Do tej pory poświęciłem dwa artykuły na dylemat cloud vs on-premise, czyli pytanie o to czy nasza infrastruktura techniczna powinna być serio nasza i stać u nas w serwerowni (albo – jak mój eksperymentalny klasterek – pod biurkiem;-)). Być może powinna zostać uruchomiona na maszynach wirtualnych wykupionych w ramach usług chmurowych? Nie ma jednej dobrej odpowiedzi na te tematy. Dzisiaj chciałbym jednak skomplikować temat jeszcze bardziej. Porozmawiajmy na temat tego czym jest hybrid cloud! No to Big Coffee w dłoń i ruszamy.
Zanim przejdziemy do pojęcia hybrid cloud, wyjaśnijmy pojęcie które będzie nam potrzebne – czyli private cloud, chmura prywatna. Jest to taki rodzaj usługi chmurowej, który odznacza się daleko idącym wydzieleniem zasobów sprzętowych na potrzeby klienta. Może to być zarówno przechowywane w miejscu jego pracy jak i u dostawcy chmurowego. To ostatnie jednak z zastrzeżeniem, że zasoby sprzętowe powinny realnie być oddzielone od reszty.
Stoi to w opozycji do chmury publicznej (ang. public cloud), gdzie dzielimy de facto zasoby z bardzo wieloma innymi użytkownikami (przy czym bazujemy na utworzonych dla nas maszynach wirtualnych lub kontach w konkretnych serwisach). Takie podejście pozwala zachować większe bezpieczeństwo i spełnić wymogi niektórych regulatorów.
Istnieje jeszcze pojęcie Virtual Private Cloud (VPC), czyli wirtualnej chmury prywatnej. Jest to de facto klasyczna chmura publiczna, która po prostu jest oddzielona logicznie od innych “uczestników” chmury (chodzi o tenantów;-)). Moim zdaniem jednak takie podejście ciężko nazywać “prywatnym” – nie spełnia bowiem podstawowych założeń chmury prywatnej, czyli udostepnienia klientowi zasobów “na wyłączność”, dzięki czemu mógłby osiągnąć większą kontrolę i bezpieczeństwo.
Oczywiście chmura to nie tylko wirtualne maszyny. Powstaje pytanie, jakie usługi może dostarczać dostawca chmurowy w ramach chmuryprywatnej? Odpowiedź poniżej.
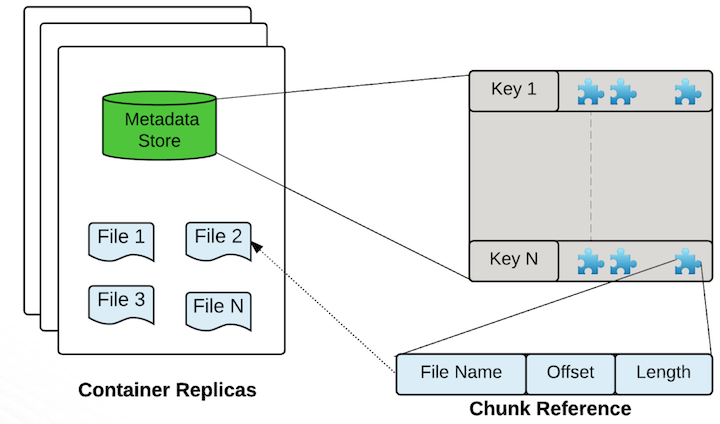
Infrastructure as a Service (IaaS) – A więc chmura przejmuje wirtualizację, serwery, storage i networking. Klient natomiast dba o resztę (system operacyjny, middleware, runtime, dane i aplikacje)
Platform as a Service (PaaS) – W tym przypadku po stronie klienta zostają już tylko dane i aplikacje.
Cały podział (razem z on-premise oraz SaaS) poniżej. Grafika pochodzi od Microsoftu i jest używana do opisu Azure.
Hybrid Cloud
Hybryda, jak to hybryda, łączy różne style. W tym przypadku łączymy public cloud z private cloud lub z on-premise. Jeśli używasz kombinacji tych trzech składników w jakiejkolwiek konfiguracji – znaczy, że Twoja infrastruktura jest hybrydowa.
Jakie są zalety rozwiązania hybrydowego? Otóż – przede wszystkim jest to pewna zwinność, elastyczność. Jak już wykazywałem w dwóch artykułach na temat dylematu “cloud vs on-premise” – nie ma jednoznacznie dobrego lub złego rozwiązania. Każde wiąże sięz pewnymi wadami i zaletami. Jeszcze lepiej byłoby stwierdzić, że każde powinno być dostosowane do określonej specyfiki danego problemu. Przykładowo – w rozwiązaniu on-premise problemem może być koszt personelu potrzebnego do serwisowania infrastruktury. Jeśli chodzi o chmurę, w niektorych, szczegolnie wrażliwych przypadkach problemem może być pytanie o to gdzie dokładnie dane są przechowywane (np. wrażliwe dane rządowe).
Decydując się na mix infrastruktury, zachowujemy elastyczność i zwinność. Możemy dostosować wady i zalety rozwiązań tak, aby finalna konstrukcja była idealnie dopasowana do charakterystyki naszego projektu.
Kolejną zaletą hybrid cloud może być także większa efektywność kosztowa. Możemy zauważyć na przykład, że dane chcemy co prawda trzymać na własnych maszynach, jednak przetwarzanie ich może czasami osiągać zawrotne wymagania jeśli chodzi o zasoby. W takiej sytuacji możemy przechowywać je u siebie, natomiast przetwarzać w chmurze, gdzie przydzielanie zasobów może odbywać się niezwykle prosto i dynamicznie.
Podsumowanie
Nie ma jednej prostej odpowiedzi na pytanie “co jest lepsze: chmura czy rozwiązania on-premise?”. Wszystko ma nie tylko swoje wady i zalety, ale i charakterystykę, która musi zostać dopasowana do problemu. Warto jednak pamiętać, że istnieją nie tylko dwie skrajne opcje, ale także rozwiązania hybrydowe. Można dzięki nim manipulować “suwakiem” kosztów, bezpieczeństwa, wygody itd. w inny sposób, niż zastanawiając się jedynie nad podstawowym wyborem.
Z pewnością będziemy kontynuować temat – dziś jedynie zajawka;-). Jeśli nie chcesz przegapić zmian, zapisz się na newsletter i obserwuj nasz profil na LinkedIn. Powodzenia!
Ostatnio miałem okazję rozmawiać z koleżanką, z którą pracuję w jednym projekcie. Być może warto dodać, że jest to projekt medyczno-genetyczny, bo rozmowa zeszła na kwestie etyczne. Zadała niezwykle ważne pytanie: “Czy ludzie pracujący w IT, ale przede wszystkim w Big Data, zdają sobie sprawę z tego w jak ważnej branży pracują? Czy wy myślicie o jakiś aspektach etycznych swojej pracy?”. No cóż – ja myślę od zawsze, kwestia wiary i wychowania. Czy jednak każdy myśli? Zapraszam dzisiaj do innego artykułu niż zwykle. Zaczniemy lekko łatwo i przyjemnie, ale to dopiero początek nowych tematów na blogu RDF;-). Zapraszam serdecznie;-)
Waga Big Data we współczesnym świecie
Dziś Big Data stało się moim zdaniem rdzeniem współczesnego świata. A jeśli jeszcze się nie stało, to zdecydowanie i bezpowrotnie staje się nim. To dzięki Big Data świat idzie do przodu i to dzięki tej branży może się rozwijać.
Ma to jednak swoje mroczne strony. Wszechobecna inwigilacja, przewidywanie każdego aspektu naszego życia, wojna informacyjna (i dezinformacja) na niespotykaną nigdy wcześniej skalę. Uzależnienia całych pokoleń od elektroniki i mediów społecznościowych, oszustwa finansowe, wielkie manipulacje społeczno-polityczne. Mógłbym wymieniać w nieskończoność.
Czy oznacza to, że żyjemy w najbardziej mrocznych czasach w historii? Moim zdaniem nie, choć złe tematy są znacznie, znacznie bardziej “klikalne”. Dobro bardzo często jest ciche, jednak robi ogromną i trwałą robotę. Dzisiaj nieśmiało chciałbym tym artykułem rozpocząć tematykę etyki w Big Data. Zacznijmy od prostego i przyjemnego tematu – a konkretnie kilku przykładów dobrego wykorzystania inteligentnego przetwarzania dużych danych.
3 projekty, które wykorzystują duże dane dla słusznej sprawy
Cloudera co roku wyłania 3 organizacje w ramach swojego konkursu “Data for good”. Oczywiście są to organizacje związane z Clouderą (poprzez korzystanie z ich produktów). Nie zmienia to jednak postaci rzeczy, że mamy tu znakomite przykłady inteligentnego zastosowania obsługi dużych danych do poprawy czegoś w naszym świecie. Zapraszam na krótki opis każdej z organizacji.
Union Bank (Union Bank of Philippines)
Tło całej sprawy to oczywiście COVID, który doprowadził do ciężkiej sytuacji ogromnej rzeszy Filipińczyków. Bardzo wielu z nich musiało coś zrobić, aby przetrwać ciężki czas ledwo wiążąc koniec z końcem. Jednym z podstawowych pomysłów jest pożyczka. Problem? Ponad 70 milionów osób było tam pozbawionych konta bankowego, przez to bank nie miał możliwości prostego sprawdzenia zdolności kredytowej.
Bank Filipiński skorzystał z Cloudera Data Science Workbench. Utworzyli oni ukierunkowany na dane system, który bazując na algorytmach AI pozwolił na szybszą predykcję swoich klientów – ich potencjalnego ryzyka i przydzielanych punktów kredytowych.
W rezultacie wskaźnik akceptacji kredytu wzrósł do 54%. Wzrosły też zyski banku, a co istotniejsze – miliony Filipińczyków mogły przetrwać kryzys. Oczywiście, tak, można zauważyć, że pożyczka nie jest najszczęśliwszym sposobem na utrzymanie się na powierzchni. Można też zwrócić uwagę, że końcem końców chodziło po prostu o zysk.
Tylko, że czasem kredyt to po prostu mniejsze zło. Jeśli zaś chodzi o zysk – cóż. Czy nie jest najlepszą sytuacja, w której zysk oparty jest o świadczenie naprawdę potrzebnych komuś usług?
Keck Medicine of USC
Druga organizacja która otrzymała wyróżnienie w “Data for good” to Keck Medicine of USC. Jest to przedsiębiorstwo medyczne Uniwersytetu Południowej Kalifornii. W tym przypadkiem tło jest chyba jeszcze “cięższe” niż poprzednio. Chodzi mianowicie o uzależnienia od opioidów. Według HHS, w 2019 roku ok 10.1 mln osób (w USA) nadużywało leków opioidowych. W 2018 roku natomiast opioidy były odpowiedzialne za 2/3 zgonów związanych z przedawkowaniem narkotyków.
W Keck Medicine od USC uznali, że spora część uzależnień może wynikać ze złych standardów (lub nie trzymania się dobrych praktyk) przypisywania środków przeciwbólowych przez lekarzy (najczęściej po operacjach lub w przypadku leczenia szczególnie przewlekłych, wyniszczających stanów). W związku z tym utworzony został projekt mający na celu wgląd w praktyki lekarzy. Centralnym punktem był Data Lake, który eliminował potencjalne błędy manualnego zbierania danych. Dodatkowo pozwalał spojrzeć “z lotu ptaka” na dane z całej organizacji.
Dzięki zaawansowanej analityce, naukowcy i lekarze mogą wykrywać najbardziej ryzykowne sytuacje i podjąć odpowiednią reakcję, taką jak edukacja. Dzięki systemowi organizacja może lepiej zadbać o swoich pacjentów, unikając uzależnień zamiast w nie (przypadkowo) wpędzać.
National organisation for rare disorders (National Marrow Donor Program)
Tło to tym razem nowotwory krwi, takie jak białaczka, na które co 10 minut ktoś umiera (tak, wciąż nic wesołego). Wielu z tych ludzi mogłoby żyć, gdyby znaleźli się dawcy na przeszczep szpiku kostnego. Niestety, u 70% osób nie ma odpowiednich osób do przeszczepu wśród najbliższej rodziny.
National Organisation for rare disorders utworzyła National Marrow Donor Program, który ma na celu kojarzenie ze sobą osób potrzebujących i dawców. W ich bazach jest obecnie zarejestrowanych 44 miliony osób. Jak nietrudno się domyślić, sprawne przeszukiwanie bazy to robota dla Big Data. Organizacja razem z Clouderą utworzyła odpowiedni system, dzięki czemu możliwe jest przeszukiwanie milionów rekordów w minutę.
Warto dodać, że na ten moment program pomógł uratować życie ponad 6 600 biorcom szpiku. To absolutnie rewelacyjna wiadomość!
Podsumowanie
Dziś zdecydowanie inny artykuł niż przeważnie. Tak już jest, że Big Data jest medalem, który ma bardzo, bardzo wiele stron. Chciałbym pisać tu o możliwie wielu z nich. Mam nadzieję, że dzisiejszy opis trzech organizacji które robią z danymi coś bardzo, bardzo sensownego, zainspiruje do innego myślenia.
Zostaw komentarz, podaj artykuł dalej i… cóż, koniecznie dołącz do nas na LinkedIn oraz newsletterze. Zostańmy w kontakcie dłużej i razem budujmy polską społeczność Big Data!
Wielokrotnie na tym blogu tłumaczyłem zawiłości Big Data od podstaw (nie oszukujmy się – sam wielokrotnie pisałem to także dla siebie, chcąc usystematyzować wiedzę). Nie tylko technicznie, ale i “z lotu ptaka”, biznesowo. Zawsze żałowałem, że muszę to robić “po łebkach”, w skondensowanej formie, wyrywkowo. Czym innym jest przedstawić jakieś okrojone zagadnienie a czym innym móc wyjaśnić kontekst, zagłębić się, pozwolić sobie na więcej, szerzej, głębiej. Postanowiłem dołączyć do bloga RDF jeden element, który rozwiąże ten problem. I jestem szalenie ciekawy, co o tym sądzisz!
UWAGA! Pierwszy polski ebook o Big Data już dostępny! Zapisz się na listę newslettera i podążaj “Szlakiem Big Data”. Więcej tutaj.
Ebook o Big Data. Po polsku!
No właśnie. Idealnym miejscem aby się zagłębić w temat i przedstawić coś od A do Z jest książka. A najlepiej, żeby była to książka powszechna, dostępna za darmo dla każdego. No więc co? No więc ebook!
Celem ebooka będzie wprowadzenie do branży Big Data. Od historii, filozofii, przez przegląd technologii i architektur. Na słowniczku skończywszy, o. Czy ma wyczerpać temat? Odpowiedź jest oczywista – nie da się go wyczerpać. Ja, po kilku latach naprawdę wytężonej pracy w BD, czuję się… jak kompletny świeżak.
