
XXI wiek to okres głębokiej rewolucji w kwestiach kosmicznych. Najpierw kosmos został kompletnie zdeprecjonowany (łącznie z rozważaniami nad likwidacją NASA za Barracka Obamy). Następnie powstały bezprecedensowe próby rozwinięcia podboju kosmosu przez… sektor prywatny, z Elonem Muskiem na czele. Potem do gry weszli Chińczycy, którzy postawili Stanom Zjednoczonym potężne wyzwanie i… zaczęło się. Cała ta wielka przygoda nie mogła oczywiście odbyć się bez nowoczesnych technologii przetwarzania danych. Tak Big Data weszła do New Space.
New Space
Sektor prywatny pokazał, że do kosmosu można podchodzić w zupełnie nowy sposób. “Po rynkowemu” – z konkurencją, obniżając ceny, grając jakością, wskazując zupełnie nowe pola do rozwoju, a nade wszystko – robiąc na tym solidny biznes.
Odpowiedzią na rozwój sytuacji po stronie Chin oraz rodzących się nowych możliwości były śmiałe pomysły rządu Amerykańskiego – program powrotu człowieka na księżyc “Artemis” (wraz z Artemis accords) oraz utworzenie Space Force (sił kosmicznych).
Powstała całkowicie nowa domena – ochrzczona jako New Space. Wraz z “Baronami kosmosu” (wielkimi przedsiębiorcami wykładającymi swoje pieniądze na rozwój sektora kosmicznego), rywalizacją między mocarstwami i… coraz szybszym postępem technologicznym, który wykorzystywany jest obficie w życiu codziennym milionów osób.
A teraz pytanie retoryczne: czy mogą tak olbrzymie posunięcia technologiczne obyć się bez Big Data? Odpowiedź jest znana. I właśnie dlatego czas liznąć temat Big Data w New Space.
W tym artykule chcę podejść do sprawy bardzo ogólnie, fragmentarycznie i technicznie zarazem. Przedstawię kilka miejsc o których wiemy, że wykorzystywane są technologie Big Data oraz jakie dokładnie. Niech będzie to zaledwie zajawką tego olbrzymiego tematu, jakim jest Big Data w kosmosie. Będziemy go zgłębiać w późniejszych materiałach, ale teraz – po prostu liźnijmy tą fascynującą rzeczywistość;-)
Big Data w JPL (NASA)
Pierwszym kandydatem, którego powinniśmy odwiedzić jest amerykańska NASA, a konkretnie JPL. Jet Propulsion Laboratory to centrum badawcze NASA położone w Kalifornii, które odpowiada za… naprawdę całą masę rzeczy. Niektórzy utożsamiają JPL (JPL – nie JBL, czyli firmy od naprawdę fajnych głośników;-)) z pracą nad łazikami. Słusznie, ale rzeczy które leżą w ich zasięgu jest cała masa.

Według JPL na potrzeby NASA zbierane są setki terabajtów… każdej godziny. Setki Terabajtów! Czy jesteśmy w stanie wyobrazić sobie tak gigantyczne dane? Wystarczy pomyśleć o liczbach, które się generują po miesiącu, dwóch, trzech latach… No jednym słowem: kosmos.
Czego wykorzystują do przetwarzania i analizy takich potwornych ilości danych amerykańscy inżynierowie z NASA? Mamy tu dobrze znane name technologie. Z pewnością jest ich więcej, ja dotarłem do takich jak:
- Hadoop
- Spark
- Elasticsearch + Kibana
Apache Spark w JPL (NASA) – SciSpark
Oczywiście szczególnie mocno, jako freaka na tym punkcie, cieszy mnie użycie Sparka;-). Jeśli chcesz się dowiedzieć na jego temat coś więcej – dobrze będzie jak zaczniesz od mojej serii “Zrozumieć Sparka”. Pytanie – do czego wykorzystywany jest Apache Spark w JPL? Oczywiście do przetwarzania zrównoleglonego danych pochodzących z łazików, satelit i czego tam jeszcze nie mają.
Co ciekawe jednak, inżynierowie big data w JPL utworzyli osobny program, który nazwali SciSpark. Program jest już niestety zarzucony, ale warto rzucić na niego okiem. Nie znalazłem informacji o przerwaniu prac, jednak wskazują na to przestarzałe treści, oddanie projektu fundacji Apache oraz ostatnie commity z 2018 roku. Na czym jednak polegał SciSpark? Jak wiadomo NASA i generalnie technologie kosmiczne to nie tylko wyprawy na Marsa, Księżyc i badanie czarnych dziur w galaktykach odległych o miliard lat świetlnych. To także, a może przede wszystkim, poznawanie naszego miejsca do życia – Ziemi. I program SciSpark powstał właśnie po to, aby pomagać w przetwarzaniu danych dotyczących naszego środowiska, zmian klimatycznych itd. I tak Big Data pomaga nie tylko w eksploracji “space”, ale także “ze space” pomaga poznawać Ziemię.
