – ankiety te mogą być wypełniane nierzetelnie.
Następnie, jeśli mamy już grupy produktów, musimy wiedzieć jak ich ceny zmieniają się w skali całego kraju. Aby to zrobić, wyposażeni w tablety ankieterzy, od 5 do 22 dnia każdego miesiąca, ruszają do akcji – a konkretnie do wytypowanych wcześniej punktów (np. sklepów spożywczych) w konkretnych rejonach. W 2019 roku badanie prowadzono w 207 rejonach w całej Polsce.
Big Data w służbie jej królew… to znaczy w służbie Rządu RP
Taka metodologia prowadzi do bardzo wielu wątpliwości. Badanie GUSu zakrojone jest na bardzo szeroką skalę. Mimo to jednak wciąż są to jedynie wybrane gospodarstwa oraz wybrane punkty sprzedaży. Chcę tutaj podkreślić, że nie podejrzewam naszych statystyków o manipulacje. Może jednak dałoby się zrobić tą samą pracę lepiej, bardziej precyzyjnie i znacznie mniejszym kosztem?
Cyfryzacja paragonowa – czyli jak Rząd przenosi nasze zakupy do baz danych?
Zanim przejdziemy dalej, powiedzmy najpierw coś, z czego być może większość z nas sobie nie zdaje sprawy. Ostatnie lata to stopniowe przechodzenie z tradycyjnych kas fiskalnych na kasy wirtualne oraz online. Na potrzeby artykułu nie będę wyjaśniał różnic. To co nas interesuje to fakt, że oba typy kas, zakupy raportują bezpośrednio do Rządu. Na ten moment objęta jest tym stanem rzeczy gastronomia, ale docelowo ma to objąć (wedle mojej wiedzy) także inne sektory posługujące się paragonami.
Jak zbudować system liczący inflację?
Przenieśmy się mentalnie do momentu, w którym każda, lub niemal każda sprzedaż jest odnotowywana przez państwo i zapisywana w tamtejszej bazie danych (najprawdopodobniej nierelacyjnej). Można to wykorzystać, aby zbudować system, który pozwoli nam liczyć inflację pozbawioną potrzeby wysyłania armii ankieterów. Co więcej – pozwoli to zrobić dokładniej oraz da nam potężne narzędzie analityczne!
Bazy danych / Storage
Przede wszystkim – zakładam, że wszystkie dane trzymane są w jakiejś nierelacyjnej bazie danych – na przykład w Apache HBase. Może to być jednak także rozproszony system plików, jsk HDFS. W takiej bazie powinny być trzymane wszystkie dane dotyczące transakcji – paragony, faktury, JPK itd. Osobną sprawą pozostają informacje dotyczące firm i inne dane, które są bardziej “ogólne” – dotykają mniejszej liczby podmiotów i nie są tak detaliczne.
W nowoczesnym systemie do liczenia inflacji Spark odegrałby kluczową rolę
Te dane, ze względu na niewielką liczbę i bardzo klarowną strukturę, można trzymać w bazie relacyjnej (np. PostgreSQL). Można jednak także jako osobną tabelę HBase, choć z przyczyn analitycznych (o których potem) znacznie lepiej będzie zrobić to w bazie relacyjnej. Można także zastosować rozwiązanie hybrydowe – wszystkie dane dotyczące firm trzymać w bazie nierelacyjnej, jako swoistym “magazynie”, natomiast pewną wyspecyfikowaną, odchudzoną esencję – w bazie relacyjnej.
Dodatkowo zakładam, że koszyk inflacyjny jest już wcześniej przygotowany. Da się ten proces uprościć poprzez informatyzację ankiet – jest to już zresztą robione (według wiedzy jaką mam). Taki koszyk można trzymać w bazie relacyjnej, ze względu na relatywnie niewielką liczbę danych (W 2021 roku zawierał on 12 grup produktów. Nawet jeśli w każdej z nich byłoby parę tysięcy produktów, liczby będą sięgać maksymalnie kilkudziesięciu tysięcy, niezbyt rozbudowanych rekordów).
W dalszej części dodam jeszcze możliwość tworzenia kolejnych koszyków i w takiej sytuacji prawdopodobnie należałoby już je wydzielić do osobnej bazy nierelacyjnej. W dalszym ciągu jednak ogólne adnotacje mogłyby pozostać w bazie relacyjnej (tak, żeby można było np. sprawnie wyciągnąć dane z HBase po rowkey, czyli id).
Jeśli zdecydujemy się na zastosowanie bazy row-key, jak HBase, uważam że i tak zaistnieje potrzeba wykorzystania HDFS (może być tak, że w HBase będzie wygodniej pierwotnie umieszczać pliki paragonowe). Będziemy tu umieszczać kolejne etapy przetworzonych danych z konkretnych okresów.