Cel: traktuję Ebooka raczej jako furtkę do świata Big Data. Ja wyjmuję klucz i ją otwieram. Potem Ty dalej już wiesz gdzie iść.
Całość będzie napisana po polsku. RDF powstał po to, żeby szkolić i doradzać tu, w Polsce. Blog jest tego emanacją i podstawowym elementem budowy naszej społeczności Big Data.
Jak będzie zbudowany ebook o Big Data? (Spis Treści)
Przejdźmy do konkretu. Co znajdziesz w ebooku? Pomyślałem o kilku częściach:
Miękkie wprowadzenie do Big Data – czyli opis jak to się wszystko zaczęło (historia) oraz filozofia myślenia w branży. Nie pomijaj tego! Dzięki temu rozdziałowi zobaczysz jak zaczęła toczyć się ta kula śnieżna i… nauczysz się myśleć “po bigdatowemu”.
Opis kluczowych technologii – oczywiście nie będziemy tu robić kursów;-). Poznasz tam zgrubne zestawienie tego jaka technologia służy do jakiego celu. Już bardziej techniczne, ale bez przesady.
Rozważania architektoniczne – wbrew pozorom przyda się nie tylko inżynierom, ale także menedżerom. Do głębszego zrozumienia. Choć, powiedzmy szczerze, Ci ostatni mogą ten rozdział “przelecieć wzrokiem”.
Odwieczny dylemat: cloud czy on-premise? Czyli pytanie o to, czy samodzielnie tworzyć infrastrukturę czy skorzystać z dostawców.
Słowniczek – gdyby coś w trakcie było niezbyt zrozumiałe. Tylko nie zakuwaj za dużo!
Jestem jednak otwarty na różne sugestie. Mogę to zarówno pociąć jak i dobudować.
Zdjęcie bardzo poglądowe;-) Okładkę ebooka o Big Data też zaprojektujemy wspólnie!
UPDATE! 20.07.2022 – premiera ebooka. Dołącz do newslettera, aby otrzymać go za darmo.
Włącz się w tworzenie!
No właśnie – otwarty na sugestie. Twoje. Mam przynajmniej taką nadzieję. Ebook będzie znacznie bardziej wartościowy jeśli dowiem się od Was co was nurtuje, czego nie rozumiecie. A może co było trudne na początkowym etapie rozwoju? Każda uwaga jest cenna.
Jest jednak mały “haczyk”. Chcę, żebyśmy tworzyli jedno naprawdę spójne środowisko. Najlepiej bez pośredników w postaci mediów społecznościowych (w końcu pracuję w Big Data! Wiem jak to działa;-)). W związku z tym cały proces twórczy będzie opierał się o newsletter.
W ramach newslettera będę komunikował znacznie, znacznie więcej niż dotychczas.
Przez newsletter dostaniesz każdy kolejny kawałek skończonego ebooka.
Będziesz mógł odpowiedzieć na konkretny email i zasugerować zmiany. Jestem otwarty na rozmowę, a nawet czekam na nią!
Ebook będzie później dostępny dla każdego newsletterowicza. Pomagając więc tworzyć książkę, w sposób najpełniejszy wspierasz społeczność. Razem możemy zbudować coś, od czego wyjdzie każdy nowy Inżynier Big Data i menedżer BigDato-świadomy (:D).
Aby tak się stało, zapisz się na newsletter już teraz:
Podsumowanie – jak włączyć się w proces twórczy?
No więc, podsumowując: zaczynam (już zacząłem;-)) tworzenie ebooka o Big Data. Pierwszy taki na polskim rynku. Będzie w całości za darmo dla newsletterowiczów RDF. Co więcej – jeśli jesteś (lub zostaniesz) subskrybentem, możesz włączyć się w proces twórczy:
Każdorazowo gdy skończę jakiś większy fragment, wyślę Ci go do sprawdzenia.
Ponadto możesz odpowiadać na emaile i podpowiadać jakie poprawki chcesz wprowadzić. Zarówno te drobne (jeszcze jedna technologia?) jak i te fundamentalne (nowy dział?).
Jestem głęboko przekonany, że razem zbudujemy coś wyjątkowego! Dołącz także do naszego LinkedIn i podaj artykuł znajomym, którzy mogą być zainteresowani;-).
Dokonując transformacji w Sparku, bardzo często korzystamy z gotowych, wbudowanych rozwiązań. Łączenie tabel, explodowanie tablic na osobne wiersze czy wstawianie stałej wartości – te i wiele innych operacji zawarte są jako domyślne funkcje. Może się jednak okazać, że to nie wystarczy. Wtedy z pomocą w Sparku przychodzi mechanizm UDF (User Defined Function).
Dzisiaj o tym jak krok po kroku stworzyć UDFa, który może być wyorzystany w wygodny sposób wszędzie w projekcie. Do dzieła! Całą serię “zrozumieć sparka” poznasz tutaj.
Co to jest UDF w Sparku?
Wczuj się w sytuację. Tworzysz joba sparkowego, który obsługuje dane firmowe dotyczące pracowników. Chcesz przyznawać premie tym najlepszym, najwierniejszym i najbardziej pracowitym i zyskownym. Po zebraniu potrzebnych informacji w jednym DataFrame, będziemy chcieli utworzyć kolumnę “bonus” która zawiera prostą informację: kwotę premii na koniec roku.
Aby to wyliczyć, został utworzony wcześniej wzór. Wykorzystując informacje dotyczące stanowiska, zyskowności projektu, oceny współpracowników, przepracowanych godzin i kilku innych rzeczy. Oczywiście nie ma możliwości, żeby wyliczyć to przy pomocy zwykłych funkcji. Z drugiej jednak strony, jeśli mielibyśmy jednostkowo wszystkie potrzebne dane – nie ma problemu, aby taki wzór zakodować.
Temu właśnie służą sparkowe UDFs, czyli User Defined Functions. To funkcje, których działanie sami możemy napisać i które pozwolą nam na modyfikację Datasetów w sposób znacznie bardziej customowy. Można je utworzyć na kilka różnych sposobów, ale ja dzisiaj chciałbym przedstawić Ci swój ulubiony.
A ulubiony dlatego, ponieważ:
Jest elegancko zorganizowany
Daje możliwość wielokrotnego wykorzystywania UDFa w całym projekcie, przy jednokrotnej inicjalizacji go.
Jak zbudować UDF w Apache Spark? Instrukcja krok po kroku.
Instrukcja tworzenia UDFa jest dość prosta i można ją streścić do 3 kroków:
Stwórz klasę UDFa (rozszerzającą UDFX – np. UDF1, jeśli mamy do podania jedną kolumnę).
ZarejestrujUDFa.
Wywołaj UDFa podczas dodawania kolumny.
Scenariusz
Zobrazujmy to pewnym przykładem. Mamy do dyspozycji dataframe z danymi o ludziach. Chcemy sprawdzić zagrożenie chorobami na podstawie informacji o nich. Dla zobrazowania – poniżej wygenerowany przeze mnie Dataframe. Taki sobie prosty zestaw:-).
Efekt który chcemy osiągnąć? te same dane, ale z kolumną oznaczającą zagrożenie: 1- niskie, 2-wysokie, 3-bardzo wysokie. Oczywiście bardzo tu banalizujemy, w rzeczywistości to nie będzie takie proste!
Załóżmy jednak, że mamy zakodować następujący mechanizm: zbieramy punkty zagrożenia.
Bycie palaczem daje +20 do zagrożenia,
Wiek ma przedziały: do 30 lat (+0); do 60 lat (+10); do 80 lat (+20); powyżej (+40)
Aktywności fizyczne: jeśli są, to każda z nich daje -10 (czyli zabiera 10 pkt).
Tak, wiem – to nawet nie banalne, a prostackie. Rozumiem, zebrałem już baty od siebie samego na etapie wymyślania tego wiekopomnego dzieła. Idźmy więc dalej! Grunt, żeby był tutaj jakiś dość skomplikowany mechanizm (w każdym razie bardziej skomplikowany od takiego który łatwo możemy “ograć” funkcjami sparkowymi).
Krok 1 – Stwórz klasę UDFa
Disclaimer: zakładam, że piszemy w Scali (w Javie robi się to bardzo podobnie).
Oczywiście można też zrobić samą metodę. Ba! Można to “opękać” lambdą. Jednak, jak już napisałem, ten sposób rodzi największy porządek i jest moim ulubionym;-). Utwórz najpierw pakiet który nazwiesz “transformations”, “udfs” czy jakkolwiek będzie dla Ciebie wygodnie. Grunt żeby trzymać wszystkie te klasy w jednym miejscu;-).
Wewnątrz pakietu utwórz klasę (scalową) o nazwie HealtFhormulaUDF. Ponieważ będziemy przyjmowali 3 wartości wejściowe (będące wartościami kolumn smoker, age i activities), rozszerzymy interfejs UDF3<T1, T2, T3, R>. Oznacza to, że musimy podczas definicji klasy podać 3 typy wartości wejściowych oraz jeden typ tego co będzie zwracane.
Następnie tworzymy metodę call(T1 t1, T2 t2, T3 t3), która będzie wykonywać realną robotę. To w niej zaimplementujemy nasz mechanizm. Musi ona zwracać ten sam typ, który podaliśmy na końcu deklaracji klasy oraz przyjmować argumenty, które odpowiadają typami temu, co podaliśmy na początku deklaracji. Gdy już to mamy, wewnątrz należy zaimplementować mechanizm, który na podstawie wartości wejściowych wyliczy nam nasze ryzyko zachorowania. Wiem, brzmi to wszystko odrobinę skomplikowanie, ale już pokazuję o co chodzi. Spójrz na skończony przykład poniżej.
package udfs
import org.apache.spark.sql.api.java.UDF3
class HealthFormulaUDF extends UDF3[String, Int, String, Int]{
override def call(smoker: String, age: Int, activities: String): Int = {
val activitiesInArray: Array[String] = activities.split(",")
val agePoints: Int = ageCalculator(age)
val smokePoints: Int = if(smoker.toLowerCase.equals("t")) 20 else 0
val activitiesPoints = activitiesInArray.size * 10
agePoints + smokePoints - activitiesPoints
}
def ageCalculator(age: Int): Int ={
age match {
case x if(x < 30) => 0
case x if(x >= 30 && x < 60) => 10
case x if(x >= 60 && x < 80) => 20
case _ => 40
}
}
}
Dodałem sobie jeszcze pomocniczą funkcję “ageCalculator()”, żeby nie upychać wszystkiego w metodzie call().
Zarejestruj UDF
Drugi krok to rejestracja UDF. Robimy to, aby potem w każdym miejscu projektu móc wykorzystać utworzony przez nas mechanizm. Właśnie z tego powodu polecam dokonać rejestracji zaraz za inicjalizacją Spark Session, a nie gdzieś w środku programu. Pozwoli to nabrać pewności, że ktokolwiek nie będzie w przyszłości wykorzystywał tego konkretnego UDFa, zrobi to po rejestracji, a nie przed. Poza tym utrzymamy porządek – będzie jedno miejsce na rejestrowanie UDFów, nie zaś przypadkowo tam gdzie komuś akurat się zachciało.
Aby zarejestrować musimy najpierw zainicjalizować obiekt UDFa. Robimy to w najprostszy możliwy sposób. Następnie dokonujemy rejestracji poprzez funkcję sparkSession.udf.register(). Musimy tam przekazać 3 argumenty:
Nazwę UDFa, do której będziemy się odnosić potem, przy wywoływaniu
Obiekt UDFa
Typ danych, jaki zwraca konkretny UDF (w naszym przypadku Integer). UWAGA! Typy te nie są prostymi typami Scalowymi. To typy sparkowe, które pochodzą z klasy DataTypes.
Poniżej zamieszczam całość, razem z inicjalizacją sparkSession aby było wiadomo w którym momencie t uczynić;-).
val sparkSession = SparkSession.builder()
.appName("spark3-test")
.master("local")
.getOrCreate()
val healthFormulaUDF: HealthFormulaUDF = new HealthFormulaUDF()
sparkSession.udf.register("healthFormulaUDF", healthFormulaUDF, DataTypes.IntegerType)
W tym momencie UDF jest już zarejestrowany i można go wywoływać gdziekolwiek w całym projekcie.
Wywołaj UDF
Ostatni krok to wywołanie UDFa. To będzie bardzo proste, ale musimy zaimportować callUDF z pakietu org.apache.spark.sql.functions (można też zaimportować wszystkie funkcje;-)).
Ponieważ chcemy utworzyć nową kolumnę z liczbą punktów, skorzystamy z funkcji withColumn(). Całość poniżej.
val peopleWithDiseasePoints: Dataset[Row] = peopleDF.withColumn("diseasePoints",
callUDF("healthFormulaUDF", col("smoker"), col("age"), col("activities")))
Efekt jest jak poniżej. Im mniej punktów w “diseasePoints” tym lepiej. Cóż, chyba nie mam się czym przejmować, mam -20 pkt!
Podsumowanie
W tym artykule dowiedzieliśmy się czym w Apache Spark jest UDF. Zasadniczo całość można sprowadzić do 3 prostych kroków:
Stwórz klasę UDFa (rozszerzającą UDFX – np. UDF1, jeśli mamy do podania jedną kolumnę).
ZarejestrujUDFa.
Wywołaj UDFa podczas dodawania kolumny.
To był materiał z serii “Zrozumieć Sparka”. Nie pierwszy i definitywnie nie ostatni! Jeśli jesteś wyjątkowo głodny/a Sparka – daj znać szefowi. Przekonaj go, żeby zapisał Ciebie i Twoich kolegów/koleżanki na szkolenie ze Sparka. Omawiamy całą budowę od podstaw, pracujemy dużo i intensywnie na ciekawych danych, a wszystko robimy w miłej, sympatycznej atmosferze;-) – Zajrzyj tutaj!
A jeśli chcesz pozostać z nami w kontakcie – zapisz się na newsletter lub obserwuj RDF na LinkedIn. Koniecznie, zrób to i razem twórzmy polską społeczność Big Data!
Za mną już znacznie ponad 20 mięsistych, wyczerpujących wpisów. Wciąż jednak brakuje fundamentalnego “Co to jest Big Data?”. Na to pytanie można odpowiadać godzinami. Dziś chciałbym jednak spojrzeć z biznesowej perspektywy. Nie będzie zbyt wielu technikaliów. Nie będziemy rozważać ile executorów powinno się ustawiać w spark-submit, ani czym różni się HBase od Accumulo. Ten artykuł przeznaczony jest dla osób zarządzających. Dla tych, którzy chcą pchnąć firmę na wyższy poziom i zastanawiają się, co to jest ta Big Data. Kubek z kawą na biurko… i ruszamy!
Jak to się zaczęło?
Zanim przejdziemy do samego sedna, bardzo istotna jest jedna rzecz: Big Data to naprawdę duża, złożona działka. Ciężko opisać ją w kilku punktach. Żeby ją zrozumieć, trzeba podejść z w kilku różnych kontekstach. Zacznijmy od krótkiej historii początków. Dzięki temu prawdopodobnie nie tylko zrozumiemy kontekst, ale i kilka cech charakterystycznych tej branży – co przyda się w podejmowanych decyzjach biznesowych.
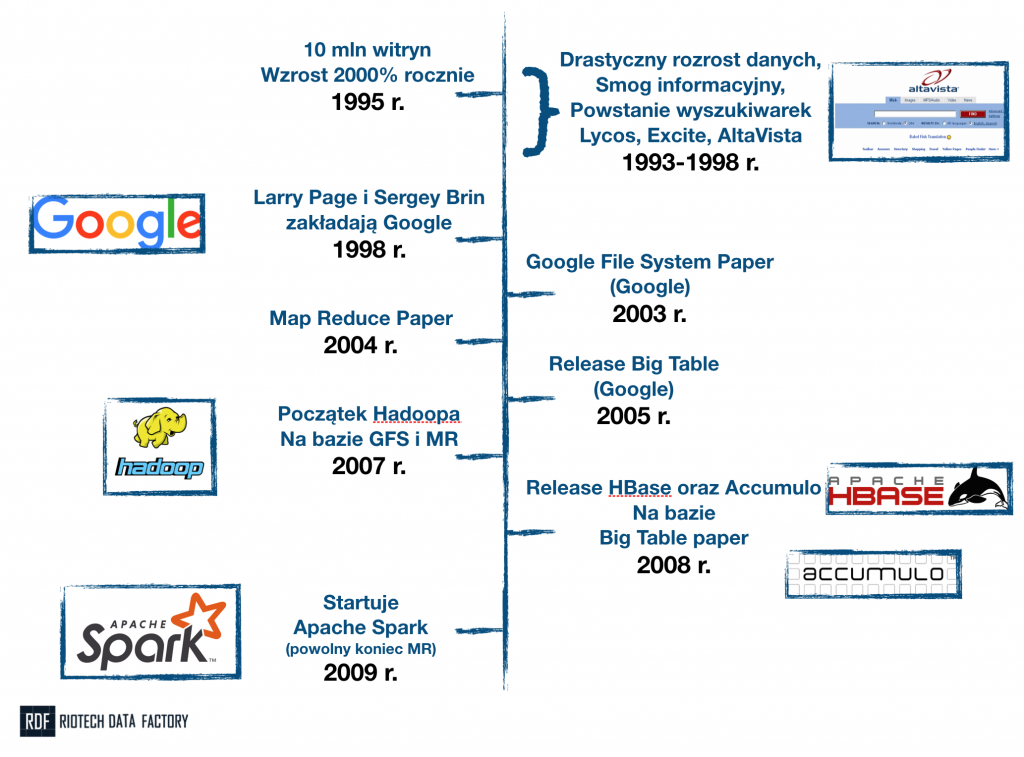
Jak to często bywa z historią, początki są niejasne i każdy może mieć troszkę swoją własną teorię. Moim zdaniem jednak, definitywny początek Big Data ma… w Google. Tak – znana nam wszystkim korporacja (i wyszukiwarka) jest absolutnie najbardziej zasłużoną organizacją dla tej branży. Niezależnie od rozmaitych swoich grzeszków;-). Ale spójrzmy jeszcze wcześniej – do roku 1995. To wtedy Internet przybiera na sile. Jego rozmiary są nie do końca znana, natomiast sięga już przynajmniej 10 mln witryn. Co “gorsza”… rozwija się w tempie 2000% rocznie.
AltaVista była pierwszą, przełomową wyszukiwarką
Chaos Internetowy lat 90′
Kluczową dla funkcjonowania Internetu rzeczą, są wyszukiwarki. Dziś to dla nas rzecz oczywista, ale w 95′ wcale tak nie było. Jeśli jednak nie będzie wyszukiwarek, nie znajdziemy znakomitej większości rzeczy, których potrzebujemy. Problem polega na tym, że wyszukiwarki nie przeszukują całego internetu za każdym razem. One zapisują strony (w odpowiedniej strukturze, niekoniecznie całe strony) w swoich bazach danych. Następnie przeszukują te bazy, kiedy użytkownik przekaże zapytanie.
Wniosek jest oczywisty: wyszukiwarki to nie nudne “lupki”, a bardzo zaawansowana technologicznie maszyneria. Maszyneria, która potrzebuje dożo miejsca na dysku, dużo pamięci podręcznej oraz mocy obliczeniowej. Jak bardzo, przekonali się o tym Larry Page i Sergey Brin, którzy w 1998 roku zakładają Google. Z czasem bardzo szybko orientują się, że przyrost danych jest zbyt ogromny na jakikolwiek komputer.
I tutaj pojawia nam się pierwsza, najważniejsza (moim zdaniem) zasada, charakterystyka Big Data. Inżynierowie sporej już wtedy firmy, rozpoczęli prace nad technologią, która pozwoli przechowywać oraz przetwarzać bardzo duże dane (których jest więcej i więcej i więcej…). Ci jednak, zamiast skonstruować olbrzymi super-komputer, którym zaimponują światu, poszli w zupełnie inną stronę. Uznali, że i tak prędzej czy później (a raczej prędzej) skończy im się miejsce i moc obliczeniowa. Co wtedy, nowy super-komputer? No właśnie nie.
Podejście rozproszone (distributed)
Znacznie lepszym pomysłem będzie zbudowanie takiego oprogramowania, które pozwoli połączyć bardzo wiele komputerów. I korzystać z nich tak, jakbyśmy mieli jeden wielki komputer. Co kiedy skończą się możliwości? Cóż – po prostu dorzucimy kolejne mniejsze komputery do naszego ekosystemu. Takie podejście nazywa się podejściem “rozproszonym” (ang. distributed). Tak właśnie powstaje Google File System (GFS) oraz opublikowany zostaje Google File System Paper, na którym opisana jest architektura wynalazku. Rok i dwa lata później publikowane są kolejne przełomowe dokumenty: Map Reduce (MR) Paper (który opisuje technologię do przetwarzania danych) i Big Table Paper.
Czemu Google to fundament Big Data? Bo na wyżej wymienionych dokumentach powstają najbardziej fundamentalne technologie open-source. Fundacja Apache ogłasa w 2007 roku, że na bazie GFS oraz MR powstaje Hadoop – prawdopodobnie najbardziej znana technologia Big Data. Rok później, znów na bazie dokumentu Google (Big Table Paper) powstają dwie bazy danych: HBase oraz Accumulo.
Historia Big Data. Od chaosu w Internecie na początku lat 90′ do zaawansowanych technologii Big Data XXI wieku.
Co to jest Big Data? Zasada 3V
Skoro wiemy już jak to się wszystko zaczęło, przejdźmy do podstawowego pytania: Co to tak naprawdę jest Big Data? Skonkretyzujmy to sobie nieco. Jesteśmy w IT, więc postarajmy się zdefiniować tą materię. Dawno temu wyznaczona została zasada, która określa czym jest Big Data. Zasada ta była później rozwijana, natomiast my przyjrzymy się pierwotnej wersji. Dodajmy – wersji, która moim zdaniem jest najlepsza, każda kolejna to już troszeczkę budowa sztuki dla sztuki;-).
Chodzi mianowicie o wytłuszczoną w nagłówku zasadę 3V. Określa ona cechy danych, które najmocniej charakteryzują Big Data.
Volume (objętość) – najbardziej intuicyjna cecha. Wszyscy dobrze rozumiemy, że jak data mają być big, to muszą mieć “dużą masę”. Ile dokładnie, ciężko stwierdzić. Niektórzy mówią o dziesiątkach GB, inni dopiero o terabajtach danych.
Velocity (prędkość) – to już nieco mniej oczywista rzecz. Moim zdaniem jednak bardzo istotna dla zrozumienia naszej materii. Wyobraź sobie, że śledzisz wypowiedzi potencjalnych klientów w mediach społecznościowych. W tym celu analizujesz wszystkie posty z określonymi tagami. Można się domyślić jak szybko przybywa tych danych (i jak bardzo często są one nie do użycia, ale to już inna sprawa). Tutaj właśnie objawia się drugie “V”. Wielokrotnie mamy do czynienia nie tylko z dużymi danymi, ale także z danymi które napływają lub zmieniają się niezwykle szybko. To ogromne wyzwanie. Znacząco różni się od stanu, w którym po prostu musimy przetworzyć paczkę statycznych, zawsze takich samych danych.
Variety (różnorodność) – I ta cecha prawdopodobnie jest już zupełnie nieintuicyjna (w pierwszym odruchu). Dane które dostajemy bardzo często nie są pięknie ustrukturyzowane, ułożone, wraz z dostarczonymi schematami. Wręcz przeciwnie! To dane, które często są nieustrukturyzowane, w których panuje chaos. Dane, które nawet w ramach jednego zbioru są różne (np. wiadomości email). Są to wyzwania z którymi trzeba się mierzyć i do których zostały powołane odpowiednie technologie – technologie Big Data.
Big Data w biznesie – kiedy zdecydować się na budowanie kompetencji zespołu?
Skoro już wiemy jak to się zaczęło i czym to “dokładnie” jest, czas postawić to kluczowe pytanie. Przynajmniej kluczowe z Twojej perspektywy;-). Kiedy warto zdecydować się na budowanie kompetencji Big Data w zespole? Nie będę zgrywał jedynego słusznego mędrca. Ta branża jest skomplikowana niemal tak jak życie. Nie ma jednego zestawu wytycznych. Podzielę się jednak swoimi spostrzeżeniami.
Poniżej wymieniam 5 sytuacji, które mogą Ci się przydać. Bądźmy jednak szczerzy – to pewna generalizacja. Być może jednak całkiem przydatna;-).
Na horyzoncie pojawia się projekt, który nosi znamiona Big Data
Niezależnie od tego jaki jest charakter Twojej firmy, prace poukładane są w coś co nazwiemy “projektami”. Ten punkt sprawdzi się szczególnie wtedy, gdy outsourceujecie zasoby ludzkie lub robicie zlecaną przez innych robotę. W takiej sytuacji może na horyzoncie pojawić się projekt “legacy”, który ma kilka cech charakterystycznych:
Wykorzystywane są technologie Big Data. Dokładniej na temat tego jakie technologie za co odpowiadają, znajdziesz tutaj. Miej jednak radar nastawiony przynajmniej na kilka z nich:
Hadoop (w tym HDFS, Yarn, MapReduce (tych projektów nie bierz;-)).
Hive, Impala, Pig
Spark, Flink
HBase, MongoDB, Cassandra
Kafka,
“Przerzucane” są duże ilości danych (powyżej kilkudziesięciu gigabajtów)
Projekt bazuje na bardzo wielu różnych źródłach danych
Projekt pracuje na średnich ilościach danych (dziesiątki gb), ale pracuje bardzo niewydajnie, działa wolno i sprawia przez to problemy.
I inne;-). Jeśli widzisz projekt, który na odległość pachnie zapychającymi się systemami, technologiami Big Data i różnorodnością danych – wiedz, że czas najwyższy na budowę zespołu z odpowiednimi możliwościami.
Projekt nad którym pracujecie, przerósł wasze oczekiwania
Wielokrotnie bywa tak, że mechanizmy zbudowane w ramach jakiegoś projektu są dobre. Szczególnie na początkowym etapie, kiedy danych nie ma jeszcze zbyt wielu. Potem jednak danych przybywa, źródeł przybywa i… funkcjonalności przybywa. Tylko technologie i zasoby pozostają te same. W takim momencie proste przetwarzanie danych w celu uzyskania raportów dziennych trwa na przykład 6 godzin. I wiele wskazuje na to, że będzie coraz gorzej.
Ważne, żeby podkreślić, że nie musi to być wina projektantów systemu. Czasami jednak trzeba dokonać pivotu i przepisać całość (albo część!) na nowy sposób pracy. Nie jest to idealny moment na rozpoczęcie wyposażania zespołu w kompetencję Big Data. Może to być jednak konieczne.
Zapada decyzja o poszerzeniu portfolio usługowego
Tu sprawa jest oczywista. Świadczycie usługi IT. Robicie już znakomite aplikacje webowe, mobilne, pracujecie w Javie, Angularze i Androidzie. Podejmujecie decyzję żeby poszerzyć portfolio o usługi w ramach Big Data. To nie będzie łatwe! Należy zbudować całą strukturę, która pozwoli odpowiednio wyceniać projekty, przejmować dziedziczony (legacy) kod czy projektować systemy. Trzeba się do tego przygotować.
Czy trzeba budować cały nowy dział od 0? Absolutnie nie – można bazować na już istniejących pracownikach, choć z całą pewnością przydałby się senior oraz architekt. Warto jednak pamiętać, że cały proces powinien rozpocząć się na wiele miesięcy przed planowanym startem publicznego oferowania usług Big Data.
Organizacja znacząco się rozrasta wewnętrznie
Bardzo często myślimy o przetwarzaniu dużych danych na potrzeby konkretnych projektów, produktów itd. Jednym słowem, zastanawiamy się nad dość “zewnętrznym” efektem końcowym. Musimy jednak pamiętać, że równie cennymi (a czasami najcenniejszymi) danymi i procesami, są te wewnętrzne. Big Data nie musi jedynie pomagać nam w wytworzeniu wartości końcowej. Równie dobrze możemy dzięki obsłudze dużych danych… zmniejszyć chaos w firmie. Nie trzeba chyba nikomu tłumaczyć jak zabójczy potrafi być chaos w organizacji. I jak łatwo powstaje.
Do danych wewnętrznych zaliczymy wszystko co jest “produktem ubocznym” funkcjonowania firmy. Na przykład dane dotyczące pracowników, projektów, ewaluacji itd. Także klientów, zamówień, stanów magazynowych. Jeśli uda nam się na to wszystko nałożyć dane geolokalizacyjne i garść informacji ze źródeł ogólnodostępnych, możemy zacząć budować sobie całkiem konkretne raporty dotyczące profili klientów. Gdy pozyskamy kilka wiader bajtów z serwisów promocyjnych i inteligentnie połączyć z resztą – możemy dowiedzieć się o racy firmy, klientach oraz nadchodzących okazjach znacznie więcej, niż wcześniej. I więcej, niż konkurencja;-).
Chmura czy własna infrastruktura? (Cloud vs On-Premise)
Gdy jesteśmy już świadomi branży Big Data oraz okoliczności, w jakich warto w nią wejść – zastanówmy się nad najbardziej fundamentalną rzeczą. Mowa o infrastrukturze komputerowej, którą będziemy wykorzystywać. Mówiąc bardzo prosto: nasze technologie muszą być gdzieś zainstalowane, a dane gdzieś przechowywane. Pytanie zwykle dotyczy wyboru między dwoma ścieżkami: albo będziemy mieli swoją własną infrastrukturę, albo wykorzystamy gotowych dostawców chmurowych.
Które podejście jest lepsze? Odpowiedź jest oczywista: to zależy. Nie ma jednego najlepszego podejścia. To przed czym chcę Cię w tym miejscu przestrzec, to przed owczym pędem w kierunku chmur. Zwykło się myśleć, że aplikacja działająca w chmurze, to aplikacja innowacyjna, nowoczesna, lepsza. To oczywiście nie jest prawda.
Czym jest Cloud a czym On-premise
Żeby w ogóle wiedzieć o czym mówimy, zacznijmy od uproszczonego wyjaśnienia, które jakoś nas ukierunkuje.
Własna infrastruktura (On-Premise, często skrótowo po prostu „on-prem”) – komputery, które fizycznie do nas należą, są przechowywane gdzieś „na naszym terytorium”. Samodzielnie łączymy je siecią, instalujemy tam odpowiednie oprogramowanie, synchronizujemy itd. Specjalnie do tego typu infrastruktury stworzona została m.in. popularna platforma Big Data Apache Hadoop. Stawiając on-premise musimy zadbać o samodzielną obsługę całości, natomiast koszt związany z zasobami jest „jednorazowy” w momencie zakupu sprzętu (potem oczywiście jeśli chcemy ją rozbudować).
Chmura (Cloud) – czyli instalacja odpowiedniego oprogramowania na komputerach (serwerach) udostępnionych przez zewnętrzną firmę. Taka firma (np. Microsoft ze swoją chmurą Azure) ma centra danych (data center) w różnych miejscach na świecie. Komputery te są ze sobą powiązane odpowiednimi sieciami i zabezpieczeniami. Szczegóły technologiczne na ten moment sobie darujmy (prawda jest taka, że to na tyle złożone tematy, że… z poszczególnych chmur (np. Azure czy AWS) robi się powszechnie uznawane certyfikaty – sam zresztą nawet jednym dysponuję;-)). Za chwilę odrobinę dokładniej opowiemy sobie jakie mamy dostępne możliwości wykorzystując chmurę. Teraz jednak to co trzeba zrozumieć, to że rezygnujemy z ręcznej obsługi zasobów. Oddajemy całość administracyjną fachowcom z konkretnej firmy. Gdy korzystamy z takich usług, nie wiemy na jakim dokładnie komputerze (komputerach, bardzo wielu) lądują nasze dane. Tak więc sporo „zabawy” nam odchodzi. Oczywiście coś za coś, natomiast o plusach i minusach porozmawiamy za chwilę.
Teraz wypadałoby podpowiedzieć jakie dokładnie są różnice. A jest ich dużo. Od przewidywalności, przez koszty (kilka ich rodzajów), kwestie prywatności danych, łatwość skalowalności aż po terytorialność danych. W tym miejscu chciałbym odnieść do moich dwóch artykułów:
W tym artykule daję takie proste zestawienie różnych aspektów. Zajmie Ci to chwilkę, a będzie bardzo dobrym punktem startowym.
Drugi artykuł jest dla ambitnych. Poruszam tam kwestie, które zazwyczaj nie są poruszane. Jest to pogłębiona analiza zagadnienia “Cloud vs On-prem”.
Jak zacząć budowę zespołu z kompetencjami Big Data?
Oto najważniejsze być może pytanie. Napiszę na ten temat osobny artykuł. Tutaj zerknijmy jednak skrótowo na temat, który jest niezwykle istotny, a wręcz powiedzmy sobie – kluczowy. Moment zainwestowania w kompetencje może być wybrany lepiej lub gorzej, ale źle zbudowany zespół będzie się mścić przez lata. Oznacza źle zaprojektowane systemy, źle napisany kod, a to – w efekcie – projekty, które po latach trzeba będzie wyrzucić do śmieci lub napisać od początku. A można uniknąć tego wszystkiego robiąc cały proces tak, aby miał ręce i nogi;-).
Znów – nie chcę rościć sobie praw do wyznaczania jedynie słusznej ścieżki rozwoju. Zaproponuję jednak kilka punktów, które mogą nakierować myślenie na metodyczne podejście, które w perspektywie się opłaci.
Po pierwsze – przygotujmy się
Nie róbmy wszystkiego na łapu capu. Trzeba mieś pewną wiedzę, która zaczyna się w kadrze menedżerskiej. Bez tego będziemy przepalać pieniądze. Niech menedżerowie nie oddzielają się grubym murem od technicznych. Zdobycie podstawowych informacji nie będzie techniką rakietową, a pozwoli podejmować lepsze decyzje.
W jaką wiedzę się uzbroić? (przykład)
Zbudowanie zespołu kosztuje. To podstawa, z którą warto się oswoić. Inżynierowie Big Data są drogimi specjalistami, szkolenie i doradztwo jest drogie. Prawdopodobnie cały proces nie zamknie się w kilkudziesięciu tysiącach złotych, choć kosztorys to zawsze bardzo indywidualna sprawa.
Jakie są dokładnie powody budowy zespołu z kompetencjami Big Data? To bardzo istotne, bo będzie wymuszało różny start, datę, technologie itd. Omawialiśmy to trochę wyżej.
Kiedy Chcemy wystartować?
Na jakim zespole bazujemy? Czy na jakimkolwiek?
Jakie są generalne technologie Big Data? Nie chodzi o szczegóły, ale o ogólne rozeznanie się w tym co istnieje na rynku.
Jaki jest nasz dokładny plan działania? Taka road-mapa powinna być przedyskutowana z początkowym zespołem, aby ludzie Ci mieli świadomość w którym kierunku idą.
Czy potrzebujemy infrastruktury? Być może nie, ale prawdopodobnie jednak na czymś trzeba będzie bazować.
Po drugie – wyznaczmy zespół
Zespół może być tworzony od zera, może być zrekrutowany. Bardzo prawdopodobne, że uda się zrobić opcję hybrydową, czyli wyszkolić kilku specjalistów do początkowego etapu, a zrekrutować seniora, który tym pokieruje.
Jeśli bazujemy na ludziach którzy już pracują w firmie, warto patrzeć na ludzi z doświadczeniem w Javie oraz bazach danych. Oczywiście podstawą jest doświadczenie z systemami Linuxowymi, oraza z gitem.
Po trzecie – przeszkólmy zespół
Jeśli mamy już zespół, warto go przeszkolić. Szczególnie tą część, która jest “świeża”. Należy dokładnie zastanowić się nad technologiami z jakimi chcemy ruszyć, jakie bedą potrzebne na początku. W ustaleniu dokładnego planu działania pomoże specjalna firma – tu polecam nas, RDF;-). Zapraszam pod ten link, gdzie można zapoznać się z ofertą szkoleń.
W tym miejscu dodam jeszcze jedno. Szkolenia można przeprowadzać doraźne i intensywne. Na przykład kilka dni bardzo mocnego treningu z Apache Spark. Jest jednak dostępna także inna możliwość, która tutaj sprawdzi się znacznie bardziej. To bardzo obszerne, długie szkolenia, które wyposażają kursantów w umiejętności z podstaw Big Data. Takie szkolenie może trwać nawet 2, 3 miesiące. Warto rozważyć;-).
Po czwarte – niech zespół zdobędzie pierwsze rany w walce
Kiedy mamy już cały zespół, warto zrobić pierwszy projekt. Jeszcze nie dla klienta. Najlepiej, żeby projekt ten miał swój konkretny cel, który przysłuży się firmie, będzie projektem Open Source lub choćby “wizytówką”. Niestety, nie wszystko wyjdzie w czasie szkoleń – nawet naszych;-) (mimo, że w ramach tego długiego szkolenia sporo czasu zajmuje mini-projekt właśnie). Wiele rzeczy musi zostać wypalonych w projektowym ogniu. Od stricte technicznych, przez organizacyjne, po kontakcie wewnątrz zespołu.
Po takim projekcie… cóż, sami najlepiej będziecie wiedzieć, czy zespół jest gotowy do działania. Być może potrzebne będą kolejne kroki, a być może wstępne doświadczenie będzie już wystarczająco solidne:-)
Podsumowanie
Uff, to był naprawdę długi artykuł. Cieszę się, że docieramy do końca razem! Jestem przekonany, że masz teraz już podstawową wiedzę na temat Big Data, w kontekście biznesowym. Oczywiście tak naprawdę zaledwie musnęliśmy temat. Jest to jednak już dobry start do dalszej pracy.
Jeśli potrzebujesz naszych usług, polecam z czystym sumieniem. Nasze szkolenia są tworzone z myślą, że mają być możliwie podobne do prawdziwego życia. My sami jesteśmy żywymi pasjonatami naszej branży. Bardzo chętnie Ci pomożemy – czy to w temacie nauki czy konsultacji. Nie bój się napisać!
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Będzie nam bardzo miło Cię gościć;-).
WAŻNA INFORMACJA! Jestem w trakcie pisania ebooka. Będzie w tematyce takiej jak ten artykuł, jednak bardziej “na spokojnie” oraz dogłębniej. Co więcej – będzie za darmo dostępeny! Dla każdego? NIE. Jedynie dla zapisanych na newsletter. Zapisz się już dzisiaj i zyskaj wpływ na proces twórczy;-)
Właśnie skończyłem kolejne szkolenie (nie byle jakie, bo to było 2-miesięczne, kompleksowe – serio, hardcore). Uświadomiło mi ono jedną bardzo konkretną rzecz w kontekście naszego zrozumienia systemów Big Data. Chciałem się nią podzielić. Artykuł przede wszystkim do technicznych, ale… nie tylko. Zdecydowanie nie tylko.
Złożoność – nasz główny wróg
Podchodząc do systemu przetwarzania bardzo dużych ilości danych, mamy jednego podstawowego wroga. Staje przed nami niczym behemot już na poziomie koncepcji. Jest to… stopień złożoności problemu. Przyznajmy szczerze – nie lubimy złożonych problemów. Ani w życiu prywatnym, ani zawodowym. Aby rozwiązać taki problem, należy wytężyć mózgownicę do takich granic, które u niektórych powodują niemały ból.
Szczególnie daje się to we znaki, gdy ktoś przeszedł do Big Data z “tradycyjnej IT”. Jeśli robiłeś wcześniej aplikacje webowe, możesz doznać szoku. I nie mówię nawet o tym, że dotychczas wszystkie Twoje problemy zawarte były w jednym pliku z logami, podczas gdy tutaj nawet pojedyncza technologia ma kilka serwisów, a każdy z nich swoje własne logi.
Po prostu złożoność jest inna. Robiąc aplikację webową (zostańmy przy tym), mam jasne wytyczne, standardy i zwykle prostą ścieżkę, którą uruchamia (najczęściej) użytkownik. Wejdziemy pod odpowiedni adres? W takim razie musimy wysłać zapytanie do bazy danych, dokonać kilku obliczeń i wyrenderować stronę końcową.
Gorzej, jeśli trzeba zbudować cały skomplikowany system, a wejście (rozumiane jako input)… cóż, wejścia czasami nie ma. Albo jest ich bardzo, bardzo wiele. Albo – co gorsza – jest wejście, wyglądające bardzo “tradycyjnie”(np. request użytkownika).
Jak zaprojektować system – problem złudnego “wejścia” (inputu)
Przypuśćmy taką prostą sytuację. Robimy aplikację-wyszukiwarkę filmów związanych z danymi miastami. W efekcie wpiszemy nazwę miasta, a otrzymujemy listę miast, które w ten czy inny sposób dotyczą go (czy to w kontekście tematyki czy lokalizacji).
Bardzo łatwo w takiej sytuacji zacząć całe projektowanie wychodząc od użytkownika i mając przeświadczenie, że to on musi uruchamiać całą machinę. No świetnie, zatem wcielmy się w taką rolę. Użytkownik wpisuje nazwę miasta i… i co? Czy mam teraz starać się wyszukiwać po internecie wszystkich możliwych informacji? Byłoby to całkiem, całkiem długotrwałym procesem.
No dobrze, więc może zacząć zbierać oraz przetwarzać dane, osobno? Pomysł dobry. Jednak i tutaj można łatwo wpaść w pułapkę wąskiego myślenia. Ciągle mamy z tyłu głowy użytkownika, więc zaczynają powstawać dziwne pomysły, na uruchamianie przetwarzania po wykonanym requeście, w trakcie itd. Ciągle mamy tą manierę, że staramy się wychodzić od jednego punktu i przejść przez wszystkie elementy systemu. To trochę tak, jakbyśmy starali się złapać bardzo dużo drewnianych klocków na raz. Nie ma szans – wypadnie. Kto próbował ekspresowo posprzątać po zabawach swoich dzieci u Dziadków, wie o co chodzi.
Słowo klucz: decentralizacja
Prowadząc szkolenie, gdzieś w połowie zorientowałem się, że coś jest nie tak. Zbadałem temat i zauważyłem, że kursanci bardzo dziwnie podeszli do budowy modułów. Chodziło konkretnie o te podstawowe rzeczy, jakimi jest wejście i wyjście aplikacji (input i output) oraz zarządzanie całością. Zasadniczo cały projekt opierał się oczywiście o bardzo wiele mniejszych modułów. Niektóre pobierały dane z internetu, inne te dane czyściły i przetwarzały. Jeszcze inny moduł – streamingowy – służył do kontaktu użytkownika z systemem.
W pewnym momencie, po raz kolejny dostałem pytanie, które brzmiało mniej więcej tak: “No, skoro mamy mnóstwo małych modułów, to chyba musimy też gdzieś zbudować skrypt, który to wszystko uruchamia prawda?“. Uznałem, że czas na radykalną zmianę myślenia, przerwanie “starego” paradygmatu i zrozumienia o co chodzi w systemach do przetwarzania i obsługi dużych danych.
Myśl po nowemu – czyli jak poprawnie patrzeć na systemy Big Data?
Oczywiście nie ma jednej złotej zasady, dzięki której zrozumiemy “filozofię Big Data”. Jest jednak coś, czego zrozumienie może być przełomem. Pozwoli wygrać ze złożonością, pozwoli zrozumieć duży, skomplikowany system. Pomoże – wreszcie – przestać siwieć (albo, jak w moim przypadku jest – łysieć) z frustracji.
Otóż, chodzi o magiczne słowo: decentralizacja. Nie, mowa nie o technologii blockchain;-). Chodzi o umiejętność spojrzenie na cały system metodą “od ogółu do szczegółu” i zrozumienie poszczególnych elementów (modułów lub powiązań między nimi). Spójrzmy na kilka kwestii, które to tłumaczą.
Każdy wielki system zbudowany jest z wielu mniejszych (co nie znaczy małych) modułów. Na etapie rozumienia całości, nie musimy wgłębiać się w technikalia czy implementację. Wystarczy nam ogólna wiedza o tym co dany moduł przyjmuje, a co zwraca (jakie jest jego zadanie). Dodatkowo jeśli wiemy z jakimi modułami łączy się (bezpośrednio, lub na poziomie logicznym) to już w ogóle bardzo dużo.
Każdy moduł ma swoje zadanie. Niekoniecznie musi być zależne od innych modułów! Przykładowo, jeśli potrzeba nam w systemie pogody, to potrzeba nam pogody. Nie musimy wiązać tego z modułem, który pobiera filmy, albo składuje requesty od użytkownika. W momencie rozumienia modułu od pogody, musimy zbudować mechanizmy pobierające pogodę. Jak to zrobimy? Z wykorzystanie pythona, javy? A może Nifi?
Każdy moduł może być uruchamiany niezależnie od użytkownika. I tutaj musimy znać miejsce takiego podsystemu w systemie.
Jeśli jest niezależny od czegokolwiek – wystarczy prosty skrypt oraz jakiś scheduler, typu Airflow czy Oozie. Pogodę możemy pobierać co godzinę niezależnie od wszystkiego.
Jeśli jest zależny, musimy wiedzieć w jaki sposób jest zależny. Znów najprawdopodobniej użyjemy schedulera, ale pewnie uzależnimy go od wyników innych modułów (jeśli dane nie zostały pobrane, nie ma sensu uruchamiać czyszczenia).
Może się okazać, że moduł naprawdę jest w ścisłym kontakcie z użytkownikiem. W takiej sytuacji, po prostu musimy to dobrze umieścić.
Gdy pracujemy z danym modułem, możemy się zagłębić w szczegóły, a jednocześnie “zapomnieć” o reszcie systemu. Gdy – znów – zaciągamy dane pogodowe, nie musimy myśleć o tym jak one potem zostaną wykorzystane. Dzięki temu usuwamy element, który nas przytłacza. Aby to zrobić – to istotne – powinniśmy wcześniej dobrze zaprojektować całość, łącznie z szczegółowo opisanym wyjściem (output’em). Jakie dokładnie dane pogodowe muszę zwrócić? Gdzie je zapisać? Do jakiej tabeli? Z jaką strukturą? To wszystko powinno być spisane na etapie projektowania, przed implementacją.
Podsumowanie
Tak więc, wracając do problemu ze szkolenia – nie, nie musimy mieć żadnego skryptu, który uruchamia moduły jeden po drugim. Wręcz byłoby to zabiciem idei. Moduły za to powinniśmy uruchamiać w którymś z wyspecjalizowanych schedulerów (polecam Airflow). Dzięki nim możemy przeznaczyć do regularnego startu konkretny moduł, albo połączyć go z innymi. Do tego możemy obsłużyć różne wyniki (np. wysłać email, jeśli coś pójdzie nie tak), przejrzeć logi itd.
Zdaję sobie sprawę, że to co przedstawiłem powyżej, dla wielu jest banałem. Jest jednak taki etap (na początku), gdy trzeba “przeskoczyć” na inne myślenie. I warto zacząć właśnie od kwestii decentralizacji.
Między innymi takich rzeczy, poza stricte technicznymi, uczę na naszych RDFowych szkoleniach. Przejrzyj te, które możemy dla Was zrobić, a potem przekonaj szefa, że solidnie wykwalifikowany zespół, to lepsze wyniki firmy;-).
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Razem możemy więcej!
O tym, że Apache Ozone jest mniej podobny do HDFSa niż można przypuszczać, pisałem w artykule o budowie. Ponieważ postanowiłem stworzyć system do gromadzenia i analizy danych giełdowych, musiałem też zbudować nowy eksperymentalny klaster (czy może lepiej: klasterek;-)). Uznałem, że to znakomita okazja, żeby przetestować dość nowy, dojrzewający niczym włoska szynka system do gromadzenia danych: Apache Ozone.
W tym artykule znajdziesz kilka moich obserwacji oraz – co ważniejsze – lekcji. Będą z pewnością przydatne, jeśli także chcesz spróbować swoich sił i zbadać ten teren. Będą przydatne, ponieważ dokumentacja jest wybrakowana i nie odpowiada na wiele pytań, a społeczność… cóż, jeszcze właściwie nie istnieje. Bierz kubek mocnej jak wiedźmiński eliksir kawy – i zanurzmy się w przygodę!
Apache Ozone: obserwacje i informacje
Zacznijmy od mniej istotnej części, czyli moich subiektywnych przemyśleń na temat Apache Ozone. Poniżej 3 najistotniejsze z nich.
Ozone to nie HDFS. To nawet nie system plików (FS). Opisywałem to już w artykule na temat tego jak Ozone jest zbudowany (o architekturze). Podchodząc do “kontynuacji HDFSa” oczekiwałem podobnego systemu plików, jednak zapewne z nieco inną architekturą. Przeliczyłem się mocno. Ozone bowiem to nie File System, a Object Store. Skutkuje to przede wszystkim bardzo płaską strukturą. Nie zrobimy więc rozbudowanych, hierarchicznych struktur, jak miało to miejsce w HDFSie.
Ozone ma bardzo, bardzo niewielką społeczność. Co rodzi mocne komplikacje. No właśnie. To jest naprawdę problematyczna część. Warto wziąć poprawkę na termin w jakim to piszę. Apache Ozone jest dostępny w repozytorium głównym Mavena od listopada ubiegłego roku. Wersja GA została (jeśli się nie mylę) udostępniona dopiero w zeszłym roku. To wszystko sprawia, że technologia jest jeszcze mało dojrzała – przynajmniej w obszarze społeczności. Jest to bardzo ciekawy moment dla osób z pionierskim zacięciem;-). Praktycznie żaden błąd na który się natknąłem, nie był nigdzie w Internecie opisany. Rzecz bardzo rzadko spotykana. Chociaż ciekawa!
Warto od samego początku poznać architekturę. Ja przyznam, że miałem dwa podejścia do Ozona. Za pierwszym razem poległem. Było to spowodowane moją gorącą krwią i chęcią jak najszybszego przetestowania w boju nowej technologii. To błąd! Naprawdę warto przeznaczyć trochę czasu, żeby wgryźć się najpierw w to jak zbudowany jest Apache Ozone. Jeśli tego nie zrobimy, bardzo ciężko będzie rozwiązywać problemy, których trochę po drodze na pewno będzie. Jak już napisałem punkt wyżej – Ozone nie ma właściwie społeczności, więc najpewniej większość opisanych błędów spotkasz… w tym artykule. Aby je rozwiązać po prostu warto wiedzieć jak to wszystko działa:-).
Apache Ozone: problemy, które rozwiązałem
Instalując Apache Ozone napotkałem kilka problemów, które rozwiązałem, a którymi chcę się podzielić. Liczę, że ustrzeże Cię to przed wyrywaniem sobie włosów z głowy z powodu frustracji.
Wszystkie serwisy działają, ale plik nie chce się przekopiować z lokalnego systemu plików na Ozone. Podczas kopiowania (polecenie “ozone sh key put /vol1/bucket1/ikeikze2.pdf ikeikze2.pdf”) pojawia się następujący błąd:
Co to oznacza? Nie wiadomo. Wiadomo jedynie, że – mówiąc z angielska – “something is no yes”. W tym celu udajemy się do logów. Tu nie chcę zgrywać ozonowego mędrca, więc powiem po prostu: popróbuj. Problem może być w paru logach, ale z całą pewnością ja bym zaczął od logów datanode. Logi znajdują się w folderze “logs”, w folderze z zainstalowanym Ozonem (tam gdzie jest też folder bin, etc i inne).
Zacznijmy od komunikatu błędu, który można dostać po przejrzeniu logów ze Storage Container Manager (SCM).
ERROR org.apache.hadoop.hdds.scm.SCMCommonPlacementPolicy: Unable to find enough nodes that meet the space requirement of 1073741824 bytes for metada
ta and 5368709120 bytes for data in healthy node set. Required 3. Found 1.
Rozwiązanie: Należy zmienić liczbę replik, ponieważ nie mamy wystarczająco dużo datanodów w klastrze, aby je przechowywać (nie mogą być trzymane na tej samej maszynie). Aby to zrobić należy wyłączyć wszystkie procesy Ozone, a następnie zmienić plik ozone-site.xml. Konkretnie zmieniamy liczbę replik. Poniżej rozwiązanie, które na pewno zadziała, ale niekoniecznie jest bezpieczne – zmieniamy liczbę replik na 1, w związku z czym nie wymaga on wielu nodów do przechowywania replik.
W tym miejscu pokazane jest jak należy stawiać Apache Ozone. Jak widać są dwie ścieżki i tylko jedna z nich nadaje się do czegokolwiek.
W pierwszej stawiamy każdy serwis osobno: Storage Container Manager, Ozone Manager oraz Datanody. Jest to chociazby o tyle problematyczne, że jeśli mamy tych datanodów dużo, to trzeba by wchodzić na każdy z nich osobno.
Na szczęście istnieje też opcja uruchamiania wszystkiego jednym skryptem. W tym celu należy uruchomić plik start-ozone.sh znajdujący się w folderze sbin.
Jednak aby to zrobić, należy najpierw uzupełnić konfigurację. Zmiany są dwie:
Należy dodać kilka zmiennych do pliku ozone-env.sh w folderze “[folder_domowy_ozone]/etc/hadoop“.
Nalezy utworzyć plik workers wewnątrz tego samego folderu co [1].
Zmienne: tu należy dodać kilka zmiennych wskazujących na użytkowników ozona. Sprawa jest niejasna, bo Ozone przeplata trochę nomenklaturę z HDFS. Ja dodałem obie opcje i jest ok.
Po tym wszystkim możemy uruchomić skrypt start-ozone.sh
OM wyłącza się po uruchomieniu klastra
Po uruchomieniu klastra (sbin/start-ozone.sh) Ozone Manager zwyczajnie pada. Kiedy zajrzymy w logi, znajdziemy taki oto zapis:
Ratis group Dir on disk 14dd99c6-de01-483f-ac90-873d71fb5a44 does not match with RaftGroupIDbf265839-605b-3f16-9796-c5ba1605619e generated from service id omServiceIdDefault. Looks like there is a change to ozone.om.service.ids value after the cluster is setup
Były także inne logi, natomiast wiele wskazywało na Ratisa oraz omServiceIdDefault a także ozone.om.service.ids. Jeśli mamy następujący problem, oznacza to, że nasz klaster próbuje automatycznie włączyć tryb HA na Ozon Manager. Ponieważ mi na takim trybie nie zależy (mój klaster jest naprawdę mały i nie miałoby to większego sensu), wprost wyłączyłem HA. Aby to zrobić, należy zmodyfikować ustawienia.
Plik ozone-site.xml (znajdujący się w [katalog ozona]/etc/hadoop/ozone-site.xml)
Oczywiście po zaktualizowaniu ozone-site.xml plik powinien być rozesłany na wszystkie nody, a następnie klaster powinien zostać uruchomiony ponownie. Jeśli chcesz skorzystać z trybu HA, wszystkie (chyba;-)) informacje znajdziesz tutaj.
Przy requestach zwykłego użytkownika (nie-roota) wyskakuje błąd o brak dostępów do logów
A więc wszystko już poszło do przodu, spróbowaliśmy z roota (lub innego użytkownika, którym instalowaliśmy Ozone na klastrze) i wszystko było ok. Przynajmniej do czasu, aż zechcemy spróbować podziałać na innym użytkowniku. Wtedy dostajemy taki oto błąd:
java.io.FileNotFoundException: /ozone/ozone-1.2.1/logs/ozone-shell.log (Permission denied)
at java.io.FileOutputStream.open0(Native Method)
at java.io.FileOutputStream.open(FileOutputStream.java:270)
at java.io.FileOutputStream.<init>(FileOutputStream.java:213)
at java.io.FileOutputStream.<init>(FileOutputStream.java:133)
at org.apache.log4j.FileAppender.setFile(FileAppender.java:294)
at org.apache.log4j.FileAppender.activateOptions(FileAppender.java:165)
at org.apache.log4j.DailyRollingFileAppender.activateOptions(DailyRollingFileAppender.java:223)
(...)
log4j:ERROR Either File or DatePattern options are not set for appender [FILE].
Pocieszające jest to, że błąd ten nie oznacza, że polecenie do Ozone nie zostało wykonane. Oznacza jedynie, że nie mamy uprawnień do pliku z logami Ozone Shell. Żeby powiedzieć dokładniej, nie mamy dostępu do zapisu na tym pliku.
Nie jest to więc błąd stricte “Ozonowy”. Jest za to stricte linuxowy – należy nadać użytkownikowi odpowiednie uprawnienia. Można to zrobić na kilka różnych sposobów. Jeśli Twój klaster, podobnie jak mój, jest jedynie klastrem eksperymentalnym, możesz śmiało nadać uprawnienia zapisu “innym użytkownikom” pliku. Wchodzimy do folderu z logami i wpisujemy następującą komendę:
chmod a+rw ozone-shell.log
Podsumowanie
Apache Ozone to naprawdę ciekawa i – mam nadzieję – przyszłościowa technologia. Musi jednak jeszcze trochę wody w Wiśle upłynąć, aby zyskała popularność oraz dojrzałość HDFSa. Zachęcam jednak do eksperymentowania i dzielenia się tutaj wrażeniami;-)
Zachęcam także do dołączenia do naszej rodzącej się polskiej społeczności Big Data! Obserwuj RDF na LinkedIn, subskrybuj newsletter i daj znać że żyjesz. Razem możemy więcej!
Apache Ozone to następca HDFS – przynajmniej w marketingowym przekazie. W rzeczywistości sprawa jest nieco bardziej złożona i proste analogie mogą być złudne. Jako, że jestem w trakcie budowy systemu do analizy spółek giełdowych, buduję także nowy, eksperymentalny klaster (czy może – klasterek;-)). Uznałem to za idealny moment, żeby przetestować, bądź co bądź nową technologię, jaką jest Apache Ozone. W kolejnym artykule podzielę się swoimi obserwacjami oraz problemami które rozwiązałem. Zacznijmy jednak najpierw od poznania podstaw, czyli architektury Apache Ozone. Zapraszam!
Czym (nie) jest Apache Ozone?
Jeśli Ozone to następca HDFSa, a HDFS to system plików, to Apache Ozone jest systemem plików prawda? Nie. I to jest pierwsza różnica, którą należy dostrzec. HDFS był bliźniaczo podobny (w interfejsie i ogólnej budowie użytkowej, nie architekturze) do standardowego systemu plików dostępnego na linuxie. Mieliśmy użytkowników, foldery, a w nich pliki, ewentualnie foldery, w których mogły być pliki. Albo foldery. I tak w kółko.
Apache Ozone to rozproszony, skalowalny object store (/storage). Na temat podejścia object storage można przeczytać tutaj. Podstawową jednak różnicą jest to, że Ozone ma strukturę płaską, a nie hierarchiczną. Również, podobnie jak HDFS, dzieli pliki na bloki, także posiada swoje repliki, jednak nie możemy zawierać zagnieżdżonych folderów.
Podstawowa budowa Apache Ozone
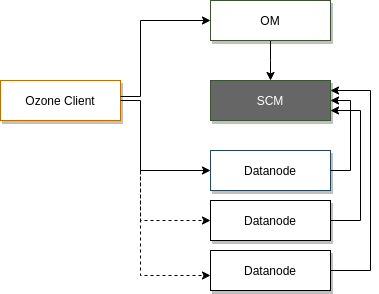
Ozone oczywiście jest systemem rozproszonym – działa na wielu nodach (serwerach/komputerach).
Oto podstawowy opis struktury:
Volumes – podobne do kont użytkowników lub katalogów domowych. Tylko admin może je utworzyć.
Buckets – podobne do folderów. Bucket może posiadać dowolną liczbę keys, ale nie może posiadać innych bucketów.
Keys – podobne do plików.
Ozone zbudowany jest z kilku podstawowych komponentów/serwisów:
Ozone Manager (OM) – odpowiedzialny za namespacy. Odpowiedzialny za wszystkie operacje na volumes, buckets i keys. Każdy volume to osobny root dla niezależnego namespace’u pod OM (to różni go od HDFSa).
Storage Container Manager (SCM) – Działa jako block manager. Ozone Manage requestuje blocki do SCM, do których klientów można zapisać dane.
Data Nodes – działa w ramach Data Nodes HDFSowych lub w uruchamia samodzielnie własne deamony (jeśli działa bez HDFSa)
Ozone oddziela zarządzanie przestrzenią nazw (namespace management) oraz zarządzanie przestrzenią bloków (block space management). To pomaga bardzo mocno skalować się Ozonowi. Ozone Manager odpowiada za zarządzanie namespacem, natomiast SCM za zarządzanie block spacem.
Ozone Manager
Volumes i buckets są częścią namespace i są zarządzane przez OM. Każdy volume to osobny root dla niezależnego namespace’a pod OM. To jedna z podstawowych różnic między Apache Ozone i HDFS. Ten drugi ma jeden root od którego wszystko wychodzi.
Jak wygląda zapis do Ozone?
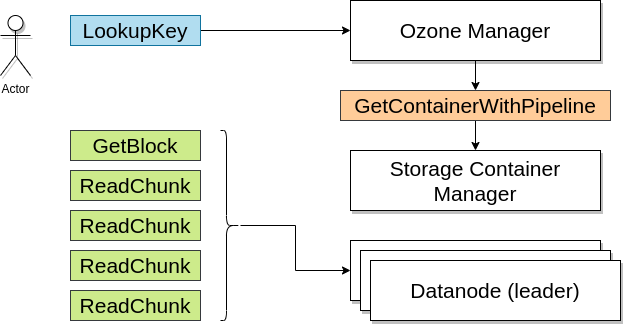
Aby zapisać key do Ozone, client przekazuje do OM, że chce zapisać konkretny key w konkretnym bucket, w konkretnym volume. Jak tylko OM ustali, że możesz zapisać plik w tym buckecie,OM zaalokuje block dla zapisu danych.
Aby zaalokować blok, OM wysyła request do SCM. To on tak naprawdę zarządza Data Nodami. SCM wybiera 3 data nody (najprawdopodobniej na repliki) gdzie klient może zapisać dane. SCM alokuje blok i zwraca block ID do Ozone Managera.
Ozone Manager zapisuje informacje na temat tego bloku w swoich metadanych i zwraca blok oraz token bloku (uprawnienie bezpieczeństwa do zapisu danych na bloku) do klienta.
Klient używa tokena by udowodnić, że może zapisać dane na bloku oraz zapisuje dane na data node.
Gdy tylko zapis jest ukończony na data node, klient aktualizuje informacje o bloku w OM.
Jak wygląda odczyt danych (kluczy/keys) z Ozone?
Klient wysyła request listy bloków do Ozone Manager.
OM zwraca listę bloków i tokenów bloków, dzięki czemu klient może odczytać dane z data nodes.
Klient łączy się z data node i przedstawia tokeny, po czym odczytuje dane z data nodów.
Storage Container Manager
SCM jest głównym nodem, który zarządza przestrzenią bloków (block space). Podstawowe zadanie to tworzenie i zarządzanie kontenerami. O kontenerach za chwilkę, niemniej pokrótce, są to podstawowe jednostki replikacji.
Tak jak napisałem, Storage Container Manager odpowiada za zarządzanie danymi, a więc utrzymuje kontakt z Data Nodami, gra rolę Block Managera, Replica Managera, ale także Certificate Authority. Wbrew intuicji, to SCM (a nie OM) jest odpowiedzialny za tworzenie klastra Ozone. Gdy wywołujemy komendę init, SCM tworzy cluster identity oraz root certificates potrzebne do CA. SCM zarządza cyklem życia Data Node.
SCM do menedżer bloków (block manager). Alokuje bloki i przydziela je do Data Nodów. Warto zawuażyć, że klienci pracują z blokami bezpośrednio (co jest akurat trochę podobne do HDFSa).
SCM utrzymuje kontakt z Data Nodami. Jeśli któryś z nich padnie, wie o tym. Jeśli tak się stanie, podejmuje działania aby naprawić liczbę replik, aby ciągle było ich tyle samo.
SCM Certificate Authority jest odpowiedzialne za wydawanie certyfikatów tożsamości (identity certificates) dla każdej usługi w klastrze.
SCM nawiązuje regularny kontakt z kontenerami poprzez raporty, które te składają. Ponieważ są znacznie większymi jednostkami niż bloki, raportów jest wiele wiele mniej niż w HDFS. Warto natomiast pamiętać, że my, jako klienci, nie komunikujemy się bezpośrednio z SCM.
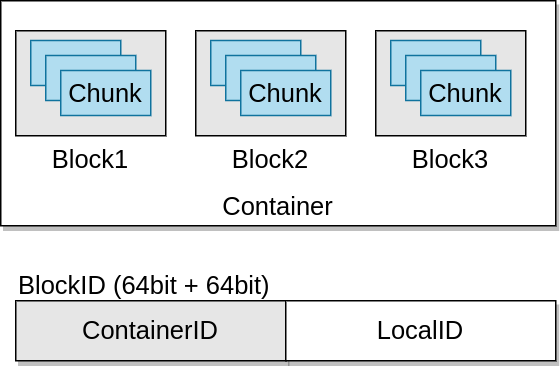
Kontenery i bloki w Ozone(Contrainers and blocks)
Kontenery (containers) to podstawowe jednostki w Apache Ozone. Zawierają kilka bloków i są całkiem spore (5gb domyślnie).
W konkretnym kontenerze znajdziemy ileś bloków, które są porcją danych. Jednak same bloki nie są replikowane. Informacje o blokch nie są też zarządzane przez SCM – są trzymane tylko informacje o kontenerach i to kontenery podlegają replikacji. Kiedy OM requestuje o zaalokowanie nowego bloku do SCM, ten “namierza” odpowiedni kontener i generuje block id, które zawiera w sobie ContainerIs + LocalId (widoczne na obrazku powyżej). Klient łączy się wtedy z Datanode, który przechowuje dany kontener i to datanode zarządza konkretnym blokiem na podstawie LocalId.
Data Nodes
Data Nody to serwery, na których dzieje się prawdziwa, docelowa magia Ozone. To tutaj składowane są wszystkie dane. Warto pamiętać, że to z nimi bezpośrednio łączy się klient. Zapisuje on dane w postaci bloków. Data node agreguje te dane i zbiera do kontenerów (storage containers). W kontenerach, poza danymi, znajdują się też metadane opisujące je.
Jak to wszystko działa? Kiedy chcemy odczytać plik, uderzamy do OM. Ten zwraca nad listę bloków, która składa się z pary ContainerId:LocalId. To dość chude informacje, ale wystarczą, aby można było udać się do konkretnych kontenerów i wyciągnąć konkretne bloki (LocalId to po prostu unikatowy numer ID w ramach kontenera, czyli w ramach dwóch różnych kontenerów moga być dwa bloki o LocalID=1, natomiast w ramach jednego kontenera nie).
Podsumowanie
Mam szczerą nadzieję, że tym artykułem pomogłem odrobinę zrozumieć architekturę Apache Ozone. Przyznam, że pełnymi garściami czerpałem z dokumentacji. Choć – jestem przekonany – jest to pierwszy polski materiał na temat tej technologii, to z pewnością nie jest ostatni. Jestem w trakcie instalowania Ozone na eksperymentalnym klasterku RDFowym i na bieżąco piszę artykuł o doświadczeniach i błędach, jakie napotkałem. Obserwuj RDF na LinkedIn i zapisz się na newsletter, to nie przegapisz!
Jeśli czegoś nie wiem – wchodzę w wyszukiwarkę i zdobywam wiedzę. Można powiedzieć, że wyszukiwarka to swoisty “rdzeń” internetu. Mogę tam znaleźć wszystko. Punkt wyjścia do wiedzy całej ludzkości. Tak jest dzisiaj. Tylko, że 25 lat temu… nikt tak nie myślał. Nawet nie było takiej możliwości. “Szukaj” to znakomita książka, która opisuje rozwój wyszukiwarek internetowych, z Google w roli głównej. Jednak najciekawszą rzeczą jest to, że napisana została 2005 roku. Z dzisiejszej perspektywy wiemy znacznie więcej i możemy zweryfikować niektóre fakty. Zapraszam do pierwszej recenzji książki na blogu RDF –“Szukaj – Jak Google i konkurencja wywołali biznesową i kulturową rewolucję”.
O czym jest, a o czym nie jest książka “Szukaj”?
Cóż, wbrew pozorom (oraz wbrew okładce), nie dostaniemy wcale historii Google. Nie dostajemy tu także życiorysu Siergieja Brina ani Larry’ego Page’a (założycieli Google). Wbrew temu co można pomyśleć czytając tytuł – nie będzie o kształtowaniu współczesnej debaty i problemach z cenzorowaniem treści o zabarwieniu konserwatywnym. Nie będzie, bo książka została napisana w roku 2005, a nie 2020.
Żeby właściwie oddać skalę czasu powiem tylko, że 2005 rok to 7 lat po założeniu Google. Obecnie zbliżają się już… 23 lata technologicznego giganta. Historia Google to niemalże historia Internetu. W czasie, w którym pisane były stronice “Szukaj”, nie było jeszcze Androida, Youtuba (w obecnym kształcie) ani Google Drive. Była za to… wyszukiwarka. Jedna z najnudniejszych usług o jakich można pomyśleć.
Czy na pewno? Książka zręcznie pokazuje, że wcale nie. Pokazuje drogę, jaką przeszły wyszukiwarki oraz cały kontekst. Opisuje rzeczy, które wydają się być z innego świata – długie dyskusje i zastanawianie się, czy opcja wyszukiwarki (nawet na pojedynczej stronie) jest dobrym i potrzebnym pomysłem. John Batelle maluje nam naprawdę kompleksowy obraz – włączając technikalia, aktualny rozwój internetu oraz rywalizację biznesową, a nawet kulturową (poruszany jest wątek chiński). Choć napisałem, że nie jest to książka o Google, to w rzeczywistości dostajemy kawał historii tej firmy. Stajemy się bliskimi obserwatorami przeżyć i przemyśleń dwóch założycieli, pierwszych pracowników firmy oraz ich konkurencji. To wszystko pozwala nam dostrzec, jak dynamiczna była sytuacja oraz jak wiele problemów musiała rozwiązać dwójka doktorantów Stanforda.
Pierwsze wyszukiwarki nie przypominały w niczym dzisiejszych. Na obrazku jeden z pionierów wyszukiwania internetowego – AltaVista
Jak wyglądał internet… 25 lat temu?
Wyobraź sobie, że chcesz się podzielić zdjęciami ze znajomymi. Nie wyślesz ich przez Signal czy Messenger. Nie zamieścisz na Instagramie. Pomyśl sobie, że chcesz się przekwalifikować. Co robisz? Na pewno nie wejdziesz do internetu, żeby poszukać dobrego kursu z danej dziedziny – po prostu nie ma ani takich kursów, ani… możliwości prostego wyszukania. Jedziesz do innego miasta? Zapomnij o GPS – przecież nie jesteś amerykańskim Marine! Nie umieścisz w sieci szybkich informacji, wiadomości sprawdzisz dopiero po wizycie w kiosku a żeby czymkolwiek zapłacić, musisz mieć gotówkę (lub czek).
To nie jest katastroficzna wizja sparaliżowania ludzkości. To nie jest też opis ery kamienia łupanego, wymalowany na ścianie jaskini. To opis naszego świata zaledwie 20-25 lat temu. TAK – było całkiem analogowo! Druga połowa lat 90′ to dopiero raczkujący Internet, raczej nowinka. Pamiętajmy, że chociaż sama technologia Internetu jest bardzo ciekawa, to naprawdę rewolucyjna staje się dopiero wtedy, gdy jest wypełniona treścią. Dziś wiadomo, że w jakiejś formie trzeba być obecnym w Internecie, jeśli prowadzisz działalność. Wtedy było to równie popularne, co współcześnie umieszczanie banerów nad pisuarem w pubie. Tak więc pierwsza rzecz jaką autor nam uświadamia: dzisiaj wiadomo, że na każde pytanie odpowiedź znajdę w internecie, wtedy absolutnie nie było takiego przeświadczenia.
To były czasy tzw. Web 1.0. Czasy twórców i statycznych stron. Użytkownicy byli jedynie biernymi obserwatorami. Przypominało to nieco tak naprawdę tradycyjne media, przede wszystkim gazety, z którymi nie możemy nawiązać żadnej interakcji, ale które możemy przeglądać. Tyle tylko, że Internet był dostępny na ekranie, a nie w formie gazety. No i mieliśmy dostęp do wielu twórców… o ile mieliśmy ich adresy.
Search 1.0 – czyli jak to się zaczęło, z tym wyszukiwaniem?
Archie, australopitek wśród wyszukiwarek
Jednym z ciekawszych aspektów książki jest wycieczka po pierwszych, dawno zapomnianych wyszukiwarkach. W zasadzie jedyne w czym przypominały obecne, to fakt, że istnieje tam jakieś okienko, w które coś możemy wpisać, a na końcu dostajemy jakieś wyniki. Poza tym – absolutnie wszystko było inne. Wszystko zaczęło się od sympatycznie brzmiącej Archie. Aby nadać kontekst, przywołajmy słowa samego Autora:
“W roku 1990 naukowcy i technicy regularnie używali Internetu do składowania prac naukowych, specyfikacji technicznych i innego rodzaju dokumentów na publicznie dostępnych komputerach. Jednak bez znajomości dokładnego adresu komputera i nazwy pliku znalezienie tych archiwów graniczyło z niemożliwością. Program Archie przeszukiwał internetowe archiwa (stąd jego nazwa) i tworzył indeks każdego znalezionego pliku.”
Archie to pierwsza wyszukiwarka, dzięki której można było przeczesywać internetowe archiwa.
Jak wyglądała Archie? Mniej więcej tak jak to widać powyżej. Swoją drogą, Archie miała swoje narodziny 10 września 1990 r. Co prawda było to 3 lata przed narodzinami autora tego artykułu, ale za to urodziny możemy obchodzić niemal razem (09.09);-). Co ciekawe – z wyszukiwarki można skorzystać nawet teraz, pod tym linkiem (choć raczej jedynie w ramach ciekawostki).
Warto jednak powiedzieć w jaki sposób Archie działała (działał?). Wyszukiwarka odbierała zapytania zbudowane ze słów kluczowych. Następnie przeszukiwała archiwa poszukując tych słów w nazwach plików. Po wszystkim, jako wynik zwracała listę miejsc, w których owe pliki znaleziono. Nie jest wielką sztuką dostrzec, że rozwiązanie to było podobne do współczesnych wyszukiwarek podobnie, jak australopitek do nas. Problematyczne było zarówno to, że zwracane nie były pliki a lokalizacje, jak i to, że indeksowane były jedynie tytuły. Trzeba było mieć więc albo wiedzę, że taki dokument istnieje, albo mieć znakomitego nosa.
Altavista, czyli pierwszy mocny przełom
Lata później sprawy zaczęły nieodwracalnie pędzić w kierunku, który mamy współcześnie. Nie chodzi tu jednak o kwestię wyszukiwarek, a o dynamikę rozwoju Internetu. W 1995 roku sieć liczy już 10 mln witryn i rozwija się w absurdalnym tempie 2000% rocznie. Oczywistym staje się, że ogarnięcie takiego zbioru danych będzie bardzo, bardzo trudne. Nie chodzi, pamiętajmy, o samo zebranie (co już jest wyczynem), ale także o przeszukiwanie w czasie rzeczywistym. Potrzeba byłoby jakiegoś… superkomputera.
I tutaj z pomocą przychodzi firma DEC (Digital Equipment Corp.) ze swoją Alta Vistą. Historia powstania tej wyszukiwarki jest niejasna. Powtarzający się jednak motyw jest taki, że firma stała na krawędzi upadku. Jak tlenu potrzebowała pieniędzy oraz dobrego PR. I tu pojawił się pomysł, żeby dla nowego superprocesora napisać coś, co będzie imponującym eksperymentem pokazującym jego możliwości. W ten sposób Louis Monier zabrał się do pracy, w efekcie tworząc przełomową wyszukiwarkę internetową – Alta Vistę. Różniła się od innych obecnych na rynku tym, że nie indeksowała jedynie adresów url, ale całe strony oraz… no własnie, indeksowała je w ogromnym tempie, dzięki wysłaniu “na łowy” nie jednego crawlera, a… tysiąc. Było to możliwe właśnie dzięki procesorowi.
Niestety, Alta Vista została z czasem wyprzedzona przez Google. Po drodze przeszła długą wędrówkę miotając się między rozmaitymi decyzjami biznesowymi, kilkukrotnymi próbami wejścia na giełdę, zmianą właścicieli, aż w końcu żywot swój dokonała w Yahoo! w 2013 roku. Alta Vista jest wzorcowym przykładem tego co dzieje się, gdy nie umiemy dostosować biznesu do zmieniającej się rzeczywistości.
Baza Intencji – wyszukiwanie, jako “rdzeń” Internetu oraz Big Data
Powoli dochodzimy do sedna, które moim zdaniem najmocniej pokazuje jaką potęgę od początku trzyma w swoich rekach Google. Jeśli ktoś nie będzie mógł przebrnąć przez książkę – najlepiej przeczytać chociaż pierwszy rozdział “Baza Danych Intencji”. Bardzo często w debacie przewija się pytanie o to kto jest na naszym świecie najbardziej wpływowy. Wymieniamy tu zwykle polityków i biznesmenów. No więc jak myślisz, jaki rodzaj biznesu ma największy wpływ na nas wszystkich? Dostawcy ropy? Media? Blisko. Kiedy nad tym pomyślimy, dojdziemy do oczywistego wniosku, że największy wpływ mają na nas ci, którzy nas najlepiej znają. Zwykle to była nasza rodzina, przyjaciele, czasami przebiegli politycy.
Problem polega jednak na tym, że oni wszyscy widzą pewną powłokę, którą chcemy (lub nie) im sprzedać. Nawet jeśli z kimś rozmawiamy, modelujemy intencjami, które z nas wychodzą. A co, jeśli… mieć dostęp do samego wnętrza naszego mózgu? Bez wszystkich filtrów, po prostu – jeśli znać nasze myśli, które wychodzą prosto z mózgu (czy też “z serca”)?
Właśnie w takiej pozycji usadził się Google. Jak pisze John Battelle, zdał sobie sprawę z tego jaką potęgę trzyma Google, gdy przeglądał wydanie Google Zeitgeist podsumowujące 2001 rok (Google Zeitgeist to poprzednik Google Trends). w tamtym czasie najpopularniejszymimi wyszukiwania były: Nostradamus, CNN, World Trade Center, Harry Potter, wąglik. Lista tracących popularność fraz wskazywała, że ludzie przestawali interesować się głupotami: Pokemon, Napster, Big Brother, X-Men, zwyciężyni teleturnieju “Kto chce poślubić multimilionera”.
Jak napisał Autor:
“Byłem w szoku. Zeitgeist ukazał mi, że Google nie tylko trzyma rękę na pulsie kultury, ale tkwi bezpośrednio w jej systemie nerwowym. Tak wyglądało moje pierwsze zetknięcie z tym, co później nazwałem Bazą Danych Intencji – żywym artefaktem o wielkiej mocy. >>Dobry Boże<<, pomyślałem sobie, Google wie, czego szukają ludzie! Stwierdziłem, biorąc pod uwagę miliony zaputań zmierzających każdej godziny do serwerów Google, że firma ta siedzi na kopalni złota. Na podstawie zgromadzonych w niej informacji o ludzkich zamiarach można by utworzyć wiele przedsiębiorstw prasowychL w istocie pierwsze – eksperymentalny >>Google News<< – już powstało. Czy Google nie mogło założyć też firmy zajmującej się badaniami i marketingiem, która mogłaby precyzyjnie informować o tym, co ludzie kupują, co chcą a czego unikają?”
I tutaj właśnie leży sedno. Wyniki wyszukiwania są zakryte przed znajomymi. Znamy je tylko my i maszyny Google. Udajemy się tam tylko wtedy, gdy chcemy coś znaleźć, czegoś się dowiedzieć. Szkodzilibyśmy więc sobie bez pożytku, gdybyśmy udawali. Jesteśmy szczerzy, naturalni. Google dokładnie wie, czego poszukujemy, czym żyjemy, czego pragniemy. To właśnie autor nazwał Bazą Danych Intencji. Kto więc może być najbardziej wpływowy? Oczywiście – firma, która ma dostęp do naszego serca, naszej świadomości, pragnień… i która to firma może na tym robić pieniądze oraz zręcznie modelować wynikami.
Moim zdaniem właśnie dlatego przeszukiwanie to samo sedno zarówno internetu, jak i Big Data. Docieramy do samego sedna i przetwarzamy najbardziej “szczere” dane, aby poznać prawdę o nas. Jakkolwiek górnolotnie by to nie brzmiało, jest to prawda i olbrzymia moc. A jak wiadomo – “Z wielką mocą wiąże się wielka odpowiedzialność ;-).
Google wczoraj, Google dzisiaj, czyli jak autor widział przyszłość?
Podtytuł ten to parafraza rozdziału “Google dzisiaj, Google jutro”, który jest pewną próbą przewidzenia przyszłości. Z dzisiejszej perspektywy, po niemal 16 latach, możemy powiedzieć, czy trafną;-).
Rywalizacja z Yahoo (i Microsoftem)
Autor zaznacza, że:
“Konkurencja Google jest bardzo liczna, ale najważniejszym z rywali, przynajmniej w latach 2005-2006 jest Yahoo. W roku 2007 trzeba też będzie stawić czoła przygotowującemu najcięższą artylerię Microsoftowi, ale na dzień dzisiejszy głównym wrogiem Google jest Yahoo”
Zacznijmy od tej drugiej części – Microsoft. Być może Autor miał na myśli wyszukiwarkę Msn Search, która weszła jednak do użycia w 2005 roku. W chwili inauguracji indeksowała 5 mld stron i była używana przez 1/6 internautów. Następnie przekształciło się w Windows Live, aby zostać przemianowane na Bing.
Jeśli chodzi o Yahoo, nie była i nie jest to stricte wyszukiwarka. Oczywiście funkcja wyszukiwarki oczywiście także istnieje, natomiast inne elementy są znacznie silniejszym atutem firmy (jak na przykład Yahoo Finance).
Jak wyglądają obecnie procentowe udziały w całym torcie wyszukiwarek na świecie?
Google – 91.95%
Bing – 2.93%
Yahoo – 1.51%
Można powiedzieć, że z jednej strony faktycznie najsilniejsza konkurencja pozostała najsilniejszą konkurencją. Tyle, że realnie Google jest monopolistą.
Wielki system operacyjny WWW działający na infrastrukturze Google
Najbardziej śmiała wizja przytoczona przez autora to utworzenie wielkiego systemu operacyjnego, który łączy różne urządzenia i usługi. Taki system miałby działać na infrastrukturze Google. Następuje tu analogia do Microsoftu, który postawił komputer w każdym domu i zainstalował na nim Windowsa. Niedługo – według Battella – będziemy pracować na jednym wielki systemie. Tam będą składowane dane, tam będziemy rozmawiać, pracować itd.
Dzięki temu Google uda się zrealizować swoją misję o “uporządkowaniu światowych zasobów informacji, aby stały się one powszechnie dostępne i użyteczne”.
“Misja Google, polegająca na porządkowaniu i udostępnianiu światowych informacji, pozwala spółce udostępniać wszystkie usługi, które mogą się naleźć na komputerowej platformie – od codziennych aplikacji jak przetwarzanie tekstu i arkusze kalkulacyjne (w tej chwili domena Microosftu), do bardziej futurystycznych usług, takich jak wideo na żądanie, składowanie osobistych mediów, albo nauka na odległość.“
Cóż, sądzę że ta śmiała wizja została w większości zrealizowana. Co prawda w pomyśle Autora Google byłby hegemonem, który staje się głównym dostawcą całego życia (dalej jest mowa także o dostarczaniu kablówki, bycie uniwersytetem itd). W tym zakresie nie udało się Google zawłaszczyć całego tortu – moim zdaniem na szczęście. Są inne przestrzenie, takie jak Microsoft Teams, Zoom, wirtualne dyski itd.
Znakomita większość jednak… ma miejsce! Mamy przecież Hangouts, mamy Google Drive (w tym dokumenty i arkusze kalkulacyjne). Co więcej – mamy androida, a nawet Google Street View, tak więc firma weszła na obszary, które (pozornie) z wyszukiwaniem nie mają wiele wspólnego. Stanowi to naprawdę wysoki kunszt wizjonerski Johna Battella i należy mu oddać szacunek.
Google Video, poprzednik YouTube. Wielki gigant nie zawsze może rywalizować z niezależnymi usługami.
Youtube
“Kolejnym ważnym trendem jest wzrost popularności wideo. W zeszłym roku YouTube, serwis udostępniania plików filmowych, stał się jednym z największych w sieci, a w reklamę wideo zainwestowano setki milionów dolarów. Mimo, że produkt Google Video jest nowatorski i popularny, firma ta w oczach opinii publicznej przegrała z YouTube. Czy Google pozostanie miłe dla firm typu YouTube, indeksując ich zawartość i ograniczając się do roli centrali telefonicznej, tak jak w przypadku tekstu? Czy też spróbuje rywalizować poprzez własną usługę, z nadzieją na przechwycenie całego naszego zainteresowania, tak jak to robiły stare sieci (ABC, CBS, NBC)? Nie znamy jeszcze odpowiedzi, ale same pytania są bardzo ciekawe”
To chyba mój ulubiony cytat;-). Google Video można zobaczyć powyżej (obecnie także dostępne, ale w zupełnie innym celu i formie). Tak więc, cóż… dziś już znamy odpowiedzi na te pytania. Google wykupiło YouTube, pozyskując tym samym ogromną rzeczywistość, rzeczywistość filmów. Nawiasem mówiąc, poprzez Youtube (i system rekomendacji) ma gigantyczne możliwości oddziaływania na nasz styl myślenia.
Podsumowanie
John Battelle wykonał kawał roboty pokazując historię wyszukiwania. Zrobił jednak jeszcze więcej roboty, ukazując jak bardzo potężnym sednem całej branży może być wyszukiwanie. Z całą pewnością wrażenie powinno zrobić z dzisiejszej perspektywy to, do jakiego punktu doszedł Google. Nie jest to już jedynie wyszukiwarka – to ogromny moloch, który dostarcza nam całą gamę usług, z których korzystamy. Uczy się każdego naszego ruchu i upraszcza życie. Ma to oczywiście swoją cenę. Pytanie “czy jesteśmy gotowi ją płacić?” pozostaje otwarte – do odpowiedzi przez każdego z osobna.
Ja ze swojej strony na pewno polecam “Szukaj”. Lektura pouczająca i mocno wgryzająca się w całą sprawę.
Polecam także oczywiście naszą stronę na LinkedIn oraz newsletter, dzięki któremu zostaniemy w kontakcie;-).
Machine Learning w Sparku? Jak najbardziej! W poprzednim artykule pokazałem efekty prostego mechanizmu do porównywania tekstów, który zbudowałem. Całość jest zrobiona w Apache Spark, co niektórych może dziwić. Dzisiaj chcę się podzielić tym jak dokładnie zbudować taki mechanizm. Kubki w dłoń i lecimy zanurzyć się w kodzie!
Powiem jeszcze, że tutaj pokazuję jak zrobić to w prostej, batchowej wersji. Po prostu uruchomimy cały job sparkowy wraz z tekstem i dostaniemy odpowiedzi. W innym artykule jednak pokażę jak zrobić także joba streamingowego. Dzięki temu stworzymy mechanizm, który będzie nasłuchiwał i naprawdę szybko będzie zwracał wyniki w czasie rzeczywistym (mniej więcej, w zależności od zasobów – czas ocekiwania to kilka, kilkanaście sekund). Jeśli chcesz dowiedzieć się jak to zrobić – nie zapomnij zasubskrybować bloga RDF!
Spark MlLib
Zacznijmy od pewnej rzeczy, żeby nam się nie pomyliło. Spark posiada bibliotekę, która służy do pracy z machine learning. Nazywa się Spark MlLib. Problem polega na tym, że wewnątrz rozdziela się na dwie pod-biblioteki (w scali/javie są to po prostu dwa pakiety):
Spark MlLib – metody, które pozwalają na prace operując bezpośrednio na RDD. Starsza część, jednak nadal wspierana.