SciSpark Technicznie
Wchodząc w temat bardzo technicznie – program został napisany przede wszystkim w Scali. Chociaż twórcy zdają sobie sprawę, z istnienia PySparka oraz tego, że python jest naturalnym językiem Data Sciencystów, uznali że nie będzie odpowiedni ze względów wydajnościowych. Jak mówią sami:
“Ten Spark (w scali – dopisek autora) został wybrany by uniknąć znanych problemów związanych z opóźnieniami (latency issue) wynikających z narzutu komunikacyjnego spowodowanego kopiowaniem danych z workerów JVM do procesu deamona Pythona w środowisku PySpark. Co więcej – chcemy zmaksymalizować obliczenia w pamięci, a w PySparku driver JVM zapisuje wynik do lokalnego dysku, a następnie wczytuje przez proces Pythona”.
Trzon SciSpark polega na rozszerzeniu sparkowych struktur RDD (Resilient Distributed Dataset) i utworzeniu nowych – sRDD (Scientific Resilient Distributed Dataset). Struktury te mają być dostosowane bardziej do wyzwań naukowców. W jaki sposób dokładnie, z chęcią zgłębię kod SciSparka i napiszę o tym osobny artykuł, dla chętnych geeków;-).
Poza Sparkiem, SciSpark posiada oczywiście całą architekturę systemu – z HDFSem, użytkownikami i interfejsem użytkownika (UI) włącznie. Poniżej ona – dla ciekawskich;-).
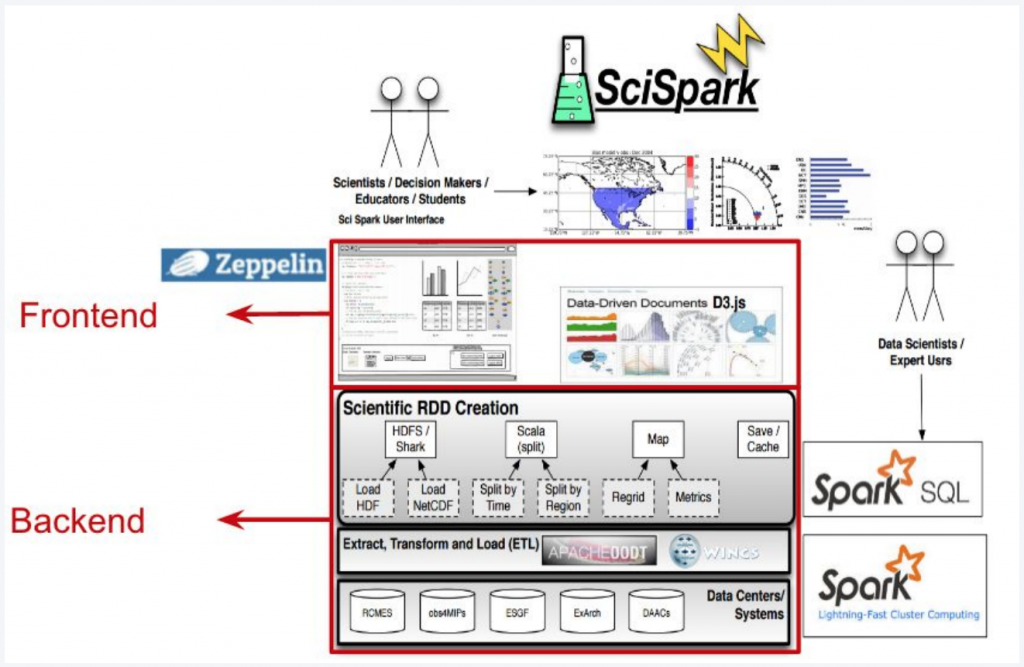
Co ciekawe, SciSpark został upubliczniony i udostępniony fundacji Apache. Efekt jest oczywisty – teraz także i Ty możesz przeczesać kod, który pierwotnie tworzyli inzynierowie big data z NASA. Publiczne repozytorium znajdziesz tutaj.
Hadoop w NASA
Oczywiście przetwarzanie przetwarzaniem, ale gdzieś trzeba te dane przechowywać. Służy ku temu kolejna świetnie znana nam technologia, czyli Hadoop. Konkretniej być może warto powiedzieć hadoopowym systemie plików, czyli HDFS. To bardzo intuicyjny i dość oczywisty wybór, ponieważ HDFS pozwala rozproszyć pliki na wielu maszynach, co w przypadku tak ogromnych danych jest absolutnie niezbędne.