Jeszcze inną opcją jest zastosowanie Apache Kudu, który mógłby nieco zrównoważyć problemy HBase i HDFS i zastąpić oba byty w naszym systemie. Jak widać, opcji jest dużo;-)
Przygotowanie danych
Kiedy mamy już dane zebrane w przynajmniej dwóch miejscach, powinniśmy je przygotować. Same z siebie stanowią jedynie zbiór danych, głównie tekstowych. W drugim etapie należy te dane przetworzyć, oczyścić i doprowadzić do postaci, w jakiej ponownie będziemy mogli dokonać już finalnej analizy inflacji.
Finałem tego etapu powinny być dane, które będą pogrupowane tak, żebyśmy mogli je później wykorzystać. Wstępna, proponowana struktura wyglądać może następująco:
Okres badania
Grupa produktów
Punkt sprzedaży
towar
Musimy więc wyciągnąć surowe dane (z HBase), przetworzyć je, a następnie zapisać jako osobny zestaw – proponuję tu HDFS. Jak to uczynić? Możemy do tego celu wykorzystać Apache Spark oraz connector HBase Spark przygotowany przez Clouderę. Następnie dane muszą być poddane serii transformacji, dzięki którym dane:
Zostaną wydzielone jako osobne paragony
Zostaną podzielone na produkty
Poddane będą oczyszczeniu z wszelkich “śmieci” uniemożliwiających dalszą analizę
Wykryta zostanie grupa produktów dla każdego z nich
Pogrupowane zostaną po grupie produktów oraz okresie
Na końcu dane zapisujemy do HDFS. Wstępna struktura katalogów:
Dane przygotowane
Dane całościowe
okres
Tutaj umieszczamy plik *.parquet lub *.orc
Liczenie inflacji
Skoro mamy już przygotowane dane, czas policzyć inflację. Do tego celu także wykorzystamy Apache Spark, dzięki któremu możemy w zrównoleglony sposób przetwarzać dane. W najbardziej ogólnym kształcie sprawa wygląda dość prosto:
Łączymy się z bazą danych (relacyjną), w której trzymamy konkretny koszyk
Wybieramy okres za jaki chcemy policzyć inflację
Pobieramy dane z HDFS/Kudu, które okresem odpowiadają [2].
Wybieramy grupy produktów zgodne z koszykiem [1]
Przeliczamy inflację za pomocą danych, które są już solidnie przygotowane.
I teraz ważne: efekt zapisujemy do relacyjnej bazy danych.
Analiza
Czemu akurat do relacyjnej bazy danych? Odpowiedź wydaje się oczywista:
Dane będą niewielkie – choć od raz umożna powiedzieć, że z naszego procesu można wycisnąć więcej niż tylko wynik 6.8% 😉 – jest też sporo rzeczy przy okazji, takie jak jakie produkty wzrosły najmocniej, w jakich regionach, co ma największą zmiennośći itd.
Dane będą solidnie ustrukturyzowane
Dane umieszczone w relacyjnych bazach pozwalają na znacznie lepszą i prostszą analizę.
I właśnie ten trzeci punkt powinien nas zainteresować najmocniej. Można bowiem na klastrze zainstalować jakieś narzędzie BI, spiąć z bazą i… udostępnić analitykom. Takim narzędziem może być (znów open sourcowy) Apache Superset. Przynajmniej na dobry początek. W drugim rzucie należałoby się pokusić o zbudowanie dedykowanej aplikacji analitycznej. To jednak można zostawić na później. Na etap, w którym analitycy będą już zaznajomieni z systemem i będą mogli włączyć się w czynny proces budowy nowego narzędzia.
Rozwój
Wyżej opisałem podstawowy kształt systemu do badania inflacji. Warto jednak nie zatrzymywać się na tym i pomyśleć jak można tą analizę wynieść na wyższy poziom. Podstawową prawdą na temat inflacji jest to, że każdy ma swoją, więc nie da się dokładnie obliczać jak pieniądz traci na wartości. Cóż… dlaczego nie możnaby tego zmienić? Wszak mając do dyspozycji WSZYSTKIE (oczywiście upraszczając) dane, można zrobić “nieskończenie wiele” koszyków inflacyjnych.
Czym mogłoby być te koszyki inflacyjne? Kilka propozycji.
Dlaczego nie wykorzystać rozwoju technologii Big Datowych do podnoszenia świadomości finansowej oraz obywatelskiej Polaków? Niech każdy będzie mógł na specjalnym portalu wyklikać swój własny koszyk i regularnie otrzymywać powiadomienia dotyczące swojej własnej inflacji. Takie podejście byłoby bardzo nowatorskie i z pewnością wybilibyśmy się na tle innych państw.
Koszyki mogą powstawać dla różnych grup społecznych. Dzięki temu można będzie dokładniej badać przyczyny rozwarstwienia społecznego, niż jedynie osławiony współczynnik Giniego, czy także inne, powiedzmy sobie szczerze – skromne narzędzia, na podstawie których wyciągane są bardzo mocne dane.