Spark Ml – metody, dzięki którym pracujemy na Datasetach/Dataframach. Jest to zdecydowanie nowocześniejszy kawałek biblioteki i to z niego właśnie korzystam.
Ta sama uwaga odnośnie “provided” co w przypadku mavena.
Spark NLP od John Snow Labs
Chociaż Spark posiada ten znakomity moduł SparkMlLib, to niestety brak w nim wielu algorytmów. Zawierają się w tych brakach nasze potrzeby. Na szczęście, luka została wypełniona przez niezależnych twórców. Jednym z takich ośrodków jest John Snow Labs (można znaleźć tutaj). Samą bibliotekę do przetwarzania tekstu, czyli Spark-NLP zaciągniemy bez problemu z głównego repozytorium Mavena
Dodawanie dependencji, jeśli korzystamy z Mavena (plik pom.xml):
Dodawanie dependencji jeśli korystamy z SBT (plik build.sbt):
libraryDependencies += "com.johnsnowlabs.nlp" %% "spark-nlp" % "3.3.4" % Test
Dane
Dane same w sobie pochodzą z 3 różnych źródeł. I jak to bywa w takich sytuacjach – są po prostu inne, pomimo że teoretycznie dotyczą tego samego (tweetów). W związku z tym musimy zrobić to, co zwykle robi się w ramach ETLów: sprowadzić do wspólnej postaci, a następnie połączyć.
Dane zapisane są w plikach CSV. Ponieważ do porównywania będziemy używać tylko teksty, z każdego zostawiamy tą samą kolumnę – text. Poza tą jedną kolumną dorzucimy jednak jeszcze jedną. To kolumna “category”, która będzie zawierać jedną z trzech klas (“covid”, “finance”, “grammys”). Nie będą to oczywiście klasy służące do uczenia, natomiast dzięki nim będziemy mogli sprawdzić potem na ile dobrze nasze wyszukiwania się “wstrzeliły” w oczekiwane grupy tematyczne. Na koniec, gdy już mamy identyczne struktury danych, możemy je połączyć zwykłą funkcją “union”.
Gdy pracujemy z NLP, bazujemy oczywiście na tekście. Niestety, komputer nie rozumie tekstu. A co rozumie komputer? No jasne, liczby. Musimy więc sprowadzić tekst do poziomu liczb. Konkretnie wektorów, a jeszcze konkretniej – embeddingów. Embeddingi to nisko-wymiarowe reprezentacje czegoś wysoko-wymiarowego. W naszym przypadku będzie to tekst. Czym dokładnie są embeddingi, dobrze wyjaśnione jest na tej stronie. Na nasze, uproszczone potrzeby musimy jednak wiedzieć jedno: embeddingi pozwalają zachować kontekst. Oznacza to w dużym skrócie, że słowo “pizza” będzie bliżej słowa “spaghetti” niż słowa “sedan”.
Sprowadzanie do postaci liczbowej może się odbyć jednak dopiero wtedy, gdy odpowiednio przygotujemy tekst. Bardzo często w skład takiego przygotowania wchodzi oczyszczenie ze “śmieciowych znaków” (np. @, !, ” itd) oraz tzw. “stop words”, czyli wyrazów, które są spotykane na tyle często i wszędzie, że nie opłaca się ich rozpatrywać (np. I, and, be). Oczywiście może to rodzić różne problemy – np. jeśli okroimy frazy ze standardowych “stop words”, wyszukanie “To be or not to be” będzie… puste. To jednak już problem na inny czas;-).
Do przygotowania często wprowadza się także tokenizację, czyli podzielenie tekstu na tokeny. Bardzo często to po prostu wyciągnięcie wyrazów do osobnej listy, aby nie pracować na stringu, a na kolekcji wyrazów (stringów). Spotkamy tu także lemmatyzację, stemming (obie techniki dotyczą sprowadzenia różnych słów do odpowiedniej postaci, aby móc je porównywać).
W naszym przypadku jednak nie trzeba będzie robić tego wszystkiego. Jedyne co musimy, to załączyć DocumentAssembler. Jest to klasa, która przygotowuje dane do formatu zjadliwego przez Spark NLP.
Po zastosowaniu dostajemy kolumnę, która ma następującą strukturę:
W naszym kodzie najpierw inicjalizujemy DocumentAssembler, wykorzystamy go nieco później. Przy inicjalizacji podajemy kolumnę wejściową oraz nazwę kolumny wyjściowej:
val docAssembler: DocumentAssembler = new DocumentAssembler().setInputCol("text")
.setOutputCol("document")
Zastosowanie USE oraz budowa Pipeline
Jak już napisałem, my wykorzystamy Universal Sentence Encoder (USE). Dzięki tym embeddingom całe frazy (tweety) będą mogły nabrać konktekstu. Niestety, sam “surowy” Spark MlLib nie zapewnia tego algorytmu. Musimy tu zatem sięgnąć po wspomniany już wcześniej Spark NLP od John Snow Labs (podobnie jak przy DocumentAssembler). Zainicjalizujmy najpierw sam USE.
val use: UniversalSentenceEncoder = UniversalSentenceEncoder.pretrained()
.setInputCols("document")
.setOutputCol("sentenceEmbeddings")
Skoro mamy już obiekty dosAssembler oraz use, możemy utworzyć pipeline. Pipeline w Spark MlLib to zestaw powtarzających się kroków, które możemy razem “spiąć” w całość, a następnie wytrenować, używać. Wyjście jednego kroku jest wejściem kolejnego. Wytrenowany pipeline (funkcja fit) udostępnia nam model, który możemy zapisać, wczytać i korzystać z niego.
Nasz pipeline będzie bardzo prosty:
val pipeline: Pipeline = new Pipeline().setStages(Array(docAssembler, use))
val fitPipeline: PipelineModel = pipeline.fit(tweetsDF)
Gdy dysponujemy już wytrenowanym modelem, możemy przetworzyć nasze dane (funkcja transform). Po tym kroku otrzymamy gotowe do użycia wektory. Niestety, USE zagnieżdża je w swojej strukturze – musimy więc je sobie wyciągnąć. Oba kroki przedstawiam poniżej:
val vectorizedTweetsDF: Dataset[Row] = fitPipeline.transform(tweetsDF)
.withColumn("sentenceEmbeddings", org.apache.spark.sql.functions.explode(col("sentenceEmbeddings.embeddings")))
Znakomicie! Mamy już tweety w formie wektorów. Teraz należy jeszcze zwektoryzować tekst użytkownika. Tekst będzie przechowywany w Dataframe z jednym wierszem (właśnie owym tekstem) w zmiennej sampleTextDF. Po wektoryzacji usunę zbędne kolumny i zmienię nazwy tak, aby było wiadomo, że te wektory dotyczą tekstu użytkownika, a nie tweetów (przyda się później, gdy będziemy łączyć ze sobą oba Dataframy).
val vectorizedUserTextDF: Dataset[Row] = fitPipeline.transform(sampleTextDF)
.drop("document")
.withColumn("userEmbeddings", org.apache.spark.sql.functions.explode(col("sentenceEmbeddings.embeddings")))
.drop("sentenceEmbeddings")
Implementacja cosine similarity
Uff – sporo roboty za nami, gratuluję! Mamy już tweety oraz tekst użytkownika w formie wektorów. Czas zatem porównać, aby znaleźć te najbardziej podobne! Tylko pytanie, jak to najlepiej zrobić? Muszę przyznać że trochę czasu zajęło mi szukanie algorytmów, które mogą w tym pomóc. Finalnie wybór padł na cosine similarity. Co ważne – nie jest to żaden super-hiper-ekstra algorytm NLP. To zwykły wzór matematyczny, znany od dawna, który porównuje dwa wektory. Tak – dwa najzwyklejsze, matematyczne wektory. Jego wynik zawiera się między -1 a 1. -1 to skrajnie różne, 1 to identyczne. Nas zatem będą interesować wyniki możliwie blisko 1.
Problem? A no jest. Spark ani scala czy java nie mają zaimplementowanego CS. Tu pokornie powiem, że być może po prostu do tego nie dotarłem. Jeśli znasz gotową bibliotekę do zaimportowania – daj znać w komentarzu! Nie jest to jednak problem prawdziwy, bowiem możemy rozwiązać go raz dwa. Samodzielnie zaimplementujemy cosine similarity w sparku, dzięki UDFom (User Defined Function).
Najpierw zacznijmy od wzoru matematycznego:
Następnie utwórzmy klasę CosineSimilarityUDF, która przyjmuje dwa WrappedArrays (dwa wektory), natomiast zwraca zwykłą liczbę zmiennoprzecinkową Double. Wewnątrz konwertuję tablice na wektory, wykorzystuję własną metodę magnitude i zwracam odległość jednego wektora od drugiego.
Klasa CosineSimilarityUDF
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.sql.api.java.UDF2
import scala.collection.mutable
class CosinSimilarityUDF extends UDF2[mutable.WrappedArray[Float], mutable.WrappedArray[Float], Double]{
override def call(arr1: mutable.WrappedArray[Float], arr2: mutable.WrappedArray[Float]): Double = {
val vec1 = Vectors.dense(arr1.map(_.toDouble).toArray)
val vec2 = Vectors.dense(arr2.map(_.toDouble).toArray)
val mgnt1 = magnitude(vec1)
val mgnt2 = magnitude(vec2)
vec1.dot(vec2)/(mgnt1*mgnt2)
}
def magnitude(vector: Vector): Double={
val values = vector.toArray
Math.sqrt(values.map(i=>i*i).sum)
}
}
Znakomicie – po utworzeniu tego UDFa, możemy śmiało wykorzystać go do obliczenia podobieństw między każdym z tweetów a tekstem użytkownika. Aby to uczynić, najpierw rejestrujemy naszego UDFa. Polecam to co zawsze polecam na szkoleniach ze Sparka – zrobić to zaraz po inicjalizacji SparkSession. Dzięki temu utrzymamy porządek i nie będziemy się martwić, jeśli w przyszłości w projekcie ktoś będzie również chciał użyć UDFa w nieznanym obecnie miejscu (inaczej może dojść do próby użycia UDFa zanim zostanie zarejestrowany).
val cosinSimilarityUDF: CosinSimilarityUDF = new CosinSimilarityUDF()
sparkSession.udf.register("cosinSimilarityUDF", cosinSimilarityUDF, DataTypes.DoubleType)
Wróćmy jednak na sam koniec, do punktu w którym mamy już zwektoryzowane wszystkie teksty. Najpierw sprawimy, że każdy tweet będzie miał dołączony do siebie tekst użytkownika. W tym celu zastosujemy crossjoin (artykuł o sposobach joinów w Sparku znajdziesz tutaj). Następnie użyjemy funkcji withColumn, dzięki której utworzymy nową kolumnę – właśnie z odległością. Wykorzystamy do jej obliczenia oczywiście zarejestrowany wcześniej UDF.
val dataWithUsersPhraseDF: Dataset[Row] = vectorizedTweetsDF.crossJoin(vectorizedUserTextDF)
val afterCosineSimilarityDF: Dataset[Row] = dataWithUsersPhraseDF.withColumn("cosineSimilarity", callUDF("cosinSimilarityUDF", col("sentenceEmbeddings"), col("userEmbeddings"))).cache()
Na sam koniec pokażemy 20 najbliższych tekstów, wraz z kategoriami. Aby uniknąć problemów z potencjalnymi “dziurami”, odfiltrowujemy rekordy, które w cosineSimilarity nie mają liczb. Następnie ustawiamy kolejność na desc, czyli malejącą. Dzięki temu dostaniemy wyniki od najbardziej podobnych do najmniej podobnych.
I to koniec! Wynik dla hasła “The price of lumber is down 22% since hitting its YTD highs. The Macy’s $M turnaround is still happening” można zaobserwować poniżej. Więcej wyników – przypominam – można zaobserwować w poprzednim artykule;-).
Wyniki dla mechanizmu text similarity w Apache Spark.
Podsumowanie
Mam nadzieję, że się podobało! Daj znać koniecznie w komentarzu i prześlij ten artykuł dalej. Z pewnością to nie koniec przygody z Machine Learning w Sparku na tym blogu. Zostań koniecznie na dłużej i razem budujmy polskie środowisko Big Data;-). Jeśli chcesz pozostać z nami w kontakcie – zapisz się na newsletter lub obserwuj RDF na LinkedIn.
Pamiętaj także, że prowadzimy szkolenia z Apache Spark. Jakie są? Przede wszystkim bardzo mięsiste i tak bardzo zbliżone do rzeczywistości jak tylko się da. Pracujemy na prawdziwych danych, prawdziwym klastrze. Co więcej – wszystko to robimy w znakomitej atmosferze, a na koniec dostajesz garść materiałów!Kliknij tutaj i podrzuć pomysł swojemu szefowi;-).

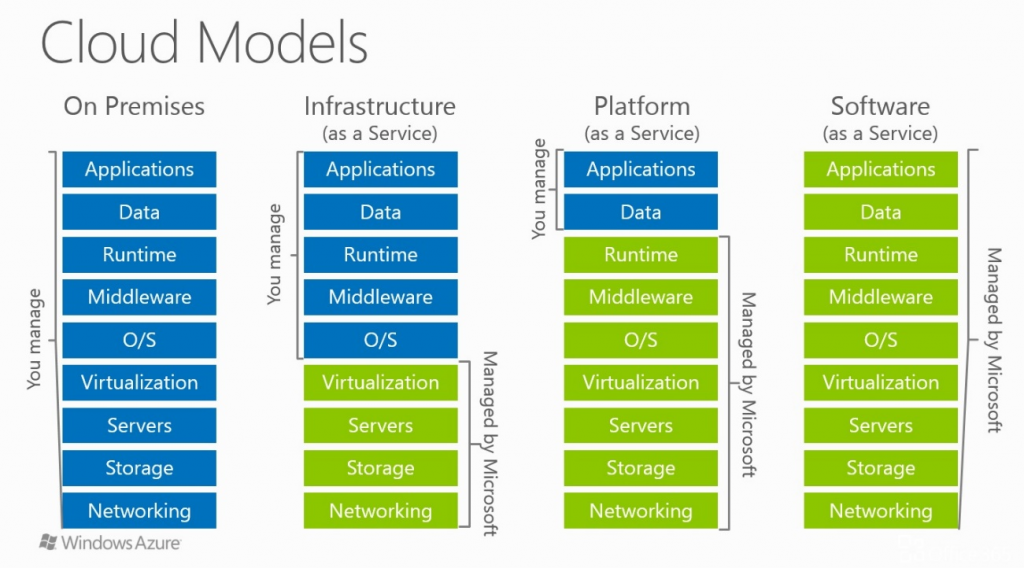
")