Prawdopodobnie – tu moja osobista opinia – z biegiem lat będzie trzeba przerzucić się na coś “nowszej generacji” z powodu różnych problemów i ograniczeń HDFSa. Być może dobrym pomysłem byłoby wykorzystanie Apache Ozone. Nie znalazłem informacji czy ktokolwiek w NASA wykorzystuje ten system z przyczyn dość banalnych (pomyśl tylko co wyskoczy gdy wpiszesz “NASA Ozone” w wyszukiwarkę). Wydaje mi się jednak – po pierwszych próbach wykorzystania Ozone, że musi w Wiśle jeszcze trochę wody upłynąć, zanim technologia dojrzeje.
W kontekście storowania plików, warto wspomnieć jakie to dokładnie są pliki. Oczywiście w systemach NASA budowane są liczne ETL’e, a więc i surowe pliki z pewnością są bardzo rozmaitych formatów. Jeśli jednak dane są już przetworzone, to z grubsza zapisywane są w dwóch formatach:
- HDF – czyli Hierarchical Data format – to format plików, który został wymyślony już w ubiegłym wieku. Od początku projektowany był tak, żeby mógł przechowywać duże dane. Od początku też – co ważne – wykorzystywany był przez NASA. Nie jest wielką tajemnicą, że tego typu instytucje nie mają zwrotności bolidu F1. Jeśli już do czegoś się przyspawają, pozostanie to z nimi na wieki;-). Więcej na temat HDF można przeczytać w tym dokumencie amerykańskiej agencji.
- NetCDF – czyli Network Common Data Form – to z kolei format plików (i związanych z nimi bibliotek), które przeznaczone są do przechowywania danych naukowych. Co ciekawe, pierwotnie NetCDF bazowało na koncepcji Common Data Format opracowanej przez… NASA. Potem jednak NetCDF poszło swoją drogą. To także jest format, który został zapoczątkowany już kilkadziesiąt lat temu.
Elasticsearch w JPL
Zasadniczo problem był następujący: jak w czasie rzeczywistym odtwarzać i przeglądać dane telemetryczne z bardzo, bardzo odległych źródeł. Jednym z najważniejszych był łazik Curiosity. Ten oddalony od nas o 150 milionów mil badał powierzchnie marsa (w rzeczywistości wartość ta dynamicznie się zmienia wraz z krążeniem obu planet wokół słońca). Trzeba było wykorzystać nowoczesne technologie Big Data. Jak może to wyglądać w praktyce? Przykład podaje Tom Soderstrom, Chief Technology and Innovation Officer, and Dan Isla, IT Data Scientist.
“Jeśli udałoby nam się dokładnie przewidzieć parametry termiczne, czas jazdy Curiosity mogłaby wzrosnąć dramatycznie, co mogłoby nas doprowadzić do przełomowych odkryć. I odwrotnie – błąd mógłby poważnie wpłynąć na misję za dwa miliardy dolarów.”

Wcześniej inżynierowie JPL żmudnie zbierali dane i wrzucali je do powerpointa, gdzie potem analitycy mogli je analizować. Trwało to kupę czasu i cóż… z naszej dzisiejszej perspektywy wygląda to wręcz nieprawdopodobnie głupio. Możemy sobie tylko wyobrazić jaką rewolucję wprowadziło zastosowanie technologii Big Data. Konkretnie inżynierowie big data z NASA napisali całą platformę, nazwaną Streams, dzięki której dane mogły przychodzić w czasie “rzeczywistym” (o ile można tak nazywać komunikację z Marsem), a następnie być analizowane i przeszukiwane na bieżąco.
Właśnie w tym przeszukiwaniu i analizowaniu pomógł Elasticsearch wraz ze swoją wierną towarzyszką Kibaną. Dzięki spojrzeniu na problem przeglądania danych telemetrycznych jak na problem wyszukiwania (search problem) można było zaprzegnąć ES i rozwiązać rzeczy do tej pory nierozwiązywalne. Przede wszystkim sprawnie można było ograniczyć zakres poszukiwanych danych i skupić się tylko na tym co trzeba. Można było ładnie wizualizować i przeglądać to co zostało znalezione. Analitycy dostali w swoje ręce narzędzia, o których wcześniej się nie śniło.
JPL to niejedyne miejsce wykorzystujące Big Data w New Space
Zaczynając artykuł byłem przekonany, że zajmie on tylko kawałeczek. Teraz, gdy opowiedziałem o wykorzystaniu Big Data w NASA widzę jak bardzo się pomyliłem. Nie chcę rozwijać materiału jeszcze bardziej, dlatego już teraz zapraszam na drugą część;-). Jeśli chcesz dowiedzieć się jak Big Data wykorzystywana jest w innych obszarach New Space – zapisz się na newsletter lub obserwuj RDF na LinkedIn. Zrób to koniecznie i razem twórzmy polską społeczność Big Data!