Koszyki dla firm – oczywistym jest, że firmy mają znacząco różny koszyk od ludzi. Jest oczywiście inflacja przemysłowa (PPI), natomiast dotyczy ona produkcji przemysłowej (i to w dośćwąskim zakresie). Dzięki wyborowi produktów w “naszym systemie” można będzie obliczyć także jak bardzo wartość pieniądza spada dla różnych rodzajów firm.
Potencjalne korzyści
Powyżej opisałem przykładowy system, który pozwoliłby nam wynieść analizę inflacji na zupełnie inny poziom. Poniżej chciałbym zebrać w jedno miejsce kilka najważniejszych korzyści, jakie niosłyby takie zmiany:
Mniejsze koszty – cykliczne uruchamianie jobów mających na celu sprawdzenie inflacji to koszt znacznie mniejszy, niż utrzymywanie armii ankieterów.
Dokładniejsza inflacja – precyzja liczenia inflacji weszłaby na zupełnie inny poziom. Oczywiście na początku należałoby przez kilka lat liczyć w obu systemach, aby sprawdzić jak bardzo duże są różnice.
Różne modele inflacji – a więc koszyki o których pisałem powyżej, które spowodują, że przestanie być prawdziwa teza o tym, że “liczenie prawdziwej inflacji nie jest możliwe”.
Regionalizacja inflacji – Inflacja inflacji nie jest równa. Zupełnie inaczej ceny mogą się kształtować w różnych województwach. Również i to mógłby liczyć “nasz system”.
Większe możliwości analityczne – stopy nie są jedynym narzędziem, który można użyć w walce z inflacją. Ekonomiści wskazują, że poza wysokością stóp procentowych także inne czynniki wpływają na inflację. Są to m.in. skala dodruku pieniądza, rozwój świadczeń socjalnych, regulacje gospodarcze czy wysokość podatków pośrednich. Dzięki Big Datowemu systemowi, Rząd zyskałby znacznie większe możliwości analityczne do śledzenia wpływu swoich zmian na gospodarkę.
Wyższe morale i poczucie, że państwo gra “w pierwszej lidze”– unowocześnia swoje działanie na poziom niespotykany w innych krajach.
Potencjalne zagrożenia
Rozwój zaawansowanych systemów to oczywiście także zagrożenia. O tych najważniejszych poniżej:
Możliwości analityczne muszą wiązać się z większą inwigilacją – i jest to chyba największy problem. Im większe możliwości analizy chcemy sobie zafundować, tym głębiej trzeba zinfiltrować życie obywateli. Oczywiście przed infiltracją współcześnie uciec się nie da, ale należy zawsze mieć na uwadze mądre wyważanie.
Koszt utrzymania systemu – To system zbierania bardzo dużych danych i analizy ich. Wymagać będzie zaawansowanych klastrów obliczeniowych oraz odpowiedniego zespołu administracyjnego. Na pensjach – dodajmy – zdecydowanie rynkowych, nie urzędniczych.
Kwestia bezpieczeństwa – czasami zapominamy, że informatyzacja państwa to problem w bezpieczeństwie danych. Jeśli jesnak dane dotyczące zakupów i tak miałyby być zbierane – czemu ich nie wykorzystać?
Big Data to nasza wielka szansa – także w sektorze rządowym
Jesteśmy Państwem, które w wielu miejscach wiecznie próbuje nadgonić resztę (choć w wielu także tą resztę przegoniło). Big Data może pozwolić na działać lepiej, szybciej, precyzyjniej i… taniej. Wykorzystajmy tą szansę. Za nami poglądowy pomysł na to jak zbudować jeden z takich systemów, które mogłyby pomóc nam budować nowoczesne państwo. Jeśli chcesz dowiadywać się o innych pomysłach, które ukazują Big Data w odpowiednim kontekście, zapraszam na nasz profil LinkedIn oraz do zapisania się na newsletter RDF. Do zobaczenia na szlaku BD!;-)
![Hadoop i kod (Java API). Krótki poradnik od 0 [wideo] [jesień]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/11/youtube-miniatura.jpeg "Hadoop i kod (Java API). Krótki poradnik od 0 [wideo] [jesień]")
![HDFS w praktyce – poradnik DLA POCZĄTKUJĄCYCH (HDFS Shell i budowa) [wideo] [jesień]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/10/HDFS-Youtube.jpeg "HDFS w praktyce – poradnik DLA POCZĄTKUJĄCYCH (HDFS Shell i budowa) [wideo] [jesień]")
![Co to jest (i jak działa) Hadoop? DLA KOMPLETNIE ZIELONYCH [Wideo] [jesień]](https://blog.riotechdatafactory.com/wp-content/uploads/2022/10/Youtube.jpeg "Co to jest (i jak działa) Hadoop? DLA KOMPLETNIE ZIELONYCH [Wideo] [jesień